










1.1 目标检测的任务及分类
目标检测(Object Detection)就是要从图像中定位并框选出分类好的目标。这也就决定了目标检测的四大任务,下图所示:
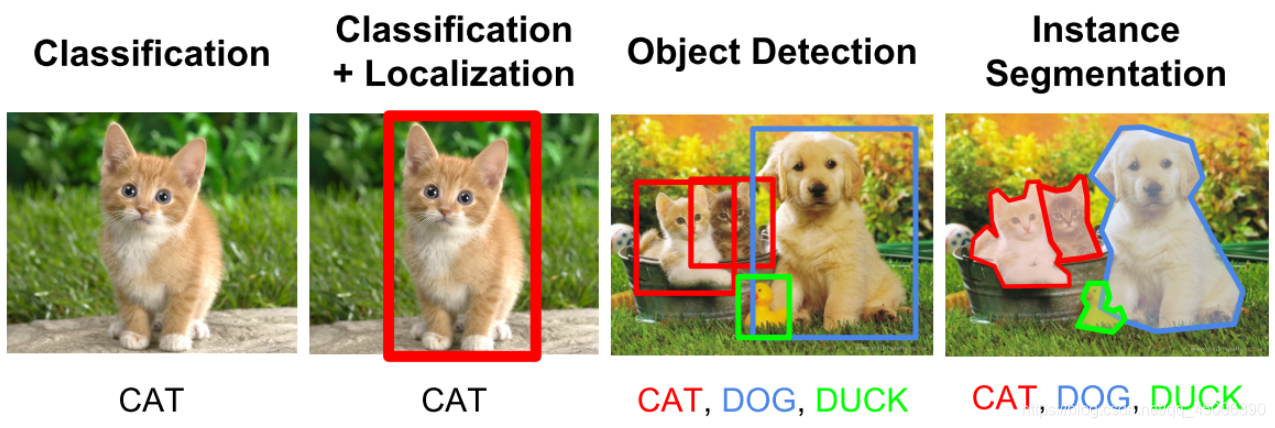
1)分类(Classification):告诉计算机需要从视频或者图片中找出哪几类目标。
2)定位(Location):计算机识别出目标图像后,需要在原图片中用预测框框选出目标图像所在的位置。
3)检测(Object Detection):计算机不仅需要定位目标图像所在的位置,同时也需要知道定位的是哪一类目标。
4)分割(Instance Segmentation):在出现多类别目标识别的情况下,计算机不仅需要弄清目标图像是什么在哪里,还需要解决框选出的像素分别是属于哪一类目标的问题。
目前对于指针式仪表进行目标检测的方法大致可以分为以下的两类:
1)以模板匹配法为代表的指针式仪表表盘检测方法。
2)基于深度学习的指针式仪表表盘检测方法。
1.2 传统目标检测算法
1.2.1 模板匹配法算法原理
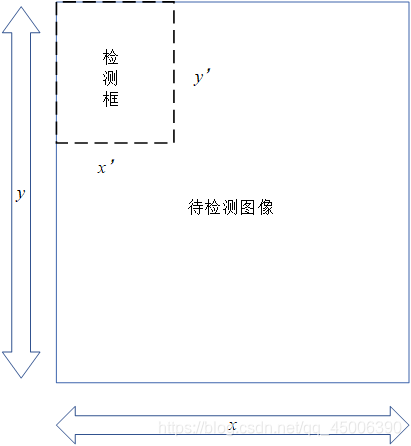
以模板匹配法为代表的传统目标检测算法,在进行目标识别检测时,会对一张输入的图像,采取绘制检测框的方式,用检测框对这张图像进行遍历,每一次检测框中返回的待检测图像都会与数据库中的模板图像进行对比,通过模板匹配算法判断检测框中图像与模板的匹配程度,当匹配度足够高时,则认为是寻找到了待检测的目标。
