






RCNN
一、RCNN系列简介
R-CNN系列(R-CNN,fast-RCNN,faster-RCNN)是使用深度学习进行物体检测的鼻祖论文,其中fast-RCNN 以及faster-RCNN都是延续R-CNN的思路。
R-CNN新提出了CNN卷积特征提取方法和微调。
R-CNN全称region with CNN features,其实它的名字就是一个很好的解释。用CNN提取出Region Proposals中的featues,然后进行SVM分类与bbox的回归(定位置)。
【RCNN网络结构】
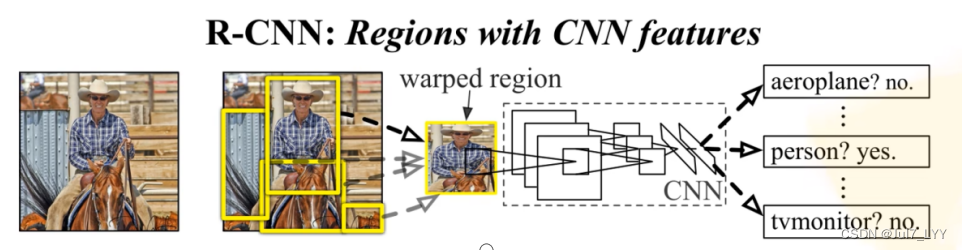

二、RCNN算法流程的4个步骤
重要思想:
(1)通过专门模板去生成候选框(RPN),寻找前景以及调整边界框(基于锚框)
(2)基于之前生成的候选框进行进一步分类以及调整边界框(基于建议框)
具体步骤:
1.一张图像生成1k~2k个候选区域(使用Selective Search方法)
2.对每个候选区域,使用深度网络提取特征(CNN)
3.特征送入每一类的SVM分类器,判别是否属于该类(SVM)
4.使用回归器精细修正候选框位置
步骤详解:


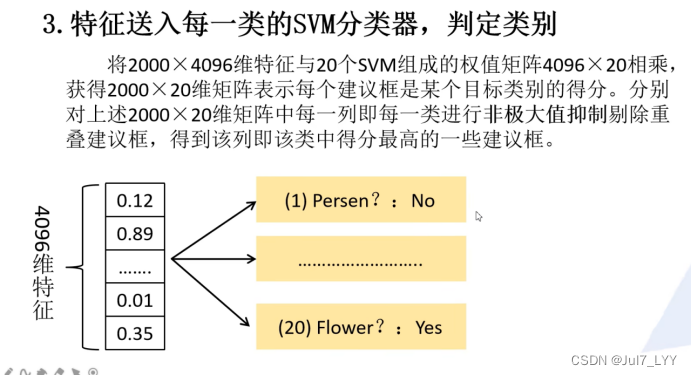
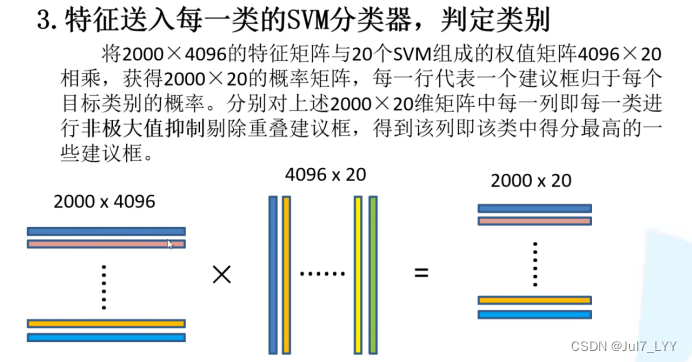
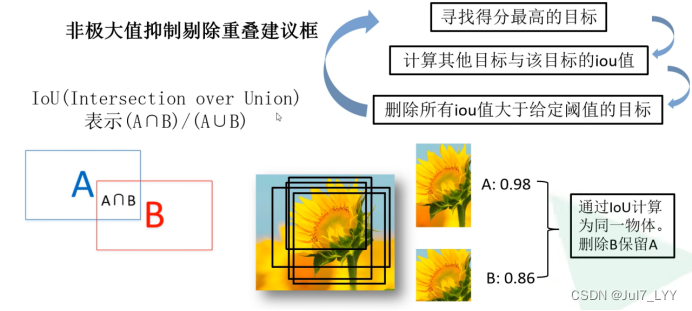

