







 超级会员免费看
超级会员免费看
 本文详细介绍了YOLOv5训练代码的参数,包括weights、cfg、data、hyp等关键参数,涵盖了训练周期、批量大小、图像尺寸、超参数优化等方面,帮助读者理解和设置YOLOv5的训练过程。
本文详细介绍了YOLOv5训练代码的参数,包括weights、cfg、data、hyp等关键参数,涵盖了训练周期、批量大小、图像尺寸、超参数优化等方面,帮助读者理解和设置YOLOv5的训练过程。
1、前言
本章将介绍YOLOv5项目训练代码的参数,关于YOLOv5项目的环境配置和推理代码参数详细介绍可以参考之前的文章
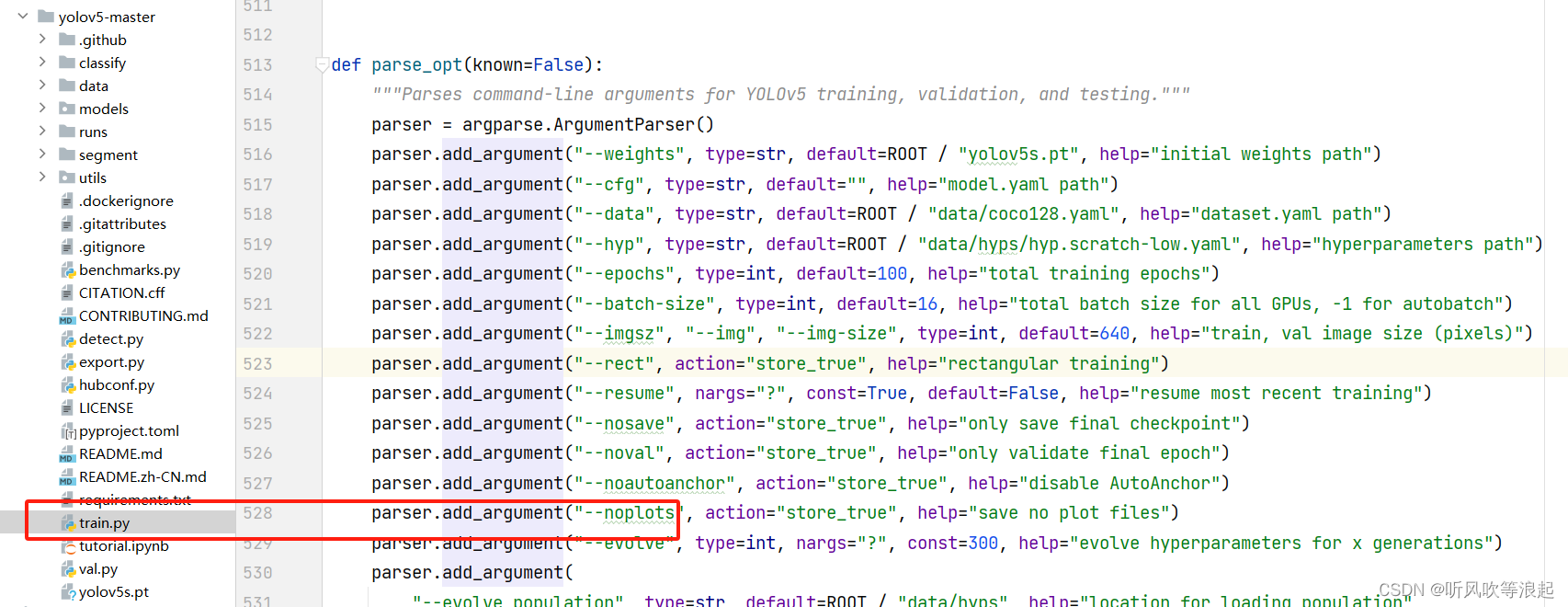
pycharm 打开YOLOv5项目,训练代码如下图的红框所示
2、训练参数
yolov5 训练脚本的训练参数如下
"""Parses command-line arguments for YOLOv5 training, validation, and testing."""
