







目录
1.寄存器模型概览
1.1 概述
- 对于硬件有了解的读者,都知道寄存器是模块之间互相交谈的窗口
- 一方面可以通过读出寄存器的状态,获取硬件当前的状况,另外一方面也可以通过配置寄存器,使得寄存器工作在一定的模式下。
- 在验证的过程中,寄存器的验证也排在了验证清单的前列,因为只有首先保证寄存器的功能正常,才会使得硬件与硬件之间的交谈是“语义一致”的。
- 如果寄存器配置结果与寄存器配置内容不同,那么硬件无法工作在想要的模式下,同时寄存器也可能无法正确反映硬件的状态。
- 本节我们关于UVM寄存器模型的介绍中,会将MCDF寄存器模块简化,通过硬件的寄存器模型和总线UVC建立一个小的验证环境:
- 寄存器有关的设计流程
- 寄存器模型的相关类。
- 如何将寄存器模型集成到现有环境,与总线UVC桥接,与DUT模型绑定。
- 寄存器模型的常用方法和预定义的sequence。
- 寄存器测试和功能覆盖率的实际用例。
- 硬件中的各个功能模块可以由处理器来配置功能以及状态访问,而与处理器的对话即是通过寄存器的读写来实现的。
- 寄存器硬件实现是通过触发器,而每一个比特位的触发器都对应着寄存器的功能描述(function specification)。
- 一个寄存器一般由32个比特位构成,将单个寄存器拆封之后,又可以分为多个域(field),不同的域往往代表着某一项独立的功能。
- 单个域可能由多个比特位构成,也可能由单一比特位构成,这取决于该域的功能模式可配置的数量。
- 而不同的域,对于外部的读写而言,又大致可以分为WO(write-only,只写),RO(read-only,只读)和RW(read and write,读写),除过这些常见的操作以外,还有一些特殊行为(quieky)的寄存器,例如读后擦除模式(clean-on-read,RC),只写一次模式(write-one-to-set,WIS)。
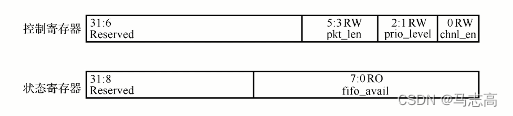
- MCDF的寄存器模块描述,将0X00功能寄存器和0X10状态寄存器位用图来表示。
- 通常来讲,一个寄存器有32位宽,寄存器按照地址索引的关系是按字对齐的(world-align),上图中的寄存器有多个域,每个域的属性也可以不相同,reserved域表示的是该域所包含的比特位暂时保留以作日后功能的扩展使用,而对保留域的读写不起任何作用,即无法写入而且读出值也是它的复位值。
- 上面的这些寄存器按照地址排列,即可构成寄存器列表,我们称之为寄存器块(register block)。
- 实际上,寄存器除了包含寄存器,也可以包含存储器,因为它们的属性都近乎于读写功能,以及表示为同外界通信的接口。
- 我们如果将这些寄存器有机地组合在一起,MCDF的寄存器功能模块即可由这样一个register block来表示:
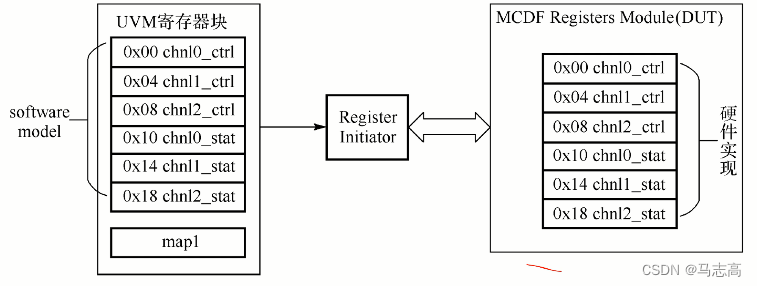
- 一个寄存器可以由多个域构成,而单个域可以包含多个比特位;一个功能模块中的多个寄存器可以组团构成一个寄存器模型(register model)。示图中除了包含DUT的寄存器模块(由硬件实现),还有属于验证环境的寄存器模型。
- 这两个模块包含的寄存器信息的高度一致的,属于验证环境的寄存器模型也可以抽象出一个层次化的寄存器列表,该列表所包含的地址、域、属性等信息都与硬件一侧的寄存器内容一致。
- 对于功能验证而言,可以将总线访问寄存器的方式抽象为寄存器模型访问的方式,这种方式使得寄存器后期的地址修改(例如基地址的更改)或者域的添加都不会对已有的激励构成影响,从而提高已有测试序列的复用性。
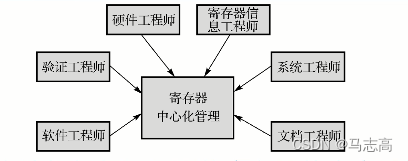
- 通过软件建立寄存器模型的方法如何保证与硬件寄存器的内容属性保持一致呢?这离不开一份中心化管理的寄存器描述文件,很多公司目前在使用XML格式的寄存器描述文件,也有一些公司在使用Excel(CSV)或者DOS等格式来保存寄存器的描述。
- 为什么寄存器描述应该被中心管理呢?因为采用单一源的管理方式可以尽量降低出现分歧和错误可能。
- 寄存器描述文档使用了结构化的文档描述方式,这也是为什么可以通过XML或者Excel(CSV)等数据结构化的方式来实现寄存的功能描述。
- ·通过数据结构化的存储方式,可以在硬件和软件开发过程中以不方式来使用寄存器描述文档:
- 系统工程师会撰写并维护寄存器描述文件,而后归置到中心化存储路径其他工程师开发使用。
- 硬件工程师会利用寄存器描述文件生成寄存器硬件模块(包含各个寄存器硬件实现和总线访问模块)。
- 验证工程师会利用寄存器描述文件来生成UVM寄存器模型,以供验证过程中的激励使用、寄存器测试和功能覆盖率收集。
- 软件工程师会利用该文件生成用于软件开发的寄存器配置的头文件(header file),从而提高软件开发的可维护性。
- 寄存器描述文件也可以用来生成文档,实现更好的可持续性。
- 推荐自动生成寄存器的流程,因为手动转换会有潜在的错误,而且寄存器越多出现错误的可能性越大,这样会使得后期调试的难度更大。
- 除此之外,推荐使用寄存器自动生成器的原因还包括:
- 一个广义的寄存器生成器(register generator),应该依据统一格式的寄存器描述文件,来生成UVM寄存器模型(为验证)。或者硬件寄存器模块(被集成到设计中)。
- 一个稳定的寄存器不但可以保证从文本信息到寄存器模型的无错误转换,还可以在转换过程中通过予以检查发现寄存器描述文件违规的情况帮助修正寄存器描述文件的内容。
- 对于寄存器描述文件内容有更新,寄存器生成器可以再次生成需要的相关文件格式,这对于流程化作业非常方便。
- 对于验证所需的寄存器模型而言,一个更有效的做法是可以通过封装已有的寄存器生成器,使得可以通过指定多个寄存器模块和其他对应基地址,继而生成一个层次化的寄存器模型,从而将系统级的寄存器模块归纳在一起,便于操作管理。
1.2 uvm_reg相关概念
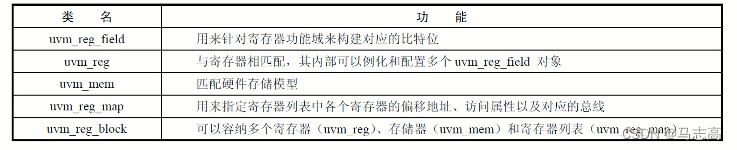
- 在构建UVM寄存器模型的过程中,需要了解与模型构建相关的类和他们的功能:
1.3 MCDF寄存器模型
class ctrl_reg extends uvm_reg;
`uvm_object_utils(ctrl_reg)
uvm_reg_field reserved;
rand uvm_reg_field pkt_len;
rand uvm_reg_field prio_level;
rand uvm_reg_field chnl_en;
function new(string name="ctrl_reg");
super.new(name, 32, UVM_NO_COVERAGE);
endfunction
virtual function build();
reserved = uvm_reg_field::type_id::create("reserved");
pkt_len = uvm_reg_field::type_id::create("pkt_len");
prio_level = uvm_reg_field::type_id::create("prio_level");
