







constrastive learning
通过对比数据对的“相似”或“不同”来获取数据的高阶信息。
- Data augmentation
- Encoding
- Loss minimization
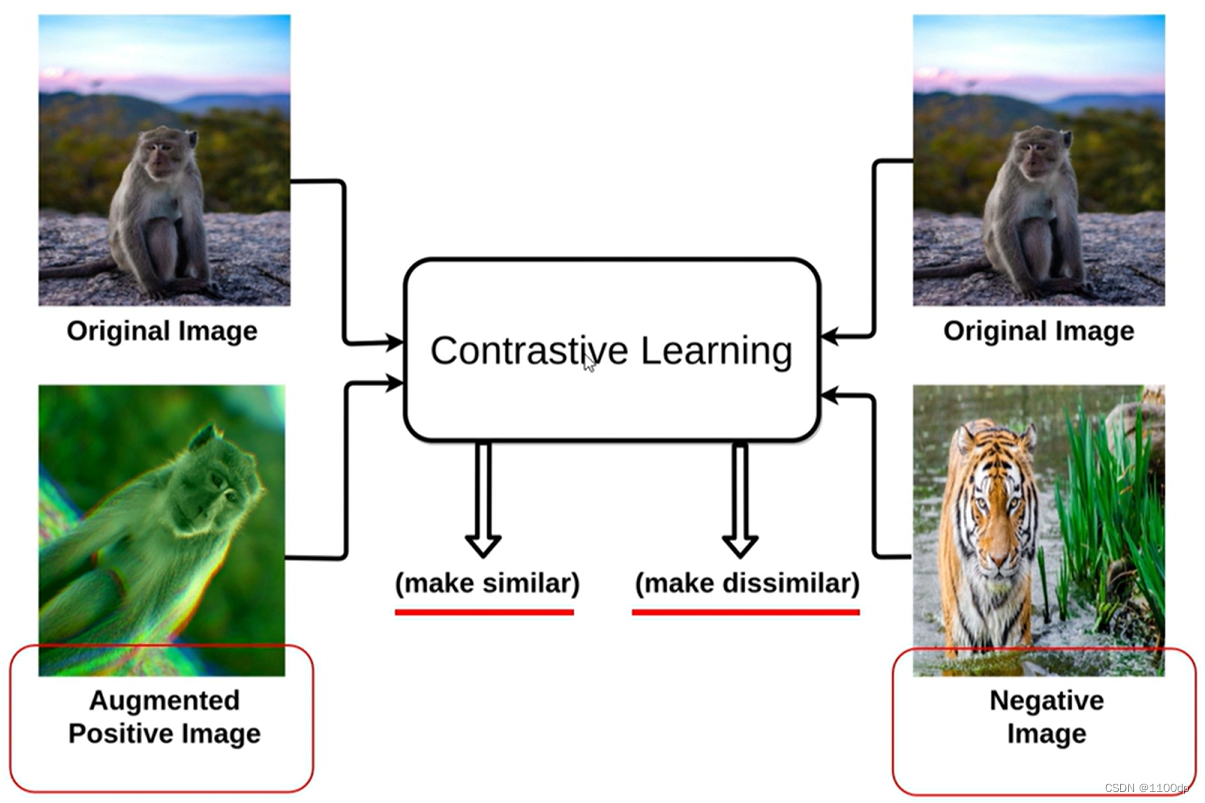
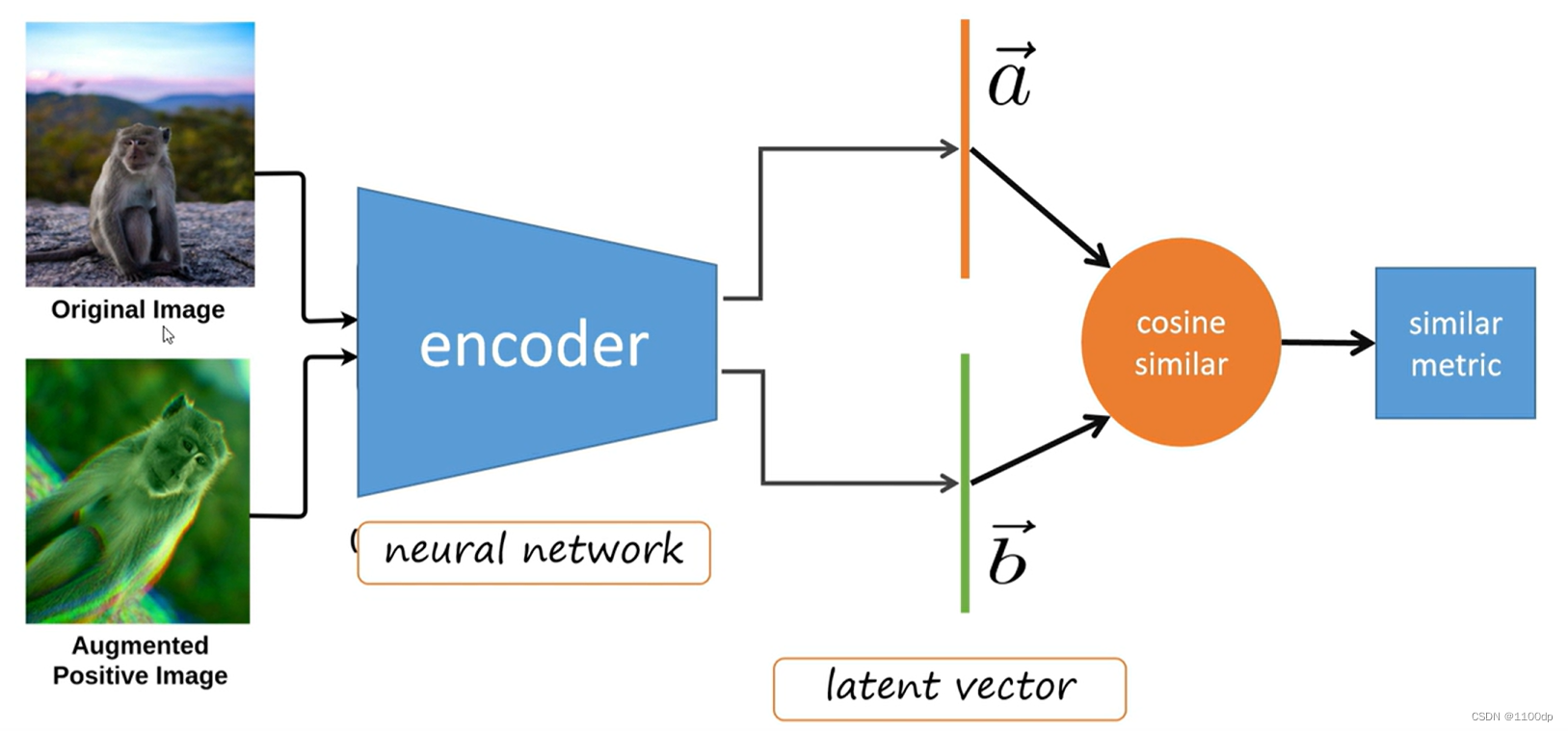

