






第一章 卷积层
1.对全连接层使用平移不变性(核不变)和局部性得到卷积层
2.卷积层将输入和卷积核进行交叉相关(卷积其实是交叉相关的180°翻转),加上偏移后得到输出
3.核矩阵和偏移是可学习的参数(核也在动态更新)
4.核矩阵的大小是超参数
5.全连接层权重会随着输入的变大会变得超级大,卷积不会产生这个问题
(含有全连接层的网络输入数据的大小应该是固定的,这是因为全连接层和前面一层的连接的参数数量需要事先确定,不像卷积核的参数个数就是卷积核大小,前层的图像大小不管怎么变化,卷积核的参数数量也不会改变,但全连接的参数是随前层大小的变化而变的,如果输入图片大小不一样,那么全连接层之前的feature map也不一样,那全连接层的参数数量就不能确定, 所以必须实现固定输入图像的大小。)
6.计算输出的高度核宽度:输出的高度=输入的高度-核的高度+1 输出的宽度=输入的宽度-核的宽度+1
7.输出的高度=向下取整(输入的高度-核的高度+填充的高度+步幅)/步幅 输出的宽度=向下取整(输入的宽度-核的宽度+填充的宽度+步幅)/步幅
8.填充一般设置为核-1 这样能保证输入和输出的大小相等 步幅的选择是因为计算量太大了进行的约束
9.Googlenet核心设计:使用小的卷积核
10.底层可以使用大的卷积核 上边一般还是使用3*3的卷积核
第二章 卷积层中的多输入多输出通道
1.一般多个输入通道,输出通道一般只有一个
2.我们可以有多个三维卷积核,每个核生成一个输出通道CoC1KhKw
3.11的卷积层非常的受欢迎,它不识别空间模式,知识融合通道(是根据卷积核的个数,实现通道的融合)
4.输出通道数是卷积层的超参数(输出通道数等于上一层的卷积核个数)
5.每个输入通道有独立的二维卷积核,所有通道结果相加得到一个输出通道结果
6.每个输出通道有独立的三维卷积核

第三章 池化层
1.池化层分为最大池化和平均池化
2.卷积层对位置非常的敏感(i,j),池化层就是再削弱这种敏感
3.经常在池化层使用一个stride=2,使得输出变小,计算变少
4.为什么池化用的越来越少了?(上边两条是池化层的优点)是因为现在的卷积层一般都是加了一个stride,所以池化的功能减弱了。后续会去数据进行处理(旋转、平移、放大、放小做很多操作)使其不会过拟合,淡化了池化层的作用。