chnl_en = uvm_reg_field::type_id::create("chnl_en");
reserved.configure(this, 26, 6, "RO", 0, 26'h0, 1, 0, 0);
pkt_len.configure(this, 3, 3, "RW", 0, 3'h0, 1, 1, 0);
prio_level.configure(this, 2, 1, "RW", 0, 2'h3, 1, 1, 0);
chnl_en.configure(this, 1, 0, "RW", 0, 1'h0, 1, 1, 0);
endfunction
endclass
class stat_reg extends uvm_reg;
`uvm_object_utils(stat_reg)
uvm_reg_field reserved;
rand uvm_reg_field fifo_avail;
function new(string name="stat_reg");
super.new(name, 32, UVM_NO_COVERAGE);
endfunction
virtual function build();
reserved = uvm_reg_field::type_id::create("reserved");
fifo_avail = uvm_reg_field::type_id::create("fifo_avail");
reserved.configure(this, 24, 8, "RO", 0, 24'h0, 1, 0, 0);
fifo_avail.configure(this, 8, 0, "RO", 0, 8'h0, 1, 1, 0);
endfunction
endclass
class mcdf_rgm extends uvm_reg_block;
`uvm_object_utils(mcdf_rgm)
rand ctrl_reg chnl0_ctrl_reg;
rand ctrl_reg chnl1_ctrl_reg;
rand ctrl_reg chnl2_ctrl_reg;
rand ctrl_reg chnl0_stat_reg;
rand ctrl_reg chnl1_stat_reg;
rand ctrl_reg chnl2_stat_reg;
uvm_reg_map map;
function new(string name="mcdf_rgm");
super.new(name, UVM_NO_COVERAGE);
endfunction
virtual function build();
chnl0_ctrl_reg = ctrl_reg::type_id::create("chnl0_ctrl_reg");
chnl0_ctrl_reg.configure(this);
chnl0_ctrl_reg.build();
chnl1_ctrl_reg = ctrl_reg::type_id::create("chnl1_ctrl_reg");
chnl1_ctrl_reg.configure(this);
chnl1_ctrl_reg.build();
chnl2_ctrl_reg = ctrl_reg::type_id::create("chnl2_ctrl_reg");
chnl2_ctrl_reg.configure(this);
chnl2_ctrl_reg.build();
chnl0_stat_reg = ctrl_reg::type_id::create("chnl0_stat_reg");
chnl0_stat_reg.configure(this);
chnl0_stat_reg.build();
chnl1_stat_reg = ctrl_reg::type_id::create("chnl1_stat_reg");
chnl1_stat_reg.configure(this);
chnl1_stat_reg.build();
chnl2_stat_reg = ctrl_reg::type_id::create("chnl2_stat_reg");
chnl2_stat_reg.configure(this);
chnl2_stat_reg.build();
//map name, offset, number of bytes, endianess
map = create_map("map", 'h0, 4, UVM_LITTLE_ENDIAN);
map.add_reg(chnl0_ctrl_reg, 32'h00000000, "RW");
map.add_reg(chnl1_ctrl_reg, 32'h00000004, "RW");
map.add_reg(chnl2_ctrl_reg, 32'h00000008, "RW");
map.add_reg(chnl0_stat_reg, 32'h00000010, "RO");
map.add_reg(chnl1_stat_reg, 32'h00000014, "RO");
map.add_reg(chnl2_stat_reg, 32'h00000018, "RO");
lock_model();
endfunction
endclass
1.4 寄存器建模
- 我们可以整理出关于寄存器建模的基本要点和顺序:
- 在定义单个寄存器时,需要将寄存器的各个域整理出来,在创建之后还应当通过uvm_reg_field::configure()函数来进一步配置各自属性。
- 在定义uvm_reg_block时,读者需要注意reg_block与uvm_mem、uvm_reg以及uvm_reg_map的包含关系。首先uvm_reg和uvm_mem分别对应着硬件中独立的寄存器或者存储,而一个uvm_reg_block可以用来模拟一个功能模块的寄存器模型,其中可以容纳多个uvm_reg和uvm_mem实例;其次map的作用一方面用来表示寄存器和存储对应的偏移地址,同时由于一个reg_block可以包含多个map,各个map可以分别对应不同总线或者不同地址段。在reg_block中创建了各个uvm_reg之后,需要调用uvm_reg::configure()去配置各个uvm_reg实例的属性。
- 考虑到uvm_reg_map也会在uvm_reg_block中例化,在例化之后需要通过uvm_reg_map::add_reg()函数来添加各个uvm_reg对应的偏移地址和访问属性等。只有规定了这些属性,才可以在稍后的前门访问(frontdoor)中给出正确的地址。
- uvm_reg_block可以对更大的系统做寄存器建模,这意味着uvm_reg_block之间也可以存在层次关系,上层uvm)reg_block的uvm_reg_map可以添加子一级uvm_reg_block的uvm_reg_map,用来构建更全面的“版图”,继而通过uvm_reg_block与uvm_reg_map之间的层次关系来构建更系统的寄存器模型。
1.5 模型使用流程
- 那么当拥有一个寄存器模型之后,它接下来的使用步骤是什么呢?实际上对于不同的角色,它们对寄存器模型有着不同的关注,譬如VIP开发者主要关注实现总线适配器,TB开发者关心如何将总线适配器与寄存器模型连接。
