






 本文介绍了OpenAI的多模态对比学习模型CLIP,该模型通过大量文本-图片对进行预训练,实现了无需监督的图像识别,其性能在某些任务上可与有监督训练的ResNet50媲美。CLIP通过对比学习将图片和文本特征对齐,展示了优秀的泛化能力,适用于各种应用场景,如OCR、情绪识别和图片检索。CLIP的出现标志着计算机视觉与自然语言处理的深度融合,为人工智能的未来发展打开了新的可能。
本文介绍了OpenAI的多模态对比学习模型CLIP,该模型通过大量文本-图片对进行预训练,实现了无需监督的图像识别,其性能在某些任务上可与有监督训练的ResNet50媲美。CLIP通过对比学习将图片和文本特征对齐,展示了优秀的泛化能力,适用于各种应用场景,如OCR、情绪识别和图片检索。CLIP的出现标志着计算机视觉与自然语言处理的深度融合,为人工智能的未来发展打开了新的可能。
2月25月随笔:
最近在关注自动标注领域的工作,发现了一篇有趣的文章:openai的多模态对比学习《基于自然语言监督信号的迁移视觉网络模型》,在imagenet 上zero shot 效果和有监督训练好的ResNet 50媲美(⊙o⊙)
其实从bert 开始,自然语言处理和计算机视觉的结合就势不可挡,之后的各种vision transform 更是如同雨后春笋,但clip 是第一次把图片与文字的结合做到了极致。
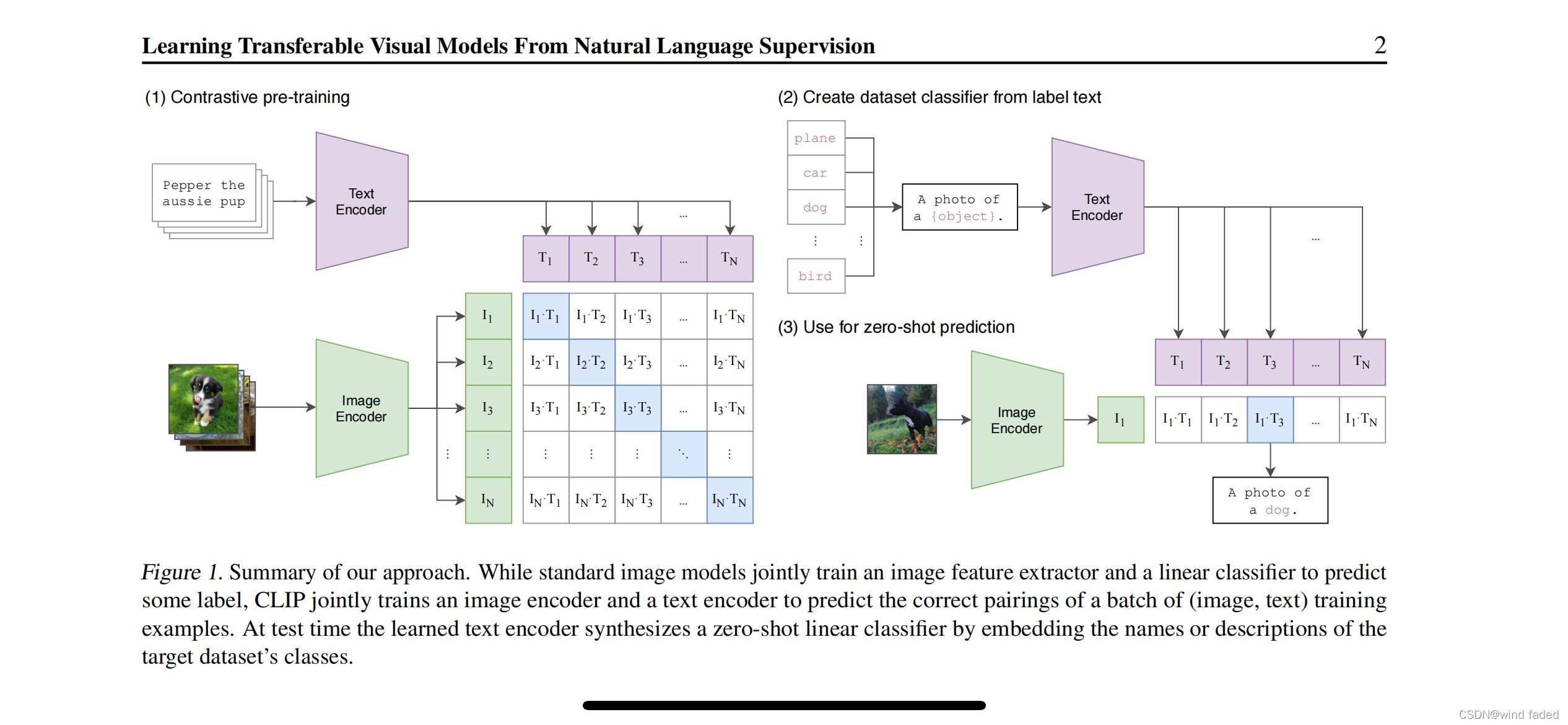
原理简单有效:有n个图片文本对,使用编码器分别提取出n个文本和n个图像特征,clip在这些特征上做对比学习(特征矩阵对角线为正样本)。对于任何新数据集里的任意图片,clip 只需要计算图片特征向量和每一个类别的文本向量的余弦,返回最大值对应的类别即可。

clip说是zero shot ,但通过在预训练阶段提供大量文本-图片对形式的“标签"为模型训练提供了一定的监督(不愧是财大气粗的openai ,直接给整了有4亿个低噪声的图片文本对的超级数据集外加8个tpu 年的训练周期(๑°⌓°๑))不过直接通过自然语言而非绝对标签学习图像内容更符合人类直觉,也和我们自己的学习过程与判别逻辑更相似。所以clip 的泛化性能好得离谱,什么做OCR ,情绪识别或自然语言图片检索都不在话下(ios相册搜索赶紧升级呀)。
到手时间到!