在OpenCV 中主要使用了六种判断检测框中图像与模板是否匹配的方法,主要包括:平方差匹配法、相关匹配法、相关系数匹配法以及他们的归一化匹配法。这些匹配方法在OpenCV 中已经封装为函数,可以根据使用的情景进行合理的选择。
1.2.2 模板匹配法算法实现流程
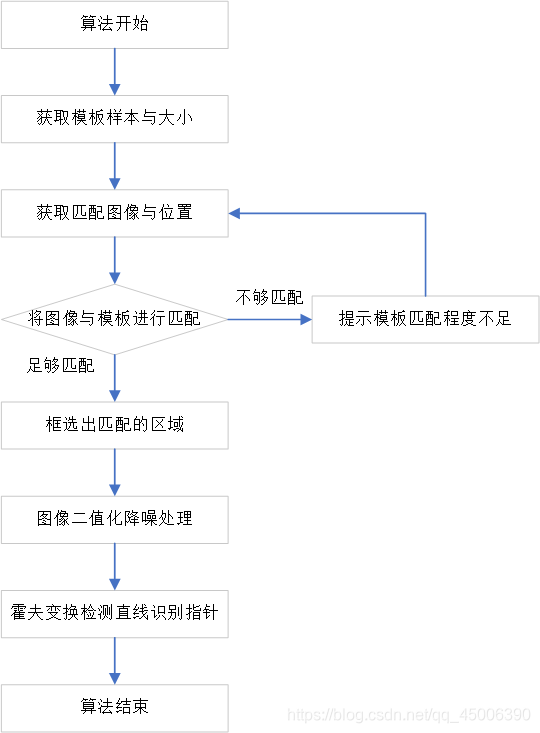
采用模板匹配法来进行指针式仪表识别,首先需要输入模板图像,接着从视频流中获取待匹配图像的大小与位置,利用模板匹配算法判断待匹配图像是否与模板图像相近,若两者匹配程度不足,则继续在视频流中匹配;若匹配程度足够,则在视频中框选出匹配的区域。将匹配的区域提取出来,对其进行图像的降噪以及二值化,利用霍夫变化检测直线在匹配的区域中寻找指针,并用白线标出。模板匹配法算法流程较为简单,以流程图形式表现如下:
1.2.3 模板匹配法识别效果评价
尽管模板匹配法在算法原理以及实现方面较为简单,但是其识别效果往往不尽如人意。
1)模板匹配法的模板与待匹配的图像需要保持一致,这就使得模板匹配法在仪表识别上存在局限性:只能识别出与模板仪表同类型的指针式仪表,对于其他类型的仪表缺乏准确的识别能力。
当模板图像为圆形指针式仪表(常为压力表)时,若输入的待检测图像为同类型仪表,则可以正常识别:

当模板图像为矩形指针式仪表(常为电压电流表)时,若输入的待检测图像仍为圆形指针式仪表,则会出现模板不匹配或误识别的情况:

2)模板匹配法对小目标以及处于复杂背景图像中的目标识别检测效果较差,对于小目标往往难以检测;同时若所处背景较为复杂时,也会出现误识别。
以圆形仪表为模板,对小目标以及复杂背景情况下的仪表进行检测,检测结果如下:
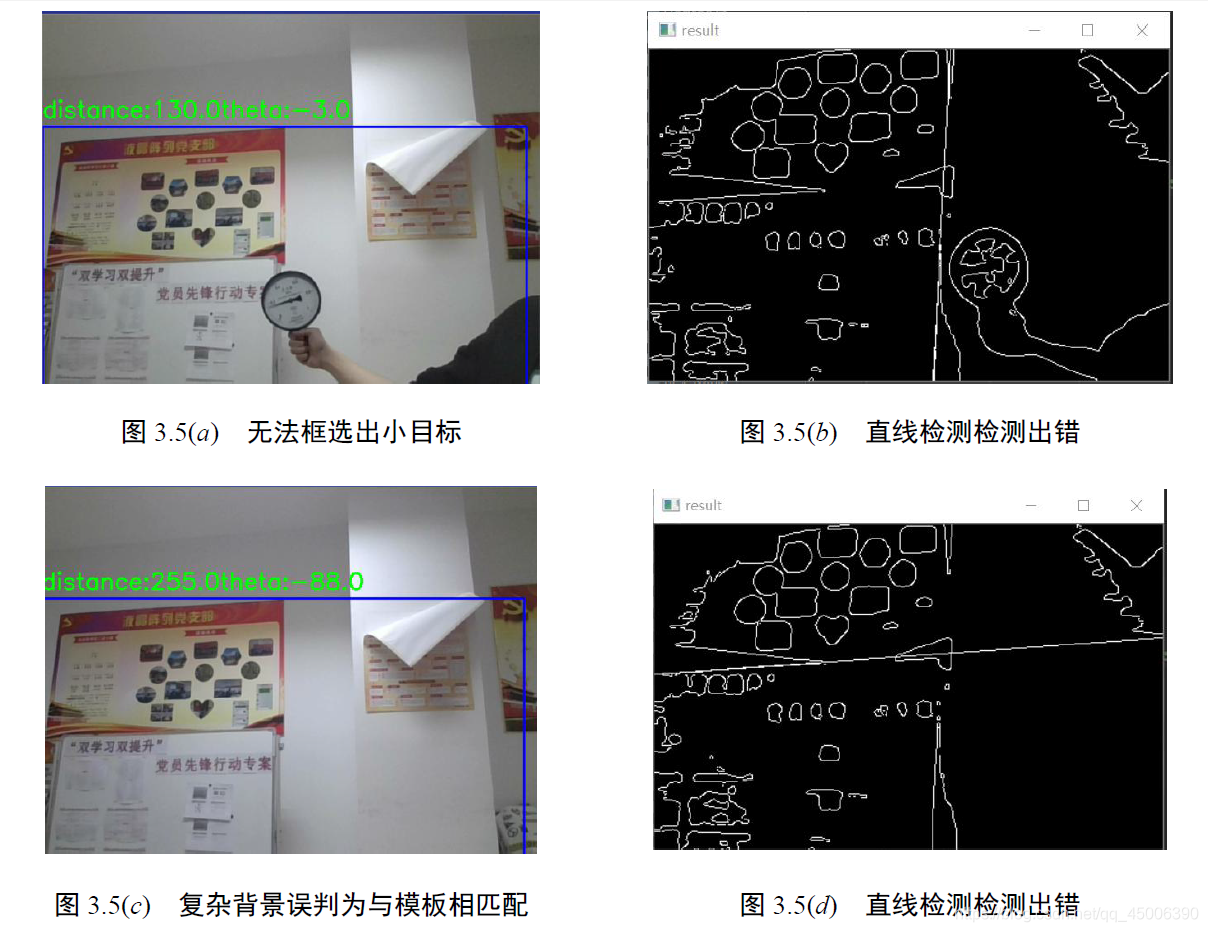