第四章 简单的卷积网络(LeNet)
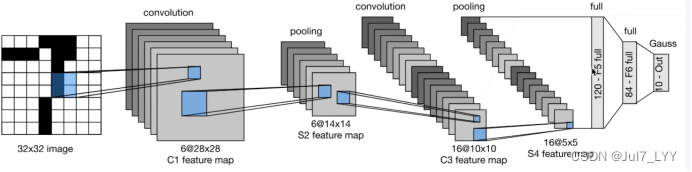

1.view不改变内存存储,reshape改变内存存储方式(两者作用差不多)
2. 一共输出16个通道数据(为什么通道数越来越多呢?这是因为长和宽越来越小,我们希望增加通道数来尽可能保留输入的特征)
3.卷积输出层通道数 = 卷积核的个数 每个核的通道数和初入通道数相同
4.conv2d、conv3d(医学图像、气象、卫星)
AlexNet
一.alexnet与lenet的区别
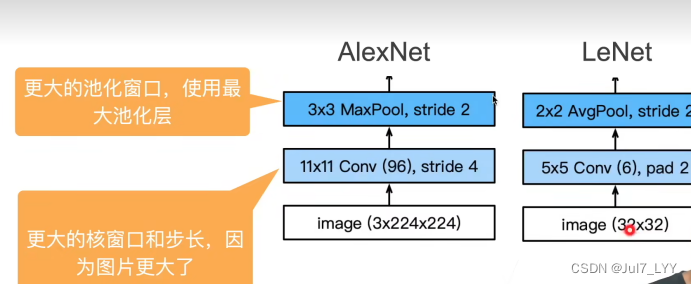
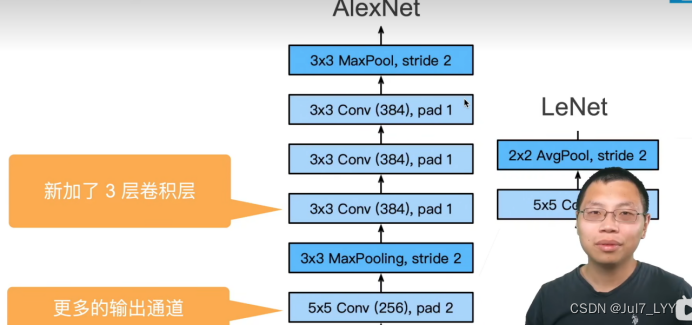
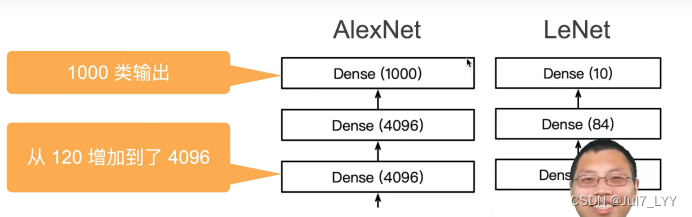
二.主要区别
(1)激活函数从sigmoid变成ReLu(缓解梯度消失)
(2)隐层全连接层后加入了丢弃层
(3)数据增强(图像的随机翻转)
三.详细图解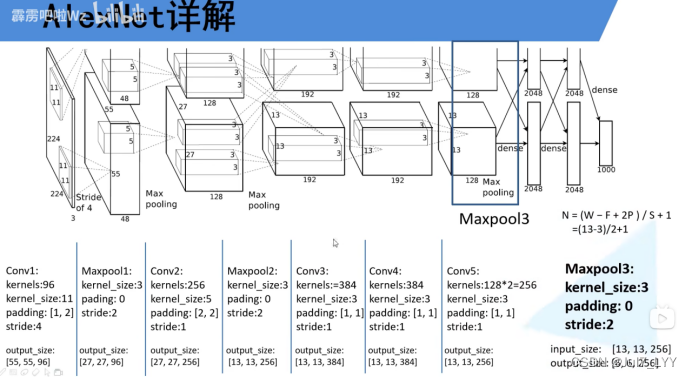
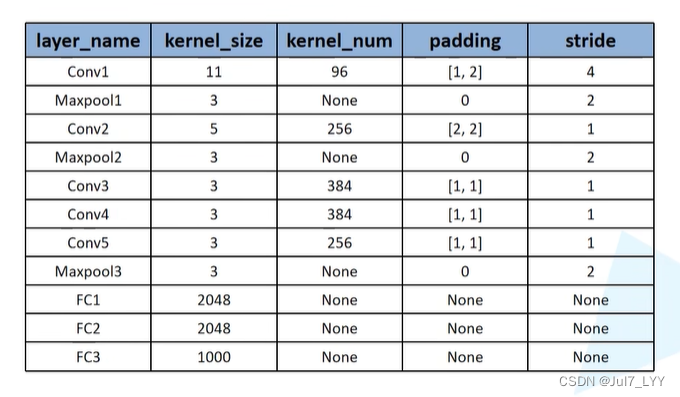

四.一些小问题

1.LRN没有什么用,在后续的网络中就没有再使用过了

2.必须是两个,砍掉一个效果会变差

3.这个resize不会直接把图像变得非常的小,它会先把图片进行等比缩减,在中间扣一块出来或者抠几块,所以不会效果很差。
四.代码中注意的细节
1.x = torch.flatten(x, start_dim=1) # 这里的意思是说从channel这个维度开始展平,batch是不去动它的
2.transforms.RandomHorizontalFlip(), # 随机翻转,是数据增强的内容
3.cla_dict = dict((val, key) for key, val in flower_list.items()) # 这里进行一个翻转,是为了在最后得到结果时比较方便
4.# 使用net.train()和net.eval()来管理dropout在训练的时候失活一部分神经元,在测试的时候不失活
5.with torch.no_grad(): # 禁止pytorch对数据的跟踪 ,在验证过程中是不会进行梯度的更新的
6.img = torch.unsqueeze(img, dim=0) # 扩充一个维度,因为读入的图片只有高度宽度channel三个维度,需要再添加一个batch维度
1.vgg引言
alexnet比lenet更深更大?能带来更好的精度?能不能更深更大?
(1)更多的全连接层【太贵】(2)更多的卷积层(3)讲卷积层组合成块
2.vgg
(1)vgg16包括3个全连接+13个卷积层
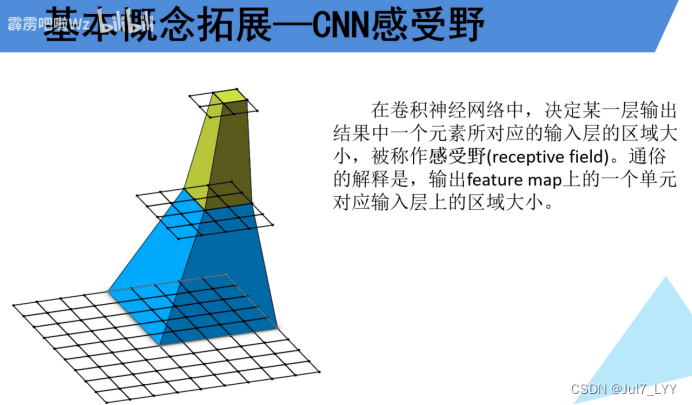
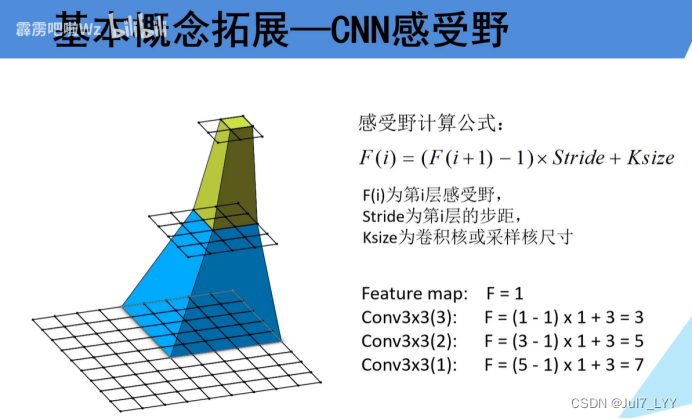
(2)CNN感受野计算公式:F(i)=(F(i+1)-1)stride+ksize【概念公式看下方】
(3)亮点:通过堆叠三个33卷积核来代替5*5卷积核需要的参数【减少参数】
(4)Vgg16网络分为两部分:1.卷积池化:提取特征网络结构 2.全连接层:分类网络结构
(5)num_workers是线程数的意思(win一般默认为0)
(6)卷积层参数个数计算方法:卷积核高 * 卷积核宽 * 输入通道数 * 卷积核个数
当前全连接层参数个数计算方法: (上一层神经元个数 + 1) * 当前层神经元个数
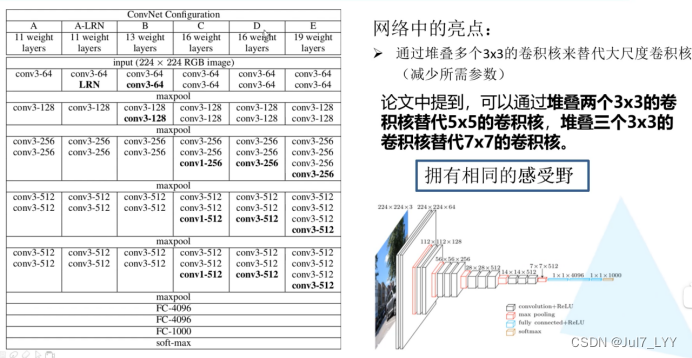