- 不管对于什么角色,寄存器模型从一开始的寄存器描述文档最后的功能检查,都需要贯穿寄存器模型的生命周期。
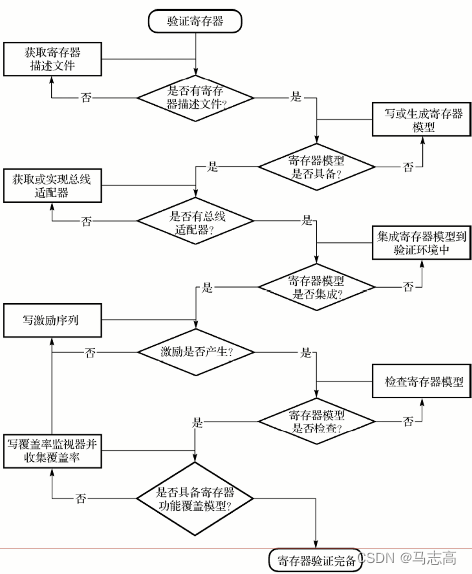
2.寄存器模型集成
2.1 总线UVC的实现
- MCDF访问寄存器的总线接口时序较为简单。控制寄存器接口首先需要在每一个时钟解析cmd。
- 当cmd为写指令时,即需要把数据cmd_data_in写入到cmd_addr对应的寄存器中。
- 当cmd为读指令时,即需要从cmd_addr对应的寄存器中读取数据,在下一个周期,cmd_addr对应的寄存器被输送值cmd_data_out接口。
- 我们给出一段8位地址线,32位数据线的总线UVC实现代码。
2.2 纵向UVC的示例
class mcdf_bus_trans extends vum_sequence_item;
rand bit[1:0] cmd;
rand bit[7:0] addr;
rand bit[31:0] wdata;
bit[3:0] rdata;
`uvm_object_utils_begin(mcdf_bus_trans)
...
`uvm_object_utils_end
...
endclass
class mcdf_bus_sequencer extends uvm_sequencer;
virtual mcdf_if vif;
`uvm_component_utils(mcdf_bus_sequencer)
...
function void build_phase(uvm_phase phase);
if(!uvm_config_db#(virtual mcdf_if)::get(this,"","vif",vif))begin
`uvm_error("GETVIF","no virtula interface is assigned")
end
endfunction
endclass
class mcdf_bus_mointor extends uvm_monitor;
virtual mcdf_if vif;
uvm_analysis_port #(mcdf_bus_trans) ap;
`uvm_component_utils(mcdf_bus_mointor)
...
function void build_phase(uvm_phase phase);
if(!uvm_config_db#(virtual mcdf_if)::get(this,"","vif",vif))begin
`uvm_error("GETVIF","no virtual interface is assigned")
end
ap = new("ap",this);
endfunction
task run_phase(uvm_phase phase);
forever begin
mon_trans();
end
endtask
task mon_trans();
mcdf_bus_trans t;
@(posedge vif.clk);
if(vif.cmd ==`WRITE)begin
t = new();
t.cmd = `WRITE;
t.addr = vif.addr;
t.wdata = vif.wdata;
ap.write(t);
end
else if(vif.cmd == `READ)begin
t = new();
t.cmd = `READ;
t.addr = vif.addr;
fork
begin
@(posedge vif.clk);
#10ps;
t.rdata = vif.rdata;
ap.write(t);
end
join_none
end
endtask
endclass:mcdf_bus_mointor
class mcdf_bus_driver extends uvm_driver;
virtual mcdf_if vif;
`uvm_component_utils(mcdf_bus_driver)
...
function void build_phase(uvm_phase phase);
if(!uvm_config_db#(virtual mcdf_if)::get(this,"","vif",vif))begin
`uvm_error("GETVIF","no virtual interface is assigned")
end
endfunction
task run_phase(uvm_phase phase);
REQ tmp;
mcdf_bus_trans req,rsp;
reset_listener();
forever begin
seq_item_port.get_next_item(tmp);
void'($cast(rsp,req.clone()));
rsp.set_sequence_id(req.get_sequence_id());
drive_bus(rsp);
seq_item_port.item_done(rsp);
`uvm_info("DRV",$sformatf("sent a item \n %s",rsp.sprint()),UVM_LOW)
end
endtask
task reset_listener();
fork
forever begin
@(negedge vif.rstn)drive_idle();
end
join_none
endtask
task driver_bus(mcdf_bus_trans t);
case(t.cmd)
`WRITE: drive_write(t);
`READ: drive_read(t);
`IDLE: drive_idle(1);
default:`uvm_error("DRIVE","invalid mcdf command type received!")
endcase
endtask
task drive_write(mcdf_bus_trans t);
@(posedge vif.clk);
vif.cmd <= t.cmd;
vif.addr <= t.addr;
vif.wdata <= t.wdata;
endtask
task drive_read(mcdf_bus_trans t);
@(posedge vif.clk);
vif.cmd <= t.cmd;
vif.addr <= t.addr;
@(posedge vif.clk);
#10ps;
t.rdata = vif.rdata;
endtask
task drive_idle(bit is_sync = 0);
if(is_sync)@(posedge vif.clk);
vif.cmd <= 'h0;
vif.addr <= 'h0;
vif.wdata <= 'h0;
endtask
endclass
class mcdf_bus_agent extends uvm_agent;
mcdf_bus_driver driver;
mcdf_bus_sequencer sequencer;
mcdf_bus_mointor mointor;
`uvm_componet_utils(mcdf_bus_agent)
...