模板匹配法只能判断输入的图像与模板的匹配程度,这就导致一旦检测背景过于复杂,那么模板匹配法的可靠性就会大幅下降。在实验室环境中可以通过对仪表设立专门的摄录设备进行研究,但在复杂的生产环境下,很难做到对每一个仪表进行一对一的读数。因此,模板匹配法难以适用于复杂生产环境下的指针式仪表识别检测中。
1.3 基于深度学习的目标检测算法
基于深度学习的目标检测算法包括:
1)采用区域提名(Region Proposal)的目标检测算法:
采用区域提名的目标检测算法,其核心思想是把图像划分为特定的区域,将在复杂图像中寻找目标物的问题,转化为对图像中的不同区域判断其是否包含待检测的目标物的问题(也称为Two Stage 方式),代表算法有R-CNN 系列[22,23]。采用区域提名的目标检测算法流程图如下:
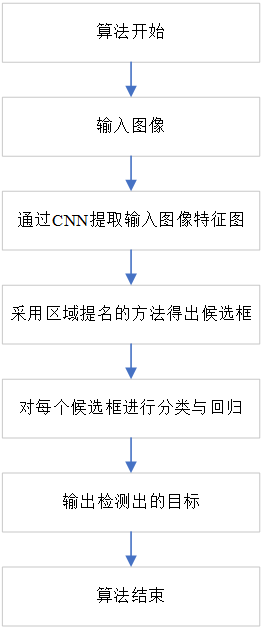
采用区域提名的目标检测算法,需要对输入的图像进行区域划分,然后在划分好的区域上用事先准备好的检测框进行检测,但由于需要穷举大量的候选框,虽然识别精度很好但所需的检测识别的时间较久。
常用的区域提名方法,主要有滑动窗口法、规则块法和选择搜索法。前两种方法在整体思路上与传统的目标检测相似,都是通过绘制一个候选窗口在输入的图像上进行滑动穷举,配合分类器判断其中是否包括目标物体。而两者的不同之处在于,滑动窗口法需要根据输入图像的大小,手动调整候选框的大小,而规则块法则是针对大小相近的输入图像,采用固定大小的候选框对整体图像进行滑动穷举。较前者而言,规则块法虽然避免了手动调整候选框,但其本质仍是穷举法,需要耗费大量的时间。同时,穷举法带来了过多的包含目标物的候选框,这使得分类器提取出来的候选框会存在大规模的重叠,这也是滑动窗口法和规则块法最大的问题。