Instance Discrimination
个体判别任务:
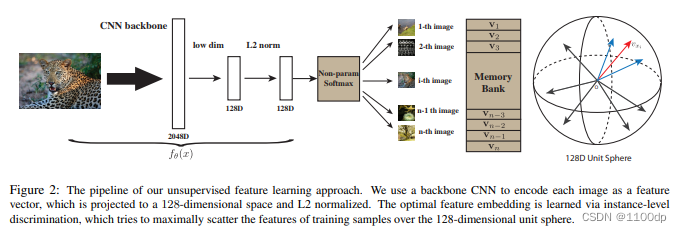
- 一种无监督学习方式,把每一个Instance都看作一个类别。
- 通过一个卷积神经网络,把所有图片都编码成一个特征。并且,希望这些特征在最后的特征空间里能够尽可能分开。对于个体判别任务来说,每个图片都是自己的类。所以每个图片都尽量和其它图片分开。
- Memory Bank: 把所有图片的特征都存到这个memory bank里面。
- 正样本:经过数据增强的图片,负样本:数据集里面的其它图片(从memory bank中随机抽取一些图片作为负样本)。
- 有了正负样本,就可以通过BCELoss去计算对比学习的目标函数。当更新完网络,就可以mini batch中的数据样本所对应的特征替换到memory bank中。接下来,反复进行这个过程。
Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
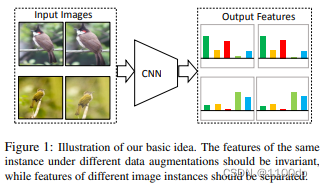
同样的图片通过编码器后,它们的特征应该相似;不同的图片通过编码器后,其特征应该不类似。也就是说:对于相似的图片,相似的物体,其特征应该保持不变性(Invariant);对于不相似的物体,其特征应该尽可能分散(Spreading)开。
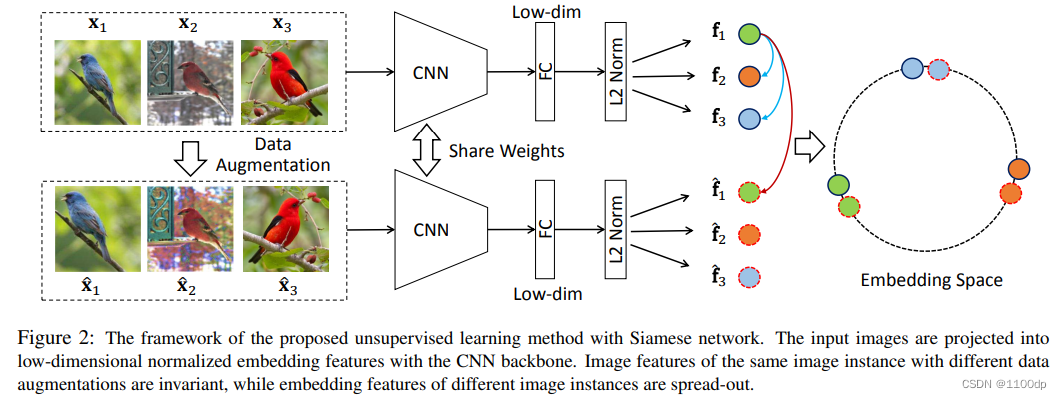
从同一个mini-batch中去选取正负样本,因为这样就可以只用一个编码器去做端对端的训练了。
Contrastive Predictive Coding
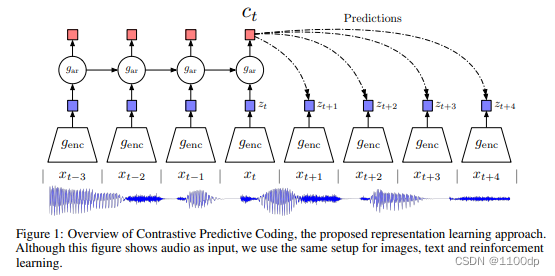
- 有一个持续的序列,把之前时刻的输入放到一个编码器中,这个编码器就会返回一些特征。之后把这些特征放入自回归的模型,然后得到上下文的特征表示。最后,用这些特征表示去做一些合理的预测。
- 正样本为未来的输入通过编码器之后得到的未来时刻的特征输出,负样本:任意选取输入,然后通过编码器得到输出,和预测不相似。


















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