function void build_phase(uvm_phase phase);
driver = mcdf_bus_driver::type_id::create("driver",this);
sequencer = mcdf_bus_sequencer::type_id::create("sequencer",this);
mointor = mcdf_bus_monitor::type_id::create("mointor",this);
endfunction
function void connect_phase(uvm_phase phase);
driver.seq_item_port.connect(sequencer.seq_item_export);
endfunction
endclass
- 示例囊括了mcdf_bus_agent的所有组件:sequence item、sequencer、driver、monitor和agent。我们对这些代码的部分实现给出解释:
- mcdf_bus_trnas包括了可随机化的数据成员cmd、addr、wdata和不可随机化的rdata。rdata之所以没有声明为rand类型,是应该它应从总线读出或者观察,不应随机化。
- mcdf_bus_monitor会观测总线,其后通过analysis port写出目标analysis组件,在本节中它售后将连接到uvm_reg_predictor。
- mcdf_bus_driver主要实现了总线驱动和复位功能,通过模块化的方法reset_lsitener()、drive_bus()、driver_write()、drive_read()和drive_idle()可以解析三种命令模式IDLE、WRITE和READ,并且在READ模式下,将读回的数据通过item_done(rsp)写回到sequencer和sequence一侧。建议读者在通过clone()命令创建RSP对象后,通过set_sequence_id()和set_transaction_id()两个函数保证REQ和RSP的中保留的ID信息一致。
3.寄存器模型的常规方法
3.1 mirror、desired和actual value
- 我们在应用寄存器模型的时候,除了利用它的寄存器信息,也会利用它来跟踪寄存器的值。
- 寄存器模型中的每一个寄存器,都应该有两个值,一个是镜像值(mirrored vlaue),一个是期望值(desired value)。
- 期望值是先利用寄存器修改软件对象值,而后利用该值更新硬件值;镜像值是表示当前硬件的已知状态值。
- 镜像值往往由模型预测给出,即在前门访问时通过观察总线或者后门访问时通过自动预测等方式给出镜像值。
- 镜像值有可能与硬件实际值(actual value)不一致。例如状态寄存器的镜像值就无法与硬件实际值保持同步更新,另外如果其他访问寄存的通路修改了寄存器,那么可能由于那一路总线没有被监测,因此寄存器的镜像值也无法得到及时更新。
- 接下来我们要讨论寄存器模型的预测方式,与上面的三种值相关,这是因为预测行为会直接影响如何更新镜像值和期望值。
- 在介绍之前需要区别的是,mirrored value与desired value是寄存器模型的属性,而actual value对应着硬件的真实数值。
- 镜像值有可能与硬件实际值(actual value)不一致,例如状态寄存器的镜像值就无法与硬件实际值保持同步更新,另外如果其他访问寄存器的通路修改了寄存器,那么可能由于那一路总线没有被监测,因此寄存器的镜像也无法得到及时更新。
- 接下来我们要讨论寄存器模型的预测方式,与上面的三种值有关,这是因为预测行为会直接影响到如何更新镜像值和期望值。
- 在介绍之前需要区别的是,mirrored value与desired value是寄存器模型的属性,而actual value对应着硬件的真实数值。
3.2 prediction的分类
- UVM提供了两种用来跟踪寄存器值得方式,我们将其分为自动预测(auto prediction)和显式预测(explicit)。
- 如果用户想使用自动预测的方式,还需要调用函数uvm_reg_map::set_auto_predict()。
- 两种预测方式的显著差别在于,显示预测对寄存器数值预测更为准确,我们可以通过下面对两种模式的分析得出具体原因。
自动预测 - 如果用户没有在环境中集成独立的predictor,而是利用寄存器的操作来自动记录每一次寄存器的读写数值,并在后台自动调用predict()方法的话,这种方式被称之为自动预测。
- 这种方式简单有效,然而需要注意,如果出现了其它一些sequence直接在总线层面上对寄存器进行操作(跳过寄存器级别的write()/read()操作,或者通过其它总线访问寄存器等这些额外的情况,都无法自动得到寄存器的镜像值和预期值。
显式预测 - 更为可靠的一种方式是在物理总线上通过监视器来捕捉总线事务,并将捕捉到的事务传递给外部例化的predictor,该predictor由UVM参数化类uvm_reg_predictor例化并继承在顶层环境中。
- 在继承的过程中需要将adaptor与map的句柄也一并传递给predictor,同时将monitor采集的事务通过analysis port接入到predictor一侧。
- 这种继承关系可以使得,monitor一旦捕捉到有效事务,会发送给predictor,再由利用adapter的桥接方法,实现事务信息转换,并将转化后的寄存器模型有关信息更新到map中。
- 默认情况下,系统将采用显式预测的方式,这就要求集成到环境中的总线UVC monitor需要具备捕捉事务的功能和对应的analysis port,以便于用predictor连接。
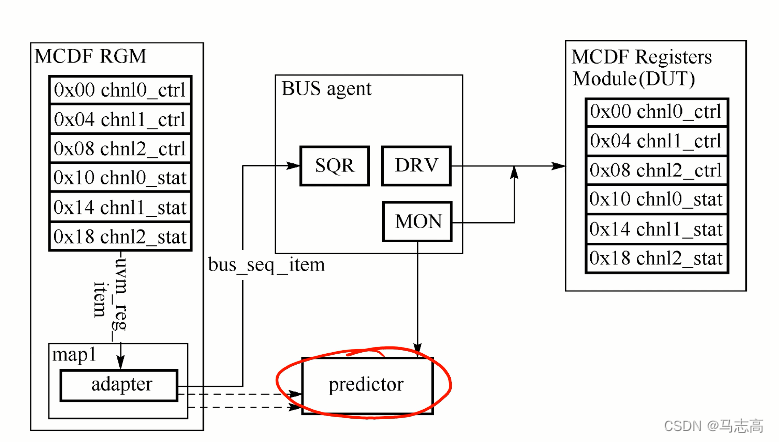
class mcdf_bus_env extends uvm_env;
mcdf_bus_agent agent;
mcdf_rgm rgm;
reg2mcdf_adapter reg2mcdf;
uvm_reg_predictor #(mcdf_bus_trans) mcdf2reg_predictor;
`uvm_component_utils(mcdf_bus_env)
...