parser = argparse.ArgumentParser()
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")
parser.add_argument("--rect", action="store_true", help="rectangular training")
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")
parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")
parser.add_argument("--noval", action="store_true", help="only validate final epoch")
parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")
parser.add_argument("--noplots", action="store_true", help="save no plot files")
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")
parser.add_argument(
"--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population"
)
parser.add_argument("--resume_evolve", type=str, default=None, help="resume evolve from last generation")
parser.add_argument("--bucket", type=str, default="", help="gsutil bucket")
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk")
parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training")
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%")
parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class")
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer")
parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode")
parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)")
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")
parser.add_argument("--name", default="exp", help="save to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--quad", action="store_true", help="quad dataloader")
parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler")
parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon")
parser.add_argument("--patience", type=int, default=100, help="EarlyStopping patience (epochs without improvement)")
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2")
parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)")
parser.add_argument("--seed", type=int, default=0, help="Global training seed")
parser.add_argument("--local_rank", type=int, default=-1, help="Automatic DDP Multi-GPU argument, do not modify")
# Logger arguments
parser.add_argument("--entity", default=None, help="Entity")
parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='Upload data, "val" option')
parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval")
parser.add_argument("--artifact_alias", type=str, default="latest", help="Version of dataset artifact to use")
# NDJSON logging
parser.add_argument("--ndjson-console", action="store_true", help="Log ndjson to console")
parser.add_argument("--ndjson-file", action="store_true", help="Log ndjson to file")
3、train 脚本训练超参数详解
这里对train 脚本超参数介绍,其实有部分参数和detect参数类似,可以参考之前的介绍
YOLOv5 项目:推理代码和参数详细介绍(detect)-CSDN博客
需要注意的带有 action = 'store_true' ,理解为布尔类型的参数,默认就是关闭。如果打开的话,直接用python detect.py --save-txt 即可
其他类型的要在后面跟实参,例如python detect.pt --conf-thres 0.5
3.1 weights 权重文件
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")预训练权重的路径,默认的是 yolov5s.pt
如果不使用的话,可使用"–weights" 参数指定一个空字符串:“”,或者将default默认值设置为空字符串:“”;
3.2 cfg 模型文件
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")网络模型的结构文件
注意:
- 如果使用了 weights 预训练权重,这个参数可以使用,代码会自动载入 weights 得到网络模型
- 不使用的话,则必须指定该参数
weights 和 cfg 两者必须要有一个,否则代码会找不到网络的模型结构,即会报错!!!
3.3 data 数据集的配置文件
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")默认的是coco128.yaml 的路径,里面存放数据集的训练集、测试集路径啊,以及检测的类别之类的
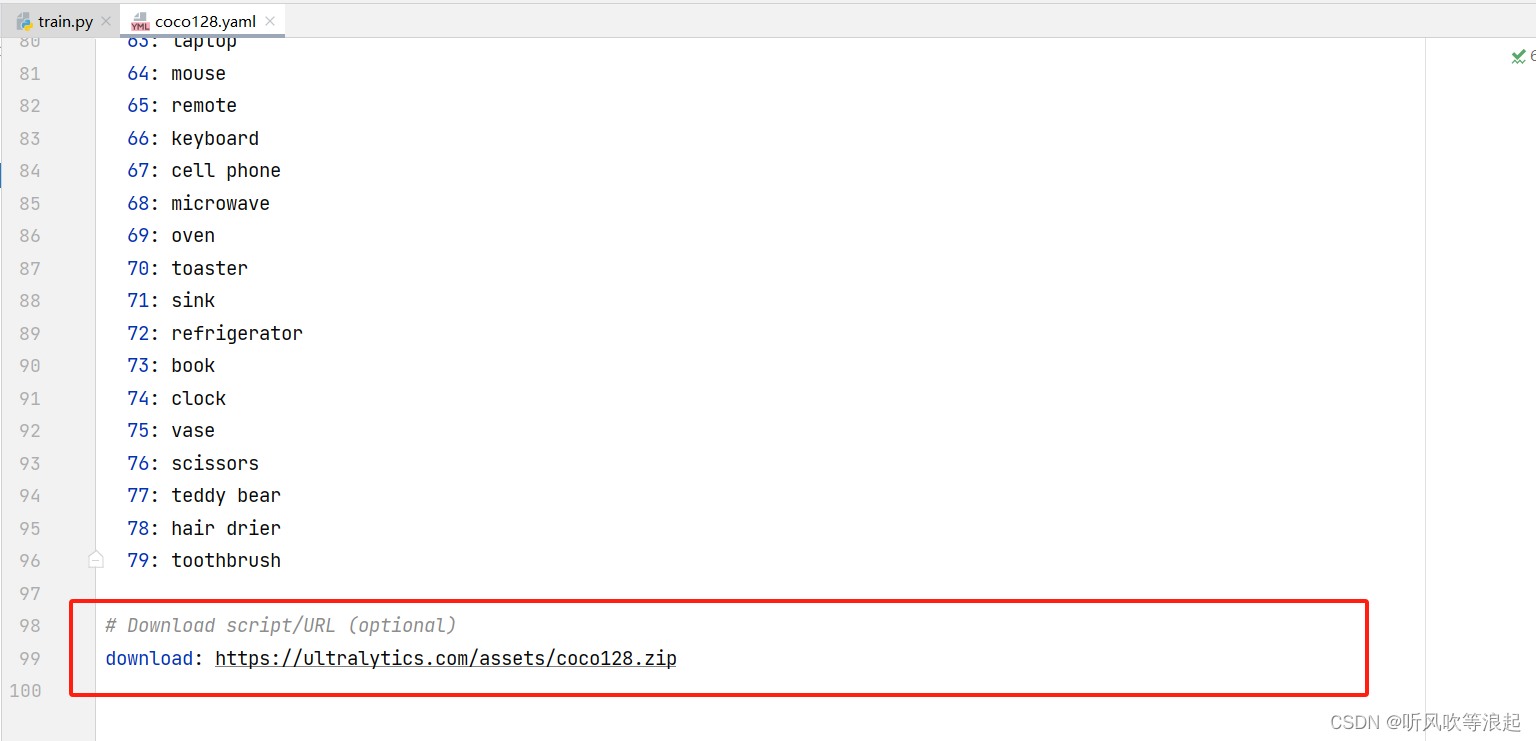
这里默认会下载coco数据集,需要删掉
3.4 hyp 超参数配置文件
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")里面设定训练需要的超参数,例如学习率啊、动量啊、权重衰减啊等等参数设定
3.5 epochs 训练周期
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")这个很简单了,就是迭代训练集多少次,这里默认100
3.6 batch-size
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")这个也很简单,多少个数据算作一个batch
3.7 imgsz,img,img-size 图像的尺寸
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")网络训练和验证的时候,输入图片的尺寸
3.8 rect 矩形训练
parser.add_argument("--rect", action="store_true", help="rectangular training")矩形训练,因为图像尺寸不同,会导致训练时间加长。
开启后会对输入的矩形图片进行预处理,通过保持原图高宽比进行resize后,对resize后的图片进行填充,填充到32的最小整数倍,然后进行矩形训练,减少训练时间。
3.9 resume 断点训练
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")断点续训就是设备中断后,从上一个训练任务中断的地方继续训练
需要注意的是:当模型训练完成,则无法进行断点续训;
需要搭配"–weights" 参数使用,指定训练中断保存的最后一次模型权重文件。
3.10 nosave 保留最后一次权重
parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")默认关闭,开启后只会保留最后的一次权重
3.11 noval 最后一次验证
parser.add_argument("--noval", action="store_true", help="only validate final epoch")开启后,网络只会对最后一个epoch进行验证
3.12 noautoanchor 自动计算锚框
parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")关闭自动计算锚框功能,默认关闭
yolov5采用的是kmeans聚类算法来计算anchor box的大小和比例,最终自动计算出一组最合适训练的锚框。
3.13 noplots 可视化文件
parser.add_argument("--noplots", action="store_true", help="save no plot files")不保存训练过程的可视化文件,默认关闭
3.14 evolve 超参数优化
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")使用超参数优化算法进行自动调参,默认关闭
yolov5采用遗传算法对超参数进行优化,寻找一组最优的训练超参数。开启后传入参数n,训练每迭代n次进行一次超参数进化;开启后不传入参数,则默认为const=300。
3.15 evolve_population 超参数优化的文件
