







Scikit-learn最早由数据科学家David Cournapeau 在2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
-
作为专门面向机器学习的Python开源框架,Scikit-learn可以在一定范围内为开发者提供非常好的帮助。它内部实现了各种各样成熟的算法,容易安装和使用,样例丰富,而且教程和文档也非常详细。
-
线性回归模型(linear-reggration)是机器学习中最基础也是最简单的算法。主要是拟合y = ax + b这样一个公式,其中a,b都是向量。通过输入数据利用最小二乘法直接求出参数a,b
线性回归在scikit -learn的linear_model模块中,只需从相应的位置导入即可,首先我们先导入sklearn ,Python数值处理模块numpy和Python的画图工具matploylib。
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
- 然后从sklearn的datasets中导入波士顿房价数据集
loaded_data = datasets.load_boston()
X_data = loaded_data.data
y_data = loaded_data.target
- 查看一下波士顿 房价数据集的特征名称
loaded_data.feature_names
>> array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
- 下面划分数据集,一部分用于训练,另一部分用来做测试,sklearn中自然也有相应的方法可以直接实现,其中random_state是一个随机种子,可以是任意一个数
X_train,X_test,y_train,y_test = train_test_split(X_data,y_data,test_size = 0.3,random_state = 42)
model = LinearRegression()
model.fit(X_train,y_train)
- 上述过程已经训练好了一个线性回归模型,调用model.predict可以预测某一个或者某一些输入值相应的输出
model.predict(X_test[:5,:])
>> array([28.64896005, 36.49501384, 15.4111932 , 25.40321303, 18.85527988])
- 我们可以通过查看y_test的真实值,对比模型预测值与真实值的差距。
y_test[:5]
>> array([23.6, 32.4, 13.6, 22.8, 16.1])
- 同时可以查看模型的斜率和截距,也就是线性回归模型y = ax + b中的a,b
a = model.coef_ # 模型的斜率(权重)
b = model.intercept_ #模型的截距(偏置)
print('模型的斜率是:{0} \n相应的截距是:{1}'.format(a,b))
>> 模型的斜率是:[-1.33470103e-01 3.58089136e-02 4.95226452e-02 3.11983512e+00
-1.54170609e+01 4.05719923e+00 -1.08208352e-02 -1.38599824e+00
2.42727340e-01 -8.70223437e-03 -9.10685208e-01 1.17941159e-02
-5.47113313e-01]
相应的截距是:31.63108403569312
- 下面查看R²拟合优度和模型得分,R²拟合优度是指回归直线对观测值的拟合程度。R²的范围是0-1。R²的值越接近1,说明回归直线对观测值的拟合程度越好;反之,R²的值越小,说明回归直线对观测值的拟合程度越差。
y_hat = model.predict(X_test)
from sklearn.metrics import r2_score
r2_score(y_hat,y_test) # 0.669370269149561
r2_score(y_test,y_hat) # 0.711226005748496
r2 = model.score(X_test,y_test)
r2 # 0.711226005748496
>> 0.711226005748496
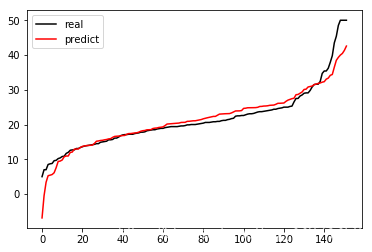
- 可以画图更直观的查看一下模型的拟合情况
plt.plot(range(len(y_test)),sorted(y_test),c='k',label = 'real')
plt.plot(range(len(y_hat)),sorted(y_hat),c='r',label = 'predict')
plt.legend()
plt.show()















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