function void build_phase(uvm_phase phase);
agent = mcdf_bus_agent::type_id::create("agent", this);
if(!uvm_config_db#(mcdf_rgm)::get(this, "", "rgm", rgm)) begin
`uvm_info("GETRGM", "no top-down RGM handle is assigned", UVM_LOW)
rgm = mcdf_rgm::type_id::create("rgm", this);
`uvm_info("NEWRGM", "create rgm instance locally", UVM_LOW)
end
rgm.build();
reg2mcdf = reg2mcdf_adapter::type_id::create("reg2mcdf");
mcdf2reg_predictor = uvm_reg_predictor #(mcdf_bus_trans)::type_id::create("mcdf2reg_predictor", this);
mcdf2reg_predictor.map = rgm.map;
mcdf2reg_predictor.adapter = reg2mcdf;
endfunction
function void connect_phase(uvm_phase phase);
rgm.map.set_sequencer(agent.sequencer, reg2mcdf);
agent.monitor.ap.connect(mcdf2reg_predictor.bus_in);
endfunction
endclass
3.3 uvm_reg的访问方法
-
更全面了解uvm_reg_block、uvm_reg、uvm_reg_filed三个列提供的用于访问寄存器的方法:
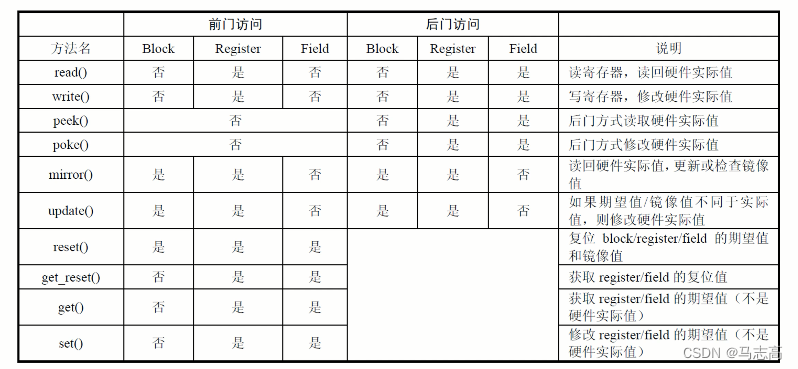
-
我们再讲uvm_reg_sequence提供的方法(均是针对寄存器对象的,而不是寄存器块或者寄存器域)整理如下:
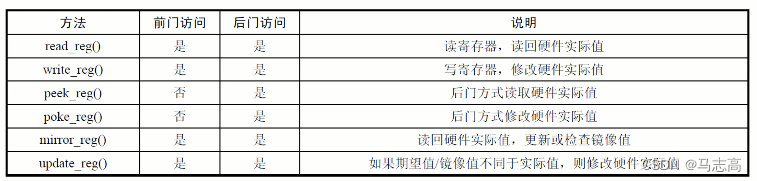
-
结合这mirrored value、desired value和actual value,我们需要理解这四种方法来调用时,三种数值的变化时序关系:
- 对于前门访问的read()和write(),在总线事务完成时,镜像值和期望值才会更新为与总线上相同的值,这种预测方式是显式预测。
- 对于peek()和poke(),以及后门访问模式下的read()和write(),由于不通过总线,默认采用自动预测的方式,因此在零时刻方法调用返回后,镜像值和期望值也相应修改。
-
关于reset()和get_reset()的用法,例如硬件在复位触发时,会将内部寄存器值复位,而寄存器模型的捕捉到复位事件时,为了保持同硬件行为一致,也应当对其复位。这里注意的是,复位的对象时寄存器模型,而不是硬件。

-
在复位之后,用户也可以通过读取寄存器模型的复位值(与寄存器描述文件一致),与前门访问获取的寄存器复位值是否按照寄存器描述去实现。这里的get_reset方法指的是寄存器模型的复位值,而不是硬件。

-
mirror()方法与read()方法类似,也可以选择前门访问或者后门访问,不同的是,mirror()不会返回读回的数值,但是会将对应的镜像值修改。在修改镜像值之前,用户还可以选择是否将读回的值与模型中原镜像值进行比较。
-
下面的例码在更新镜像值之前,首先将读回的值与上一次镜像值做了比对。随后再更新镜像值。又或者对于状态寄存器,可以选择只更新镜像值不做比较,这是因为状态寄存器随时可能被硬件内部逻辑修改。

-
下面的方法时运用set()和update()对寄存器做批量修改。
-
首先set()方法的对象时寄存器模型自身,通过set()可以修改期望值,而在寄存器配置时不妨对模型随机化,再配置个别寄存器或者域,当寄存器的期望值与镜像值不同时,可以通过update()方法来将不同的寄存器通过前门访问或者后门访问的方式做全部修改。
-
这种set()和update()的方式较write()和poke()的写寄存器方式更为灵活的是,它可以实现随机化寄存器配置值(先随机化寄存器模型,后将随机值结合某些域的指定值写到寄存器),继而模拟更多不可预知的寄存器应用场景,另外update()强大的批量寄存器功能使得修改寄存器更为便捷。

3.4 mem与reg的联系和差别
- UVM寄存器模型也可以用来对存储建模。uvm_mem类可以用来模拟RW(读写)、RO(只读)和WO(只写)类型的储存,并且可以配置存储模型的数据宽度和地址范围。