parser.add_argument("--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population")配合上面自动使用,超参数优化的保存位置
3.16 resume_evolve 断点训练+超参数优化
parser.add_argument("--resume_evolve", type=str, default=None, help="resume evolve from last generation")超参数优化会导致参数改变,如果采用断点训练的话,则需要指定参数的路径
3.17 bucket 云盘
parser.add_argument("--bucket", type=str, default="", help="gsutil bucket")从谷歌云盘下载或上传数据
1,该参数用于指定 gsutil bucket 的名称,其中 gsutil 是 Google 提供的一个命令行工具,用于访问 Google Cloud Storage(GCS)服务;
2,GCS 是 Google 提供的一种对象存储服务,用户可以将任意数量和类型的数据存储在其中。用户可以通过 gsutil 命令行工具上传、下载、复制、删除等操作 GCS 中的数据。在训练模型时,如果需要使用 GCS 中的数据集,就需要指定 bucket 的名称。
3.18 cache 缓存数据集
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk")缓存数据集到内存,这样可以加快训练的速度
- cache,可以指定的值:ram/disk;
- cache,参数不指定值,则默认为const=‘ram’。
3.19 image-weights 对数据加权训练
parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training")搭配 rect 参数使用,对数据集的图片进行加权训练
3.20 device 训练设备
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")训练时使用的设备
如果忽略的话,代码会根本环境自动选择,如果有GPU会优先使用
- 设备没有GPU,使用CPU训练------python train.py --device cpu
- 设备有单个GPU,使用单个GPU训练------python train.py --device 0
- 设备有多个GPU,使用单个GPU训练:
python train.py --device 0 (使用第1张GPU训练);
python train.py --device 2 (使用第3张GPU训练);
- 设备有多个GPU,使用多个GPU训练------python train.py --device 0,1,2(使用第1,2,3张GPU训练训练)
3.21 multi-scale多尺度训练
parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%")多尺度训练,这里默认关闭
这个开启的话,对网络的精度会有提升,根据情况选择是否开启
3.22 single-cls 单类别训练
parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class")有多个检测类别时候,只训练指定的目标
3.23 optimizer 优化器选择
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer")默认使用SGD 优化器----->python train.py --optimizer SGD
注意:这里可选择的只有三个‘SGD’, ‘Adam’, ‘AdamW’
3.24 sync-bn 同步批量归一化
parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode")在传统的批归一化(Batch Normalization,简称 BN)中,每个 GPU 会对数据的均值和方差进行单独计算
在多 GPU 训练时,每个 GPU 计算的均值和方差可能会不同,导致模型训练不稳定
为了解决这个问题,SyncBN 技术将 BN 的计算放在了整个分布式训练过程中进行,确保所有 GPU 上计算的均值和方差是一致的,从而提高模型训练的稳定性和效果,但同时也会增加训练时间和硬件要求,因此需要根据具体的训练数据和硬件资源来决定是否使用 SyncBN。
只有在分布式训练(DDP)时才有效
3.25 workers 线程数
parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)")DataLoader中的num_workers参数,默认为8
Dataloader中numworkers表示加载处理数据使用的线程数,使用多线程加载数据时,每个线程会负责加载和处理一批数据,数据加载处理完成后,会送入相应的队列中,最后主线程会从队列中读取数据,并送入GPU中进行模型计算
numworkers为0表示不使用多线程,仅使用主线程进行数据加载和处理。
3.26 project 保存路径
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")和detect 里面的参数一样,即每次训练结果保存的主路径
主路径:每次训练会生成一个单独的子文件夹,主路径就是存放这些单独子文件夹的地方,可以自己命名