尝试用clip 自带的demo程序做了一个简陋的情绪识别查询(把情绪形容词作为待配对文本信息即可)↘
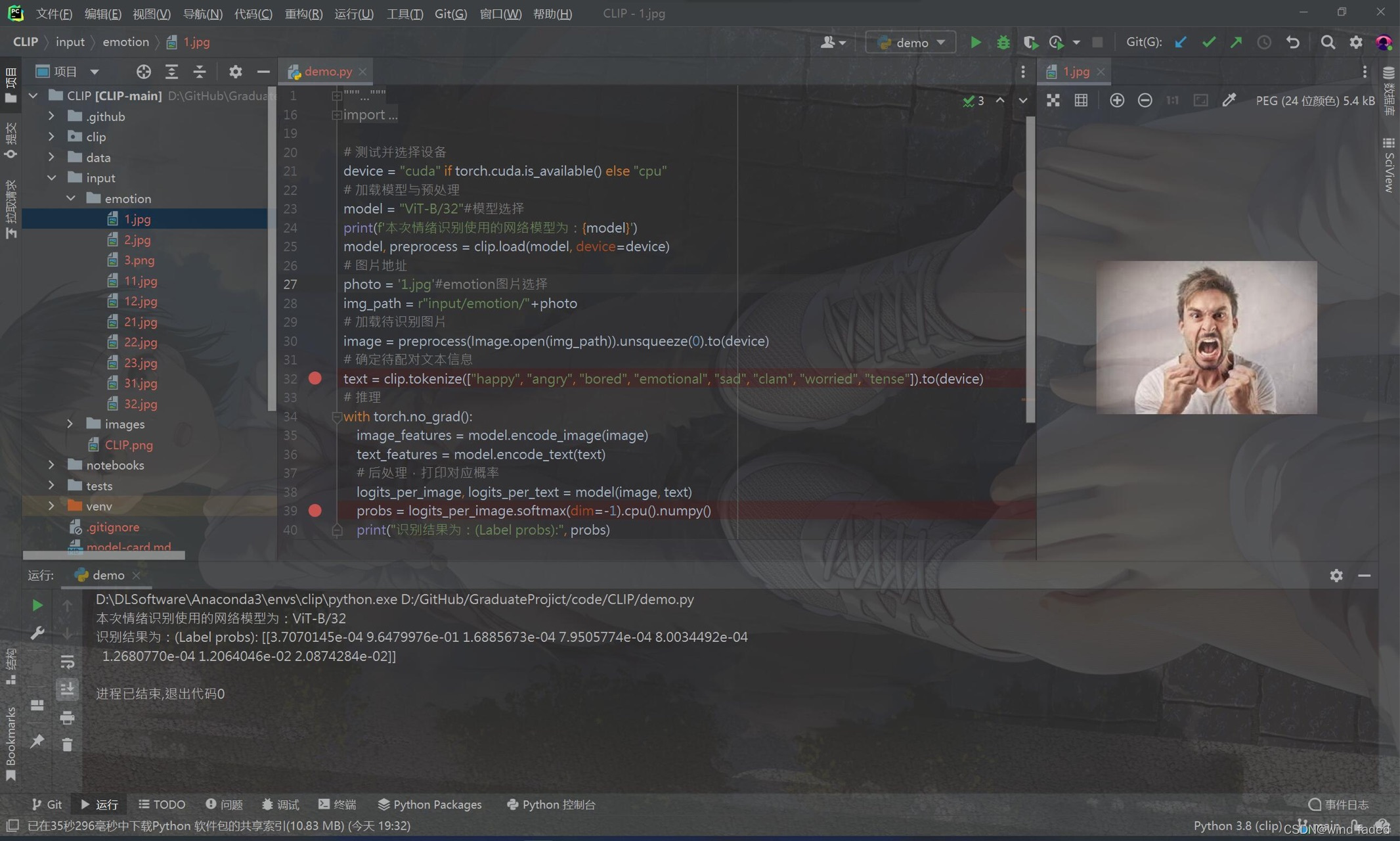
对付一般的现实图片 ,简直绝杀,最大值比其他值高了1到3个数量级
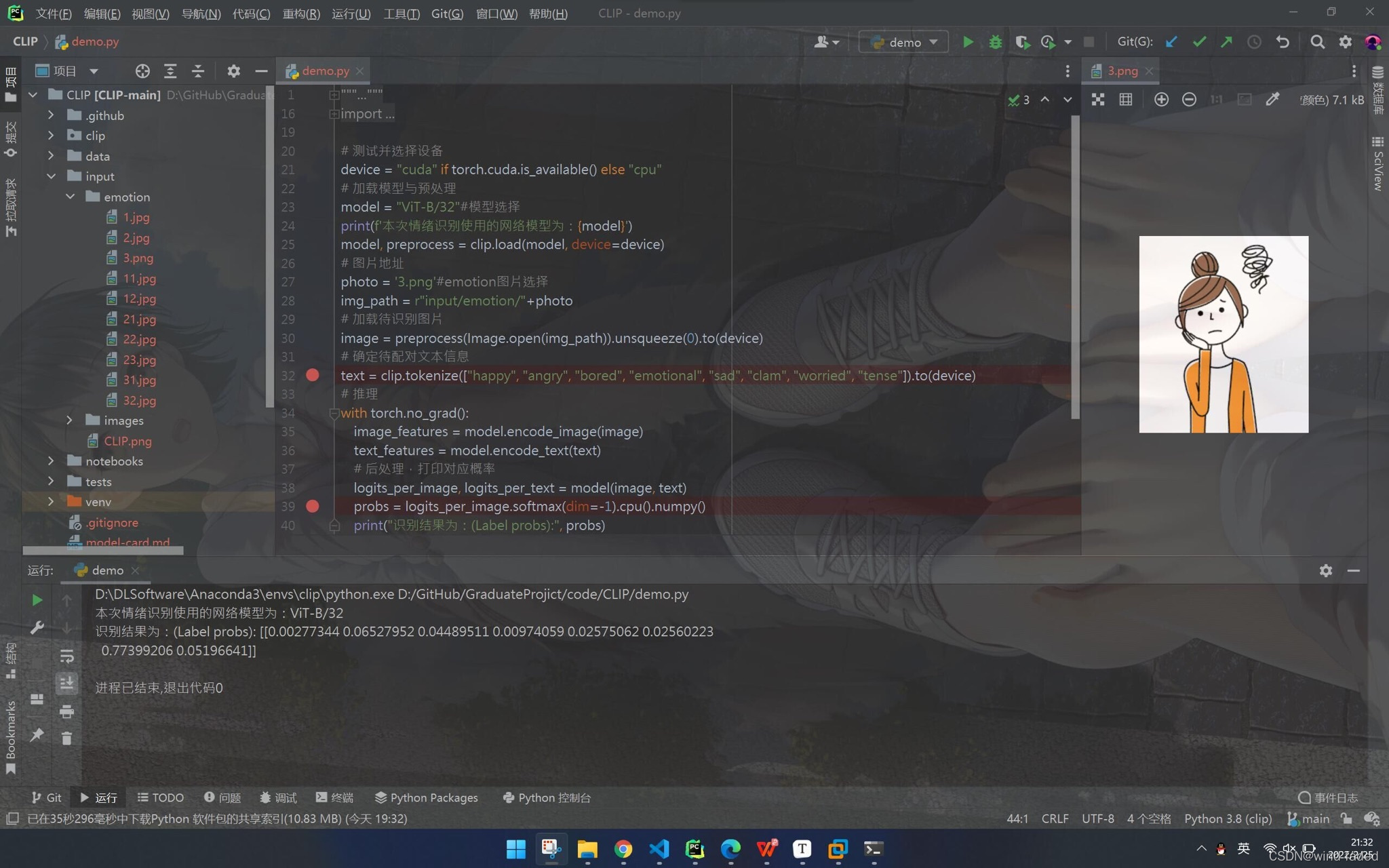
clip 强大之处在于优秀的泛化性能,动画图片也不在话下
cv 与nlp这俩最热门的领域算是打通了计算机读与看的隔阂,有点期待人工智能兼具五感的情形(๑‾ ꇴ ‾๑)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