- uvm_mem不同于uvm_reg的地方在于,考虑到物理存储一旦映射到uvm_mem会带来更大的资源消耗,因此uvm_mem并不支持预测和影子存储(shadow storage)功能,即没有镜像值和期望值。
- uvm_mem可以提供的功能就是利用自带的方法访问硬件存储,相比于直接利用硬件总线UVC进行访问,这么做的好处在于:
- 类似于寄存器模型访问寄存器,利用储存模型访问硬件存储便于维护和复用。
- 在访问过程找那个,可以利用模型的地址范围来测试硬件的地址范围是否全部覆盖。
- 由于uvm_mem也同时提供前门访问和后门访问,这使得存储测试可以考虑先通过后门访问预先加载存储的内容,而后通过前门访问读取存储内容,继而做数据比对,这样做不但节省事假,同时也在测试方式上保持了前后一致性。同时这种方式相比于传统测试方式(利用系统函数或者仿真器实现存储加载),要在UVM框架中更为统一。
- 与uvm_reg相比,uvm_mem不但拥有常规的访问方法read()、write()、peek和poke(),也提供了burst_read()和burst_write()。之所以额外提供这两种方法,不但是为了可以更高速通过总线BURST方式连续存储,也是为了贴合实际访问储存中的场景。
- 要实现BURST访问形式,需要考虑下面的这些因素:
- 目前挂载的总线UVC是否支持BURST形式访问,例如APB不能支持BURST访问模式。
- 与read()、write()方法相比,burst_read()和burst_write()的参数列表中的一项uvm_reg_data_t value[]采用的是数组形式,不再是单一变量,即表示用户可以传递多个数据。而在后台,这些数据首选需要挂载到uvm_reg_item对象中,挂载时value数组可以直接希尔,另外两个成员需要分别指定为element_kind = UVM_MEM,kind = UVM_BURST_READ。
- 在adapter实现中,也需要考虑到存模型BURST访问的情形,实现四种访问类型的转换,即UVM_READ、UVM_WRITE、UVM_BURST_READ和UVM_BURST_WRITE。
- 对于UVM_READ和UVM_WRITE的桥接,已经咋寄存器访问中实现,而UVM_BURST_READ和UVM_BURST_WRITE的转换,往往需要考虑希尔的数据长度,例如长度是否是4,8,16或者其它。
- 此外还需要考虑不同总线的其他控制参数,例如AHB支持WRAP模式,AXI支持out-of-order模式等,如果想要将更多的总线控制封装在adapter的桥接功能里,需要将更多的配置作为扩展配置,在调用访问方法时为扩展信息类,传入到形式参数uvm_object extendsion。
- 对于更为复杂的BURST形式,如果徐涛实现更多的协议配置要求,那么推荐直接咋总线UVC层面去驱动。这样做的灵活性更大,且更能冲锋全面的测试存储接口的协议层的完备性。
3.5 内建(built_in)sequences
- 不少有经验的UVM用户可能会忽略UVM针对寄存器模型内建的一些sequence,实际上如果可以将这些自建的序列作为验证项目一开始的健康监测必须选项的话,这对于整个项目的平稳运行会有不小的贡献。
- 这是因为在项目已开的阶段,设计内部的逻辑还不稳定,对于verifier而言,如果想要跟上设计的进度,可以展开验证的部分无外乎是系统控制信号(时钟、复位、电源)和寄存器验证。
- 在项目早期,寄存器模型的验证可以为后期各个功能点验证打下良好的基础。比如,通过内建的寄存器或者存储序列可以实现完善的寄存器复位值检查,又比如检查写寄存器读写功能是否正常等。
- 不过还一些寄存即便可以测试,也建议将其作为例外而过滤出去,例如一些重要的系统控制信号(时钟、复位、电源),当写入某些值以后,会使得系统全部或者局部复位、时钟也可能会被关闭,这就可能阻碍寄存器的下一步检查。
- 所以UVM提供了一些特殊域,用来禁止sequence检查这些寄存器或者存储。
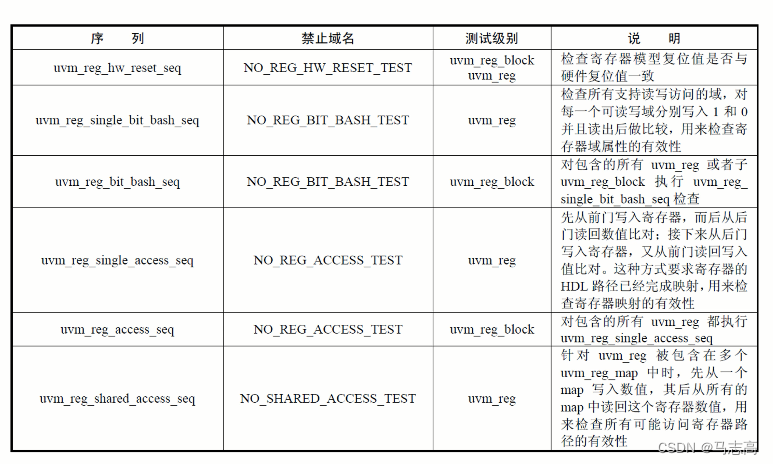
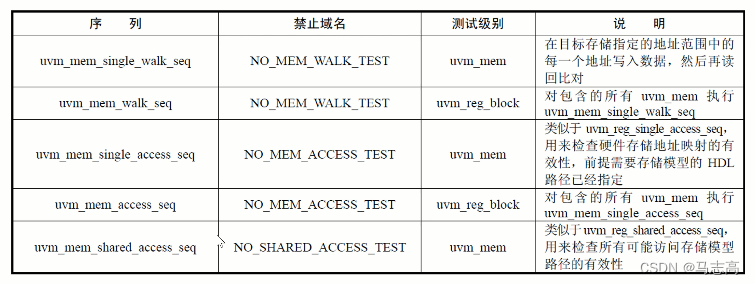
- 下面的例码演示如何利用内建序列完成MCDF寄存器测试一开始的健康检查。分别添加了uvm_reg_hw_reset_seq、uvm_reg_bit_bash_seq和uvm_reg_access_seq来测试寄存器模型。
- 从代码的整洁性来看,用户并不需要额外再添加什么,这种使用方式非常方便,且又能完成寄存器的大规模集成测试。
class mcdf_example_seq extends uvm_reg_sequence;
mcdf_rgm rgm;
`uvm_object_utils(mcdf_example_seq)
`uvm_declare_p_sequencer(mcdf_bus_sequencer)
...
