







目录
4. Net performance on flower datasets
1. shufflenet 介绍
shufflenet的亮点:分组卷积 + 通道重排
mobilenet 提出的深度可分离卷积分为两个step,第一步是深度卷积DW,也就是每一个channel都用一个单独的卷积核卷积,输出一张对应的特征图。第二步是点卷积PW,就是用1*1的卷积核对DW的结果进行通道融合
这样的做法可以有效的减少计算量,然而这样的方式对性能是有一定影响的。而后面的mobilenet 2,3是在bottleneck里面扩充了维度或者更新了激活函数防止维度丢失等等。所以,mobilenet都是在维度信息进行操作的,为了不丢失manifold of interest
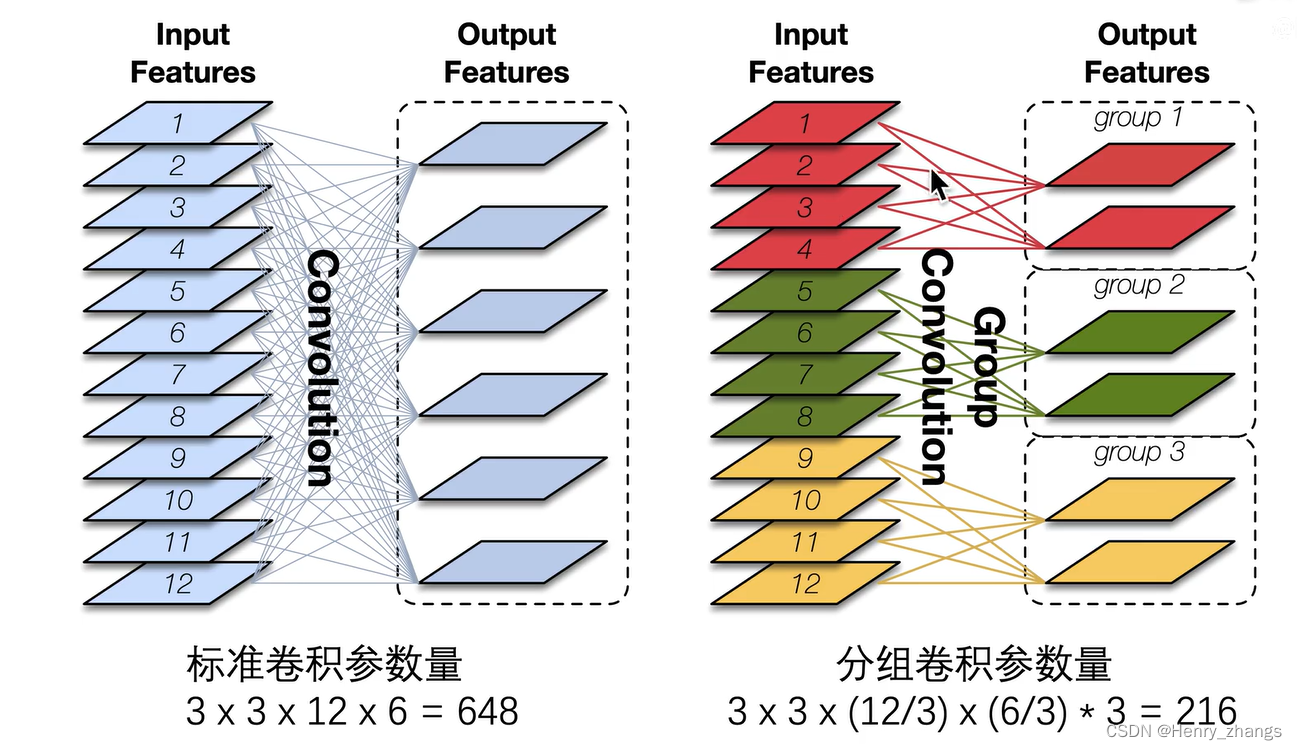
分组卷积
而shufflenet 提出了一个新的思路,正常的卷积是卷积的深度=输入的channel个数。深度可分离卷积是卷积对单个channel进行响应。而shufflenet 取折中,将固定个数的channel作为一组,然后进行正常的卷积
类似于单个样本(mobilenet),batch(正常卷积),mini batch(shufflenet)
过程如下:这样相对于正常的卷积也是大大减少了参数
然而仅仅的分组卷积会落入一个类似近亲繁衍的bug中,如图中的a。这样红色的channel始终和红色的操作,失去了特征的多样性,不同channel信息之间的传递被堵塞了
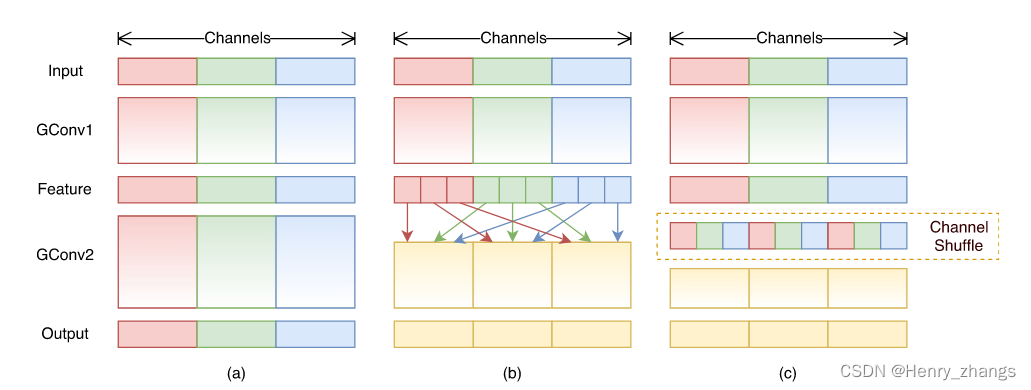
通道重排
而解决这样的方法就是通道重排,例如上图中的b,将不同组分为相同的子块,然后按照顺序打乱。图c和图b是一样的
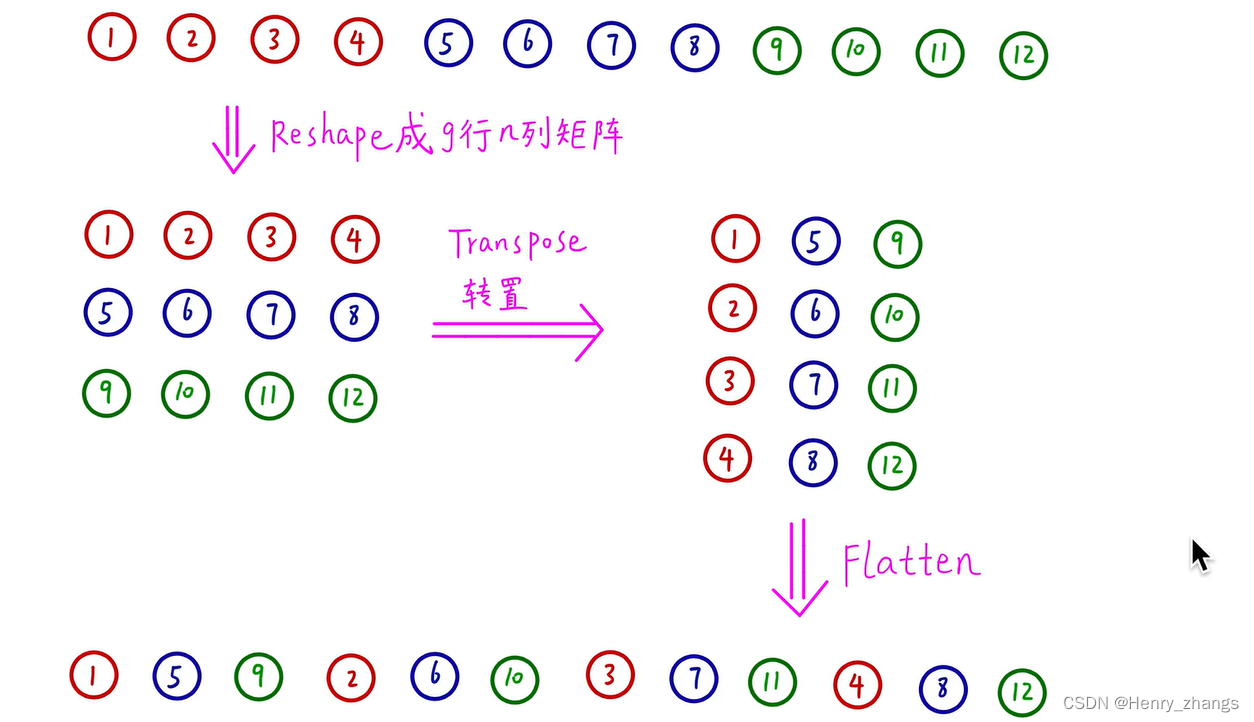
而通道重排可以用矩阵转置的方式实现:
- 将channel放置如下
- 然后按照不同的组(g为分组的个数),reshape 成(g,n)的矩阵
- 将矩阵转置变成n*g的矩阵
- 最后flatten 拉平就行了
2. ShuffleNet V1 网络
搭建shufflenet 网络
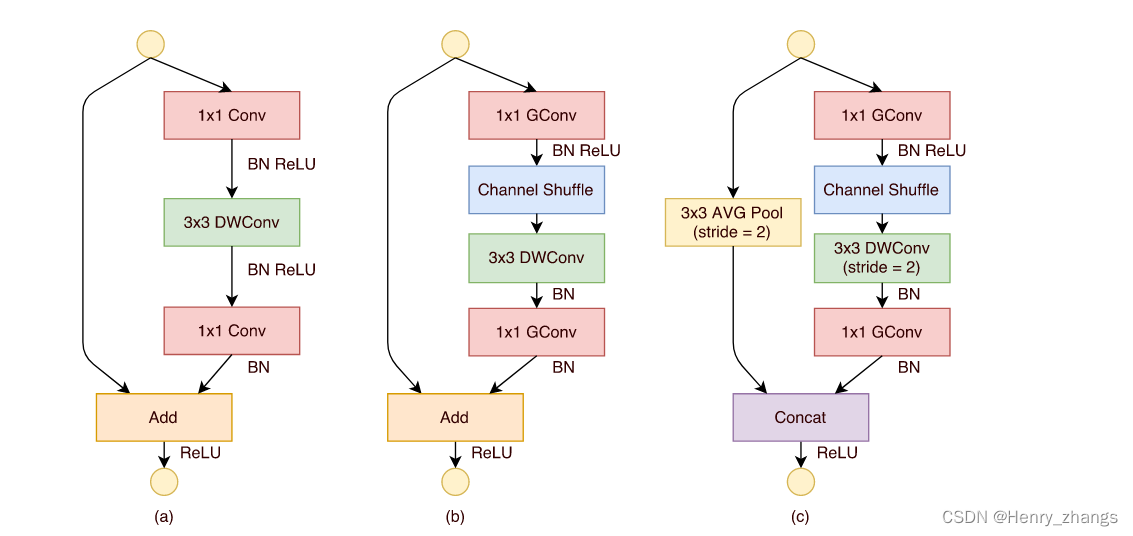
2.1 shufflenet 的结构
shufflenet 中 bottleneck 如下所示
其中,a为正常的bottleneck块,也就是residual残差块
图b和图c全都是为shufflenet中的bottleneck,区别就是c是做下采样的bottleneck。
