







熵
英文:entropy
熵是一个物理学概念,它表示一个系统的额不确定性程度,或者说是一个系统的混乱程度。
信息熵
英文:Information entropy
一个叫香农的美国数学家,将熵引入信息论中,并将它命名为:“香农熵”或者“信息熵”。(注意log以什么为底是对结果的比较没有影响,但是不同系统如果要比较混乱程度必须用相同的低比较)
公式:
n:随机变量可能的取值数目(i = 1,2···n)
x:随机变量
P(x):随机变量x的概率函数
例子:
| 宿舍1 | 班花A选择他的概率 | 班花B选择他的概率 |
| 帅哥1 | 0.2 | 0.6 |
| 帅哥2 | 0.2 | 0.1 |
| 帅哥3 | 0.2 | 0.1 |
| 帅哥4 | 0.2 | 0.1 |
| 帅哥5 | 0.2 | 0.1 |
在这个例子中:
- 对于班花A n = 5,
计算班花A的信息熵 H(A) = -(0.2lg(0.2)+0.2lg(0.2)+0.2lg(0.2)+0.2lg(0.2)) = 0.699
- 对于班花B n = 5,
,
计算班花B的信息熵 H(B) = -(0.6lg(0.6)+0.1lg(0.1)+0.1lg(0.1)+0.1lg(0.1)) = 0.53308
根据结果可以知道H(A) > H(B)也就是说A的系统是更混乱的,也就是A的内心是更加纠结的。
相对熵(KL散度)
英文:relative entropy(Kullback-Leibler divergence)
两个概率分布间差异的非对称性度量(用来衡量同一个随机变量的两个不同分布之间的距离)
公式:
特性1(非对称性):
- P和Q的概率分布完全一样时候才会相等
特性2(非负性):
恒大于等于0
- P和Q的概率分布完全一样才相等0
对KL散度的公式进行变形之后会发现KL散度就等于交叉熵减去信息熵
交叉熵
英文:cross entropy
公式:
交叉熵是信息论中的一个重要概念,用来衡量两个概率分布之间的差异性信息。
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。
例子:
| 第一次预测 | 要预测的分类 | 模型预测值(Q(x)) | 真实标签值(P(x)) | 预测正确? |
| 篮球 | 0.7 | 1 | 正确 | |
| 足球 | 0.1 | 0 | ||
| 排球 | 0.2 | 0 | ||
| H(P,Q) = -(1*log(0.7))-(0*log(0.1))-(0*log(0.2))=0.1549 | ||||
| 第二次预测 | 要预测的分类 | 模型预测值(Q(x)) | 真实标签值(P(x)) | 预测正确? |
| 篮球 | 0.3 | 1 | 错误 | |
| 足球 | 0.6 | 0 | ||
| 排球 | 0.1 | 0 | ||
| H(P,Q) =0.5229 | ||||
| 第三次预测 | 要预测的分类 | 模型预测值(Q(x)) | 真实标签值(P(x)) | 预测正确? |
| 篮球 | 0.1 | 0 | 正确 | |
| 足球 | 0.1 | 0 | ||
| 排球 | 0.8 | 1 | ||
| H(P,Q) =0.0969 | ||||
通过这三个例子我们了解到预测越准确交叉熵越小,交叉熵只是跟真实标签的预测概率值有关系。
交叉熵最简化公式:通过上面我们发现其实真实标签的只有一个概率为1,其他的都是0,也就是说只需要计算真实标签为1的那个项。所以我们可以简化交叉熵公式为只计算真实标签为1的那个项。
softmax函数
softmax函数是将数字转换成概率的神器,能够进行数据归一化。
公式
例子:
有三个数=3,
=1,
=-3 那么
经过softmax函数之,
,
注意三个加一起是等于1的。
sigmoid函数(logistics)
公式:
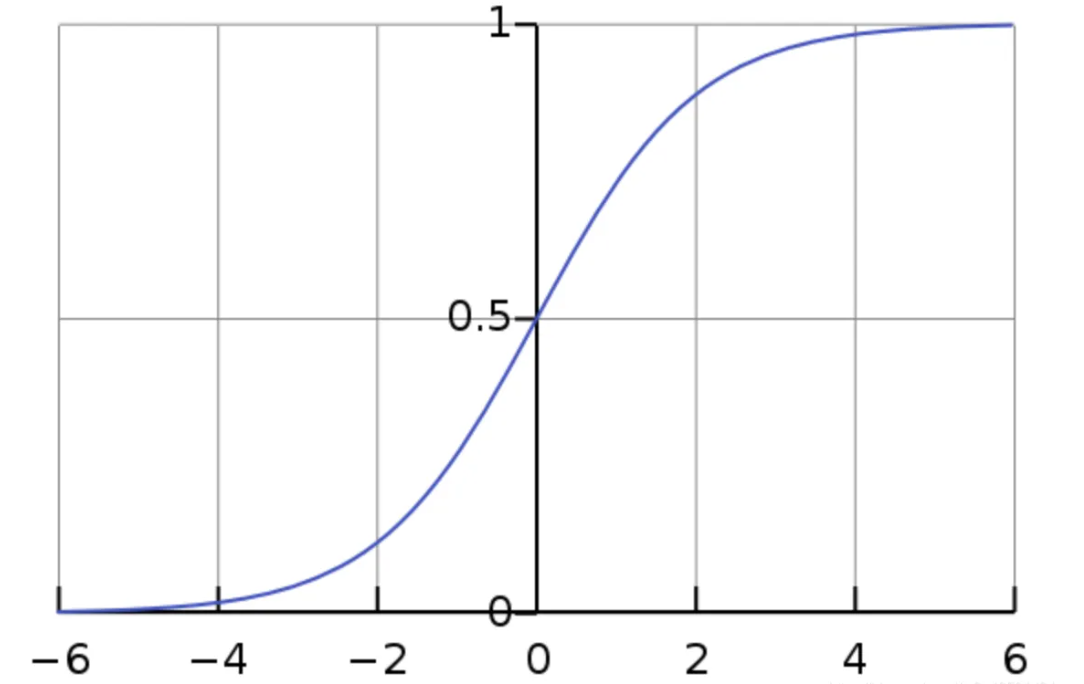
用处:常用为二分类问题的激活函数(激活函数的本质是向神经网络中引入非线性因素的,通过激活函数,神经网络就可以拟合各种曲线。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,引入非线性函数作为激活函数,那输出不再是输入的线性组合,可以逼近任意函数)
声明:这篇文章是看的一个叫 iter008 的up主后总结的,如有侵权,联系删除。














 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