例如’runs/train’。比如说第一次训练保存结果的文件夹是exp1,第二次是exp2,第三次是exp3,则这些子文件夹都会放在主路径’runs/train’下面。
3.27 name 子路径
parser.add_argument("--name", default="exp", help="save to project/name")参考 3.26 project 参数介绍,里面的子文件夹
3.28 exist-ok 保存位置是否覆盖
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")默认关闭
每次训练都会生成一个子文件夹,例如exp1,exp2,以此类推
开启的话,新生成的就会直接覆盖之前的训练结果
3.29 quad 数据加载
parser.add_argument("--quad", action="store_true", help="quad dataloader")quad dataloader 是一种数据加载器,它可以并行地从磁盘读取和处理多个图像,并将它们打包成四张图像,从而减少了数据读取和预处理的时间,并提高了数据加载的效率。
3.30 cos-lr 余弦退火学习率衰减策略
parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler")使用cos衰减的学习率
3.31 label-smoothing 标签平滑策略
parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon")标签平滑策略,可以防止过拟合
python train.py --label-smoothing 0.1
表示在每个标签的真实概率上添加一个 epsilon=0.1的噪声,从而使模型对标签的波动更加鲁棒;
具体的值要根据实际网络调整
3.32 patience 提前停止训练
parser.add_argument("--patience", type=int, default=100, help="EarlyStopping patience (epochs without improvement)")patience 参数指定为整数n时,表示模型在训练时,若连续n个epoch验证精度都没有提升,则认为训练已经过拟合,停止训练
3.33 freeze 冻结网络
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2")网络共有10层,迁移学习时,可以冻结一部分参数,只训练后面的层达到加快训练的目的
指定n,冻结前n(0<n<=10)层参数
3.34 save-period 固定周期保留权重
parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)")默认关闭,只保留最好和最后的网络权重
开启后,会根据设定的数值,每隔这个数值的epochs就会保留一次网络权重
3.35 seed 随机种子
保证网络结果的复现
3.36 local_rank 分布式训练
python train.py --local_rank 1,2
这样,第一个进程将使用第 2 号 GPU,第二个进程将使用第 3 号 GPU
注意,如果使用了 --local_rank 参数,那么在启动训练脚本时需要使用 PyTorch 的分布式训练工具,例如 torch.distributed.launch。
3.37 entiy 模型实体
模型实体可以是一个实体名称或实体 ID,通常用于在实体存储库中管理模型的版本控制和记录。
在使用实体存储库时,需要创建一个实体来存储模型,并在训练时指定该实体,这样训练结果就可以与该实体相关联并保存到实体存储库中。
该参数默认值为 None,如果未指定实体,则训练结果将不会与任何实体相关联。
3.38 upload_dataset 上传数据集
默认关闭,不上传数据集
- 如果命令行使用’–upload_dataset’参数,但没有传递参数,则默认值为const=True,表示上传数据集。
- 如果命令行使用’–upload_dataset’参数,并且传递了参数’val’,则默认为True,表示要上传val数据集。
3.39 bbox_interval 记录边框图片
parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval")训练过程中,每隔多少个epoch记录一次带有边界框的图片,类似于训练过程数据的可视化
3.40 artifact_alias 数据集工件版本别名
用于指定要使用的数据集工件的版本别名。
命令行使用方法:python train.py --artifact_alias latest
在使用MLFlow等工具跟踪模型训练和数据集版本时,会给每个版本分配唯一的别名。通过指定此参数,可以使用特定版本的数据集工件。默认情况下,使用最新版本的数据集工件。
3.41 ndjson-console
将ndjson 输出在控制台
3.42 ndjson-file
将ndjson 记录在文件中
4、其他
这里的参数太多了,对于基本的训练大部分基本用不到,后续会自己制作数据,将部分用到的参数进行讲解
YOLOv5 环境配置:YOLOv5 项目:环境配置-CSDN博客
YOLOv5 推理代码输入参数详解:YOLOv5 项目:推理代码和参数详细介绍(detect)-CSDN博客


















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