三、RCNN存在的问题
1.测试速度慢
2.训练速度慢(过程复杂,cnn、svm、回归网络都要训练)
3.训练所需空间大

四、论文解析补充
1.R-CNN提出了两个问题
1.如何用CNN定位目标
2.标注数据太少,使用迁移学习的思想(微调)
关于迁移学习(微调):什么是微调?
图像分类:Image:Net 目标检测:PASCAL VOC
2.重要结论
1.在选择图片的时候,会选择比区域大16个像素的图片,这样边缘信息也会利用上。在卷积的时候信息可能丢失。实验证明扩充16个像素 效果会更好
2.最后分类会多出来一类,这一类代表的是背景类。
3.CNN和SVM使用不同的正负样本划分方法。类别分类器使用0.3的阈值
4.可视化学习的特征:高层提取的特征高层每一个不同的通道,学习的就是不一样的东西。eg:1学的是人,2学的是点状
5.R-CNNBB(Bounding box regression)边界框回归
这是RCNN定准确定位的关键,定位正确的位置什么是R-CNNbb?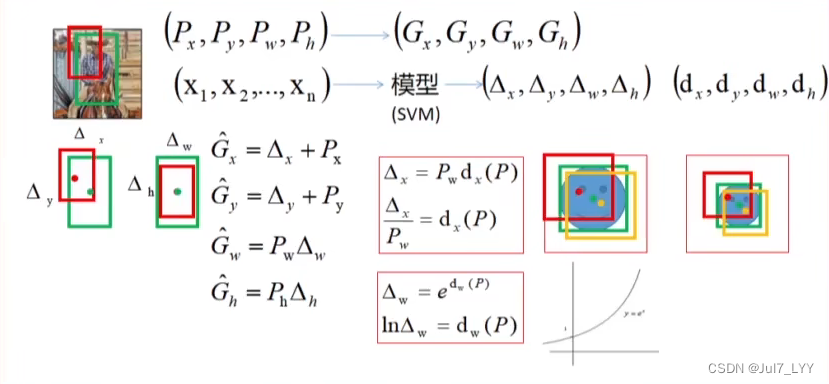
6.这里的△x,△y…都是通过训练SVM模型实现回归任务得到的。
上述公式预测的是△x,△w,而作者预测的是dx,dw,这是为什么?
1.因为△w是宽放大的比例,这里只可能为正数,但是通过svm模型预测出来的可能存在负数。通过先预测出来dw (也可能是正负),那么通过exp的函数一定是正数即可保证△w为正数。
2.如下图所示,当使用d计算的话,对于两张相同预测和真实之间的损失函数的值相同。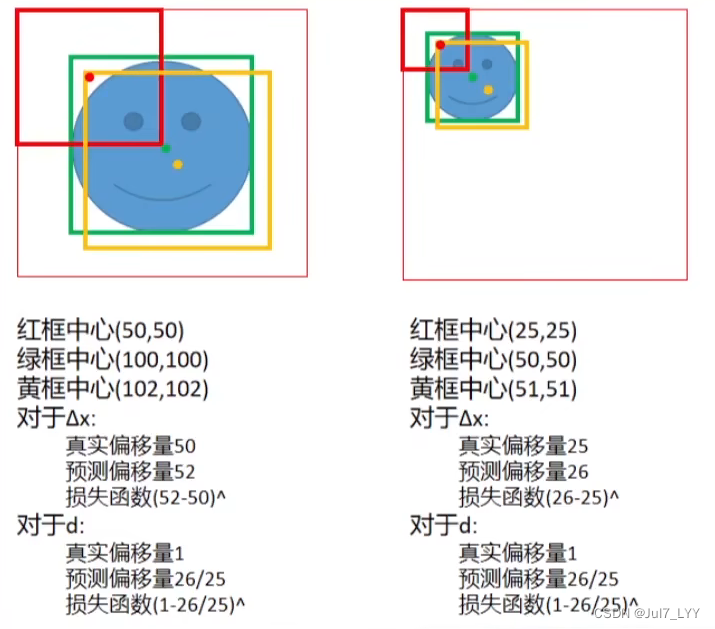
















 1414
1414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