注:一般的bottleneck的下采样是用卷积核stride=2或者maxpooling实现的,而shufflenet中采用3*3平均池化,stride=2实现
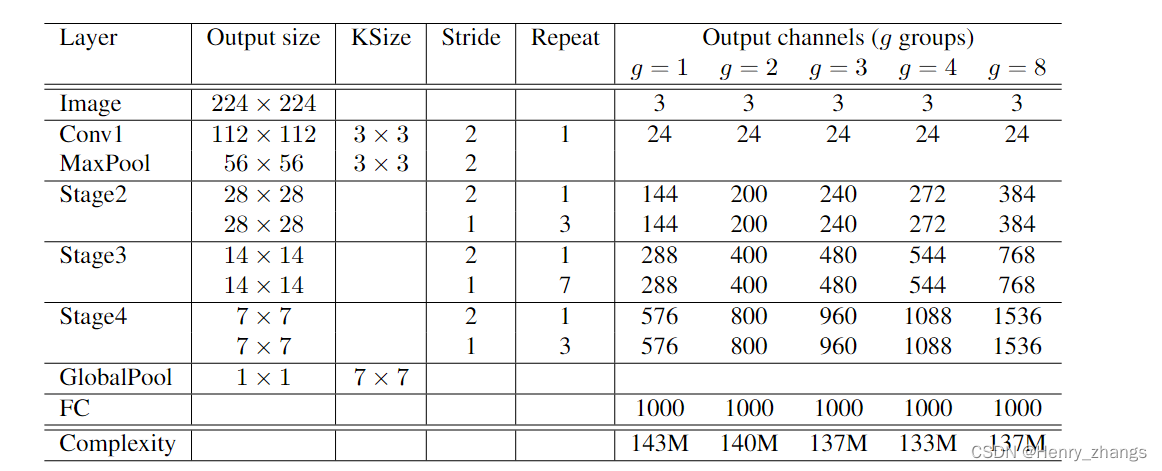
下图为shufflenet V1的网络结构
2.2 代码解释
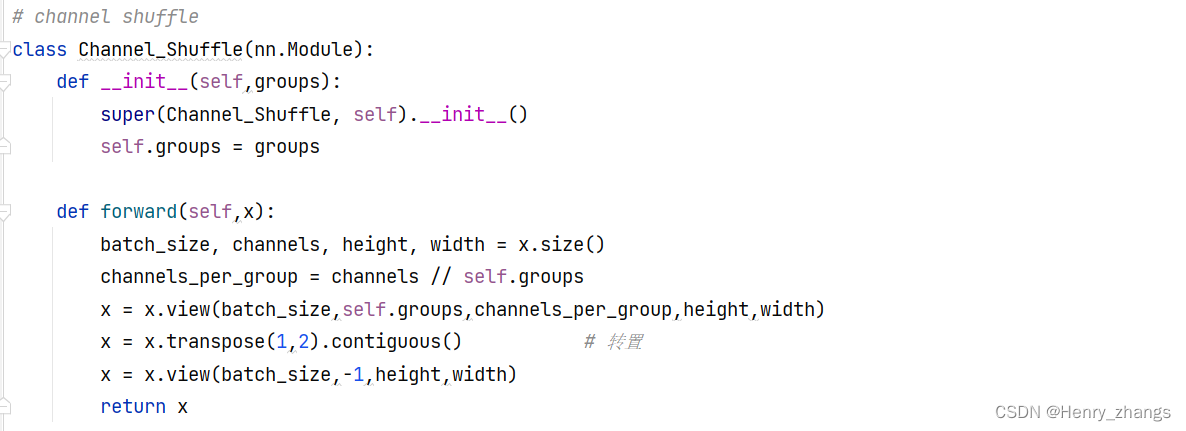
如下定义了一个channel shuffle 的类,因为pytorch中的传递方式是batch*channel*height*width
所以,这里先将x分解成各个部分,然后channel / group 就是每个组里面channel的个数,按照之前提到的方式。显示reshape成g * n的矩阵,然后进行转置,在flatten就行了
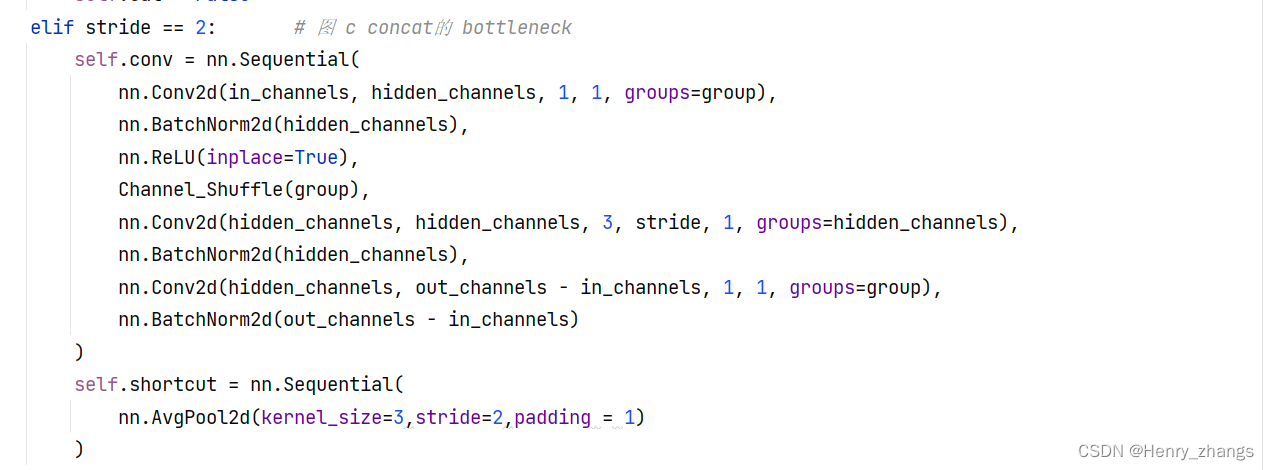
然后针对于stage中的第一步stride = 2,和上图c对应实现
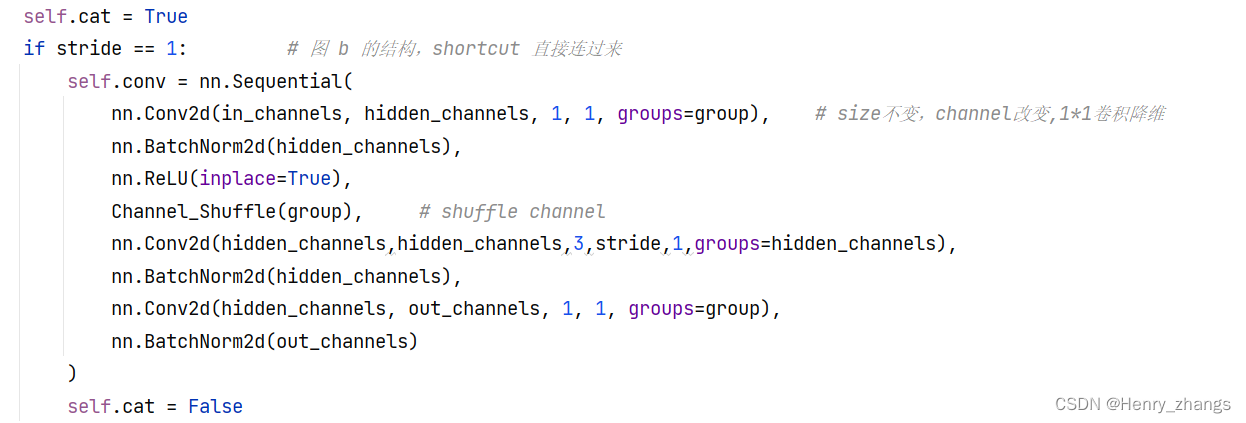
针对于stage中的第一步stride = 1,和上图b对应实现
具体的参考结构,可以慢慢理解,代码实现的方法还是很nice的
2.3 shufflenet 代码
代码:
import torch
import torch.nn as nn
# channel shuffle
class Channel_Shuffle(nn.Module):
def __init__(self,groups):
super(Channel_Shuffle, self).__init__()
self.groups = groups
def forward(self,x):
batch_size, channels, height, width = x.size()
channels_per_group = channels // self.groups
x = x.view(batch_size,self.groups,channels_per_group,height,width)
x = x.transpose(1,2).contiguous() # 转置
x = x.view(batch_size,-1,height,width)
return x
# bottleneck 模块
class BLOCK(nn.Module):
def __init__(self,in_channels,out_channels, stride,group):
super(BLOCK, self).__init__()
hidden_channels = out_channels // 2 # 降维