task body()'
uvm_status_e status;
uvm_reg_data_t data;
uvm_reg_hw_reset_seq reg_rst_seq = new();
uvm_reg_bit_bash_seq reg_bit_bash_seq = new();
uvm_reg_access_seq reg_acc_seq = new();
if(!uvm_config_db#(mcdf_rgm)::get(null, get_full_name(), "rgm", rgm)) begin
`uvm_error("GETRGM", "no top-down RGM handle is assigned")
end
//wait reset asserted and release
@(negedge p_sequencer.vif.rstn);
@(posedge p_sequencer.vif.rstn);
`uvm_info("BLTINSEQ", "register reset sequence started", UVM_LOW)
reg_rst_seq.model = rgm;
reg_rst_seq.start(m_sequencer);
`uvm_info("BLTINSEQ", "register reset sequence finished", UVM_LOW)
`uvm_info("BLTINSEQ", "register bit bash sequence started", UVM_LOW)
//reset hardware register and register model
reg_bit_bash_seq.model = rgm;
reg_bit_bash_seq.start(m_sequencer);
`uvm_info("BLTINSEQ", "register bit bash sequence finished", UVM_LOW)
`uvm_info("BLTINSEQ", "register access sequence started", UVM_LOW)
//reset hardware register and register model
reg_acc_seq.model = rgm;
reg_acc_seq.start(m_sequencer);
`uvm_info("BLTINSEQ", "register access sequence finished", UVM_LOW)
endtask
endclass
4. 寄存器模型的应用场景
4.1 概述
- 在了解了寄存器模型的常规方法之后,我们需要考虑如何利用这些方法来检查寄存器,以及邪祖检查硬件设计逻辑和比对数据。
- 在软件实现硬件驱动和固件层时,也会实现类似寄存器模型镜像值得方法,即在寄存器配置的底层函数中,同时也声明一些全局的影子寄存器(shadow register)。
- 这些影子寄存器的功能就是暂存当时写入寄存器的值,而在后期使用时,如果这些寄存器是非易失的(non-volatile),那么便可以省略读取寄存器的步骤,转而使用影子寄存器的值。
- 这么做的好处在于响应更迅速,而不再通过若干个时钟周期的总线发起请求和等待响应,但另外一方面这么做的前提同我们测试寄存器模型的目的是一样的,即寄存器的写入值可以转却地反映到硬件中的寄存器。
- 利用寄存器模型的另外一个场景是,在对硬件数据通路做数据比对时,需要即使地知道当时的硬件配置情况,而利用寄存器模型的镜像可以实现实时读取,而不需要从前门访问。
- 也许读者会有别的选择,为什么不从后门访问呢?毫无疑问,后门访问也可以在零时刻内完成,只是这么做会省略检查寄存器的步骤,即假设寄存器模型的镜像值同硬件的寄存器真实值保持一致,而这一假设存在验证风险。所以只有这么做,才能为后期软件开发时使用影子寄存器扫清可能的硬件缺陷。
- 寄存器模型不但可以用来检查硬件寄存器,也可以用来配合scoreboard实时检查DUT的功能。
4.2 寄存器的检查
- 在配合scoreboard实施检查DUT的功能时,需要注意:
- 无论是将寄存器通过config_db进行层次化的配置,还是间接通过封装在配置对象(configuration object)中的寄存器模型句柄,都需要scoeboard可以缩影到寄存器模型。
- 在读取寄存器或者寄存器域的值时,用户需要加以区分。不少初学者默认uvm_reg类中应该对应有类似value的成员来表征其对应硬件寄存器的值,然而并没有。
- uvm_reg并不是寄存器的最小切分单元,uvm_reg_filed才是。
- uvm_reg可以理解为uvm_reg_field的容器,一个uvm_reg可以包含多个顺序排列的uvm_reg_filed。
- 在取值时,用户可以使用uvm_reg_field的成员value直接访问,但更建议使用uvm_reg类和uvm_reg_field类都具备的接口函数get_mirrored_vlaue()。
4.3 功能覆盖率概述
- 在测试寄存器以及设计的某些功能配置模式时,我们也需要统计测试过的配置情况。
- 就MCDF寄存器模型来看,除了测试寄存器的本身,我们还需要考虑在不同的配置下,设计的数据处理、仲裁等功能是否正确,所以我们需要放置功能覆盖率在寄存器模型中。
- 由于寄存器描述文件的结构化,我们可以通过扩充寄存器模型生成器的功能,使得生成的寄存器模型也可以自动包含各个寄存器域的功能覆盖率。
- UVM的寄存器模型已经内置了一些方法来使能对应的covergroup,同时在调用write()或者read()方法时,会自动调用covergroup::sample()来完成功能覆盖率收集。
覆盖率自动收集模式 - 如果寄存器模型生成器可以一并生成covergroup和对应的方法,我们就可以考虑是否例化这些covergroup、以及何时收集这些数据。
- 从示例中摘出的ctrl_reg寄存器的定义部分来看,value_cg是用来收集寄存器中所有的域(包含reserved只读区域)。
- 由于covergroup在此模式下可以自动生成,并且在使能的情况下,可以在每次read()、write()方法后调用。
- 从例化时的内存消耗、以及每次采集时的内存消耗,从上百个寄存器内置的covergroup联动的情况触发,是否例化、是否使能采集数据都需要考虑。
- 在验证前期,可以不例化covergroup,保证更好的资源利用;在验证后期需要采集功能覆盖率时,再考虑例化、使能采样。
- 在ctrl_reg的构建函数中,通过has_coverage()来判断是否需要例化的。该方法会调查成员ctrl_reg::m_has_cover,是否具备特定的覆盖率类型,而该成员在例化时,已经赋予了初值UVM_CVR_ALL,即包含所有覆盖率类型,因此,value_cg可以例化。
- 在新扩充的sample()和sample_values()两个方法时:
- sample()可以理解为read()、write()方法的回调函数,用户需要填充该方法,使得可以保证自动采样数据。
- sample_values()是供用户外部调用的方法,在一些特定事件触发时,例如中断、复位等场景,用户可以在外部通过监听具体事件来调用该方法。
- 在sample_values()方法时,可以通过get_coverage()方法来判断是否运行进行覆盖率采样。用户可能容易将has_coverage()与get_coverage()等方法混淆,就这两个方法而言,前者指是否具备对应的covergroup,后者指的是否允许使用对应的covergroup进行采样。
class ctrl_reg extends uvm_reg;
`uvm_object_utils(ctrl_reg)
uvm_reg_field reserved;
rand uvm_reg_field pkt_len;
rand uvm_reg_field prio_level;
rand uvm_reg_field chnl_en;
covergroup value_cg;
option.per_instance = 1;
reserved: coverpoint reserved.value[25:0];
pkt_len: coverpoint pkt_len.value[2:0];
prio_level: coverpoint prio_level.value[1:0];