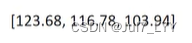
注意:
在很多代码中在预处理的阶段会在rgb上减去这三个值,这三个值分别对应这imgnet图像数据集的所有图片的rgb三个通道的均值。
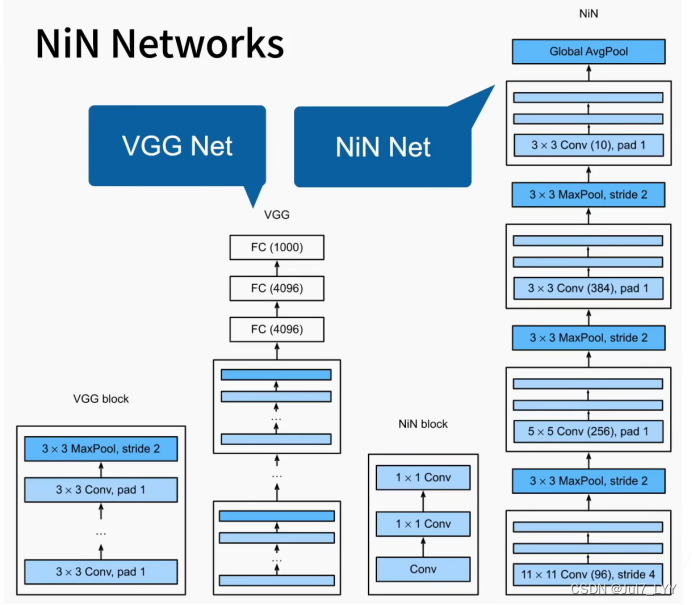
3.NIN引言
全连接层会引起参数非常的多,参数多带来的问题【基本上所有的参数都在全连接层】
(1)占用很大内存(2)占用很大的带宽(3)很容易过拟合
4.NIN
(1)NIN直接不要全连接层【使用1*1的卷积代替】(2)这里的全连接是对像素进行的全连接
(3)全局平均池化层带来的好处和坏处:
好处:
模型复杂度降低了;提升了泛化性;
坏处:
收敛变慢了(alexnet和vgg收敛的快是因为两个全连接层);多扫两三遍数据无所谓,精度好;

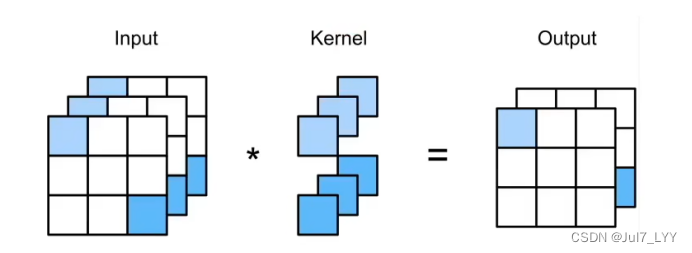

注意:
全局池化层的含义是:池化层的高宽是等于输入的高宽的
















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