self.shortcut = nn.Sequential()
self.cat = True
if stride == 1: # 图 b 的结构,shortcut 直接连过来
self.conv = nn.Sequential(
nn.Conv2d(in_channels, hidden_channels, 1, 1, groups=group), # size不变,channel改变,1*1卷积降维
nn.BatchNorm2d(hidden_channels),
nn.ReLU(inplace=True),
Channel_Shuffle(group), # shuffle channel
nn.Conv2d(hidden_channels,hidden_channels,3,stride,1,groups=hidden_channels),
nn.BatchNorm2d(hidden_channels),
nn.Conv2d(hidden_channels, out_channels, 1, 1, groups=group),
nn.BatchNorm2d(out_channels)
)
self.cat = False
elif stride == 2: # 图 c concat的 bottleneck
self.conv = nn.Sequential(
nn.Conv2d(in_channels, hidden_channels, 1, 1, groups=group),
nn.BatchNorm2d(hidden_channels),
nn.ReLU(inplace=True),
Channel_Shuffle(group),
nn.Conv2d(hidden_channels, hidden_channels, 3, stride, 1, groups=hidden_channels),
nn.BatchNorm2d(hidden_channels),
nn.Conv2d(hidden_channels, out_channels - in_channels, 1, 1, groups=group),
nn.BatchNorm2d(out_channels - in_channels)
)
self.shortcut = nn.Sequential(
nn.AvgPool2d(kernel_size=3,stride=2,padding = 1)
)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
out = self.conv(x)
x = self.shortcut(x)
if self.cat:
x = torch.cat([out,x],1) # 图 c的 concat
else:
x = out+x # 图 b的 add
return self.relu(x)
# shuffleNet V1
class ShuffleNet_V1(nn.Module):
def __init__(self, classes=1000,group=3):
super(ShuffleNet_V1, self).__init__()
setting = {1:[3,24,144,288,576], # 不同分组个数对应的channel
2:[3,24,200,400,800],
3:[3,24,240,480,960],
4:[3,24,272,544,1088],
8:[3,24,384,768,1536]}
repeat = [3,7,3] # stage 里面 bottleneck 重复的次数
channels = setting[group]
self.conv1 = nn.Sequential( # Conv1 没有组卷积,channel太少了,输出只有24
nn.Conv2d(channels[0],channels[1],kernel_size=3,stride=2,padding=1), # 输出图像大小 112*112
nn.BatchNorm2d(channels[1]),
nn.ReLU(inplace=True)
)
self.pool1 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # 输出图像size 56*56
self.block = BLOCK
self.stages = nn.ModuleList([])
for i,j in enumerate(repeat): # i =0,1,2 j=3,7,3
self.stages.append(self.block(channels[1+i],channels[2+i],stride=2, group=group)) # stage 中第一个block,对应图 c
for _ in range(j):
self.stages.append(self.block(channels[2+i], channels[2+i], stride=1, group=group)) # stage 中第二个block,对应图 b
self.pool2 = nn.AdaptiveAvgPool2d(1) # global pooling
self.fc = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(channels[-1],classes)