chnl_en: coverpoint chnl_en.value[0:0];
endgroup
function new(string name="ctrl_reg");
super.new(name, 32, UVM_CVR_ALL);
set_coverage(UVM_CVR_FIELD_VALS);
if(has_coverage(UVM_CVR_FIELD_VALS)) begin
value_cg = new();
end
endfunction
virtual function build();
reserved = uvm_reg_field::type_id::create("reserved");
pkt_len = uvm_reg_field::type_id::create("pkt_len");
prio_level = uvm_reg_field::type_id::create("prio_level");
chnl_en = uvm_reg_field::type_id::create("chnl_en");
reserved.configure(this, 26, 6, "RO", 0, 26'h0, 1, 0, 0);
pkt_len.configure(this, 3, 3, "RW", 0, 3'h0, 1, 1, 0);
prio_level.configure(this, 2, 1, "RW", 0, 2'h3, 1, 1, 0);
chnl_en.configure(this, 1, 0, "RW", 0, 1'h0, 1, 1, 0);
endfunction
function void sample(
uvm_reg_data_t data,
uvm_reg_data_t byte_en,
bit is_read,
uvm_reg_map map
);
super.sample(data, byte_en, is_read, map);
sample_values();
endfunction
function void sample_values();
super.sample_values();
if(get_coverage(UVM_CVR_FIELD_VALS)) begin
value_cg.sample();
end
endfunction
endclass
覆盖率自动收集总结
- 借助于寄存器描述文件的良好格式,寄存器模型生成器通过模板的形式来生成可以控制例化和采样的寄存器模型。
- 如果用户在开发寄存器模型生成器时,也考虑是否通过上述参考的变量来控制,或者在生成时导入一些特定的编译导向(compiler directive),例如`ifndef的语句块来判断是否需要将寄存器的covergroup进行编译。
- 这些方法的目的都是为了更灵活的选择是否需要例化covergroup并采样数据,以此来保证仿真性能。
覆盖率外部时间触发收集 - 自动收集覆盖率的形式,不够灵活,而且不是很贴合实际场景。
- 不灵活的地方在于,它默认会采样所有的域,包括那些保留域,又或者对某一个域,为2位时,它会自动分配bin_0、bin_1、bin_2和bin_3来对应4个可能的值,殊不知可能val_3是为违法的。
- 又或者采样上述的状态寄存器中的域fifo_avail[7:0],那么是否要采集从0到63的所有可能值才能保证此域的完备性呢?
- 另外,不贴合实际场景的地方在于,它不够“智能”,无法组合出更有意义的运用场景。
- 例如在实际场景下,我们需要考虑三个通道是否同时使能、同时关闭,又或者有的使能有的关闭这些组合情形呢?
- 三个通道在使能时,是否考虑到了不同优先级、相同优先级、又或者两个通道相同优先级、一个通道不同优先级的情况呢?
- 这些场景,我们更应该在后期测试时考虑是否覆盖到。
- 因此建议,更贴合实际的、可作为覆盖率验收标准的covergroup定义还当采取自定义的形式,一方面来限定感兴趣的域和值,一方面来指定感兴趣的采样时间,即使用合适的事件来触发采样,通过这种方式,最后可以完成寄存器功能覆盖率的验证完备标准。
- 示例自定义一个覆盖率类,其中嵌入了对应的covergroup,以及指定的采样时间。这段例码中,定义了类mcdf_coverage,继承于uvm_subscriber,
覆盖率收集示例
class mcdf_coverage extends uvm_subscriber #(mcdf_bus_trans);
mcdf_rgm rgm;
`uvm_component_utils(mcdf_coverage)
covergroup reg_value_cg;
option.per_instance = 1;
CH0LEN: coverpoint rgm.chnl0_ctrl_reg.pkt_len.value[2:0] {bins len[] = {0, 1, 2, 3, [4:7]};}
CH0PRI: coverpoint rgm.chnl0_ctrl_reg.prio_level.value[1:0];
CH0CEN: coverpoint rgm.chnl0_ctrl_reg.chnl_en.value[0:0];
CH1LEN: coverpoint rgm.chnl1_ctrl_reg.pkt_len.value[2:0] {bins len[] = {0, 1, 2, 3, [4:7]};}
CH1PRI: coverpoint rgm.chnl1_ctrl_reg.prio_level.value[1:0];
CH1CEN: coverpoint rgm.chnl1_ctrl_reg.chnl_en.value[0:0];
CH2LEN: coverpoint rgm.chnl2_ctrl_reg.pkt_len.value[2:0] {bins len[] = {0, 1, 2, 3, [4:7]};}
CH2PRI: coverpoint rgm.chnl2_ctrl_reg.prio_level.value[1:0];
CH2CEN: coverpoint rgm.chnl2_ctrl_reg.chnl_en.value[0:0];
CH0AVL: coverpoint rgm.chnl0_stat_reg.fifo_avail.value[7:0] {bins avail[] = {0, 1, [2:7], [8:55], [56:61], 62, 63};}
CH1AVL: coverpoint rgm.chnl0_stat_reg.fifo_avail.value[7:0] {bins avail[] = {0, 1, [2:7], [8:55], [56:61], 62, 63};}
CH2AVL: coverpoint rgm.chnl0_stat_reg.fifo_avail.value[7:0] {bins avail[] = {0, 1, [2:7], [8:55], [56:61], 62, 63};}
LEN_COMB: cross CH0LEN, CH1LEN, CH2LEN;
PRI_COMB: cross CH0PRI, CH1PRI, CH2PRI;
CEN_COMB: cross CH0CEN, CH1CEN, CH2CEN;
AVL_COMB: cross CH0AVL, CH1AVL, CH2AVL;
endgroup
function new(string name, uvm_component parent);
super.new(name, parent);
reg_value_cg = new();
endfunction
function void build_phase(uvm_phase phase);
if(!uvm_config_db#(mcdf_rgm)::get(this, "", "rgm", rgm)) begin
`uvm_info("GETRGM", "no top-down RGM handle is assigned", UVM_LOW)
end
function
function void write(T t);
reg_value_cg.sample();
endfunction
endclass
















 2360
2360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