)
# 初始化权重
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros_(m.bias)
def forward(self,x):
x = self.conv1(x)
x = self.pool1(x)
for stage in self.stages:
x = stage(x)
x = self.pool2(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x
3. train 训练
代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from model import ShuffleNet_V1
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from tqdm import tqdm
import json
# 定义超参数
DEVICE = 'cuda' if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 0.001
EPOCHS = 10
BATCH_SIZE = 16
TRAINSET_PATH = './flower_data/train' # 训练集
TESTSET_PATH = './flower_data/test' # 测试集
# 预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"test": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 加载训练集
trainSet = ImageFolder(root=TRAINSET_PATH,transform=data_transform['train'])
trainLoader = DataLoader(trainSet,batch_size=BATCH_SIZE,shuffle=True)
# 加载测试集
testSet = ImageFolder(root=TESTSET_PATH,transform=data_transform['test'])
testLoader = DataLoader(testSet,batch_size=BATCH_SIZE,shuffle=False)
# 数据的个数
num_train = len(trainSet) # 3306
num_test = len(testSet) # 364
# 保存数据的label文件
dataSetClasses = trainSet.class_to_idx
class_dict = dict((val, key) for key, val in dataSetClasses.items())
json_str = json.dumps(class_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 实例化网络
net = ShuffleNet_V1(classes=5)
net.to(DEVICE)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(),lr=LEARNING_RATE,weight_decay=4e-5)
# train
best_acc = 0.0
for epoch in range(EPOCHS):
net.train() # train 模式
running_loss = 0.0
for images, labels in tqdm(trainLoader):
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad() # 梯度下降
outputs = net(images) # 前向传播
loss = loss_fn(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 梯度更新
running_loss += loss.item()
net.eval() # 测试模式
acc = 0.0
with torch.no_grad():
for x, y in tqdm(testLoader):
x, y = x.to(DEVICE), y.to(DEVICE)
outputs = net(x)
predicted = torch.max(outputs, dim=1)[1]
acc += (predicted == y).sum().item()
accurate = acc / num_test # 计算正确率
train_loss = running_loss / num_train # 计算损失
print('[epoch %d] train_loss: %.3f accuracy: %.3f' %
(epoch + 1, train_loss, accurate))
if accurate > best_acc:
best_acc = accurate
torch.save(net.state_dict(), './ShuffleNet_V1.pth')
print('Finished Training....')
这里训练的数据是花数据集,共有五个类别,这里只训练了10个epoch。
100%|██████████| 207/207 [01:34<00:00, 2.19it/s]
100%|██████████| 23/23 [00:05<00:00, 4.09it/s]
[epoch 1] train_loss: 0.089 accuracy: 0.527
100%|██████████| 207/207 [01:45<00:00, 1.97it/s]
100%|██████████| 23/23 [00:05<00:00, 3.84it/s]
[epoch 2] train_loss: 0.076 accuracy: 0.610
100%|██████████| 207/207 [02:03<00:00, 1.68it/s]
100%|██████████| 23/23 [00:05<00:00, 3.89it/s]
[epoch 3] train_loss: 0.067 accuracy: 0.665
100%|██████████| 207/207 [02:42<00:00, 1.28it/s]
100%|██████████| 23/23 [00:07<00:00, 3.26it/s]
0%| | 0/207 [00:00<?, ?it/s][epoch 4] train_loss: 0.061 accuracy: 0.651
100%|██████████| 207/207 [02:47<00:00, 1.23it/s]
100%|██████████| 23/23 [00:07<00:00, 3.27it/s]
[epoch 5] train_loss: 0.058 accuracy: 0.731
100%|██████████| 207/207 [01:54<00:00, 1.81it/s]
100%|██████████| 23/23 [00:06<00:00, 3.60it/s]
[epoch 6] train_loss: 0.055 accuracy: 0.777
100%|██████████| 207/207 [01:53<00:00, 1.83it/s]
100%|██████████| 23/23 [00:06<00:00, 3.46it/s]
[epoch 7] train_loss: 0.053 accuracy: 0.739
100%|██████████| 207/207 [01:52<00:00, 1.84it/s]
100%|██████████| 23/23 [00:06<00:00, 3.57it/s]
[epoch 8] train_loss: 0.051 accuracy: 0.734
100%|██████████| 207/207 [01:53<00:00, 1.83it/s]
100%|██████████| 23/23 [00:06<00:00, 3.52it/s]
[epoch 9] train_loss: 0.048 accuracy: 0.758
100%|██████████| 207/207 [01:53<00:00, 1.82it/s]
100%|██████████| 23/23 [00:06<00:00, 3.56it/s]
[epoch 10] train_loss: 0.045 accuracy: 0.761
Finished Training....
4. Net performance on flower datasets
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import json
import torch
import numpy as np
import matplotlib.pyplot as plt
from model import ShuffleNet_V1
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
# 获取 label
try:
json_file = open('./class_indices.json', 'r')
classes = json.load(json_file)
except Exception as e:
print(e)
# 预处理
transformer = transforms.Compose([transforms.Resize(256), # 保证比例不变,短边变为256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])
# 加载模型
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = ShuffleNet_V1(classes=5)
model.load_state_dict(torch.load('./ShuffleNet_V1.pth'))
model.to(DEVICE)
# 加载数据
testSet = ImageFolder(root='./flower_data/test',transform=transformer)
testLoader = DataLoader(testSet, batch_size=12, shuffle=True)
# 获取一批数据
imgs, labels = next(iter(testLoader))
imgs = imgs.to(DEVICE)
# show
with torch.no_grad():
model.eval()
prediction = model(imgs) # 预测
prediction = torch.max(prediction, dim=1)[1]
prediction = prediction.data.cpu().numpy()
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs, labels)):
x = np.transpose(img.data.cpu().numpy(), (1, 2, 0)) # 图像
x[:, :, 0] = x[:, :, 0] * 0.229 + 0.485 # 去 normalization
x[:, :, 1] = x[:, :, 1] * 0.224 + 0.456 # 去 normalization
x[:, :, 2] = x[:, :, 2] * 0.255 + 0.406 # 去 normalization
y = label.numpy().item() # label
plt.subplot(3, 4, i + 1)
plt.axis(False)
plt.imshow(x)
plt.title('R:{},P:{}'.format(classes[str(y)], classes[str(prediction[i])]))
plt.show()结果如下:

















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