针对滑动窗口法以及规则块法存在的问题,选择搜索法对划分好的区域进行相似性判断,若两个区域存在很高的相似性,那么就将这两个区域合并为一个新的区域,并以外接矩形(bounding box)对其进行框选,并将这个新的区域重新放回图像中继续进行相似性判断与合并,通过不断进行合并迭代,使得最后保留下的候选框之间几乎不出现重复的现象。
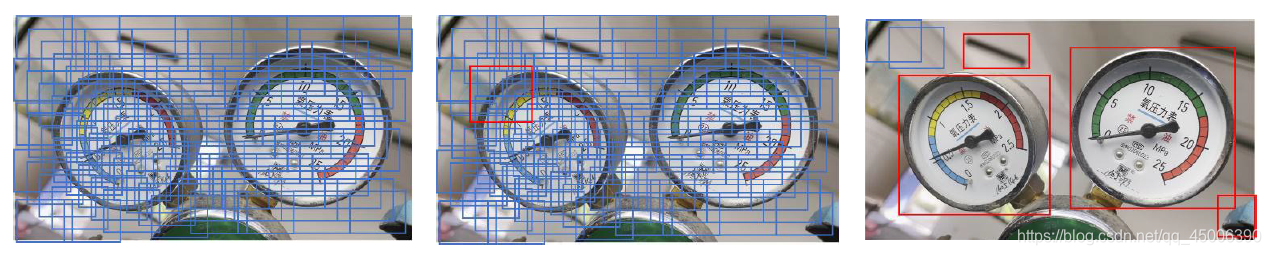
采用选择搜索法进行区域提名,可以有效减少候选框的数量,并在此基础上在进行目标检测,较传统的滑窗法与规则块法而言大大提高了计算效率与检测出目标物的概率。
2)无需区域提取的目标检测算法:
无需区域提名的目标检测算法,其核心思想是将候选框的划分与目标物的检测合二为一,不再需要通过分类器对候选框是否包含目标物进行判断,而是直接利用候选框来完成分类回归(也称为One Stage 方法),代表算法有YOLO,SSD。无需区域提名的算法流程图如下:
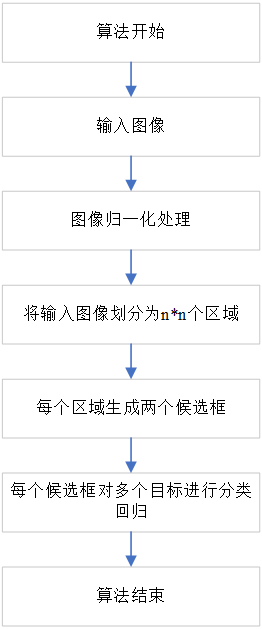
在输入的图像进行归一化处理后,将其划分为固定数量的网格(cell),每个网格可以生成两个候选框,而每个候选框都可以对多个不同类别的目标进行置信度评价。若该候选框得出的目标置信度大于设置的目标置信度阈值,则保留该候选框并返回其分类、位置和置信度;若该候选框得出的目标置信度小于设置的目标置信度阈值,则认为该候选框为无效候选框,并对其进行删除。
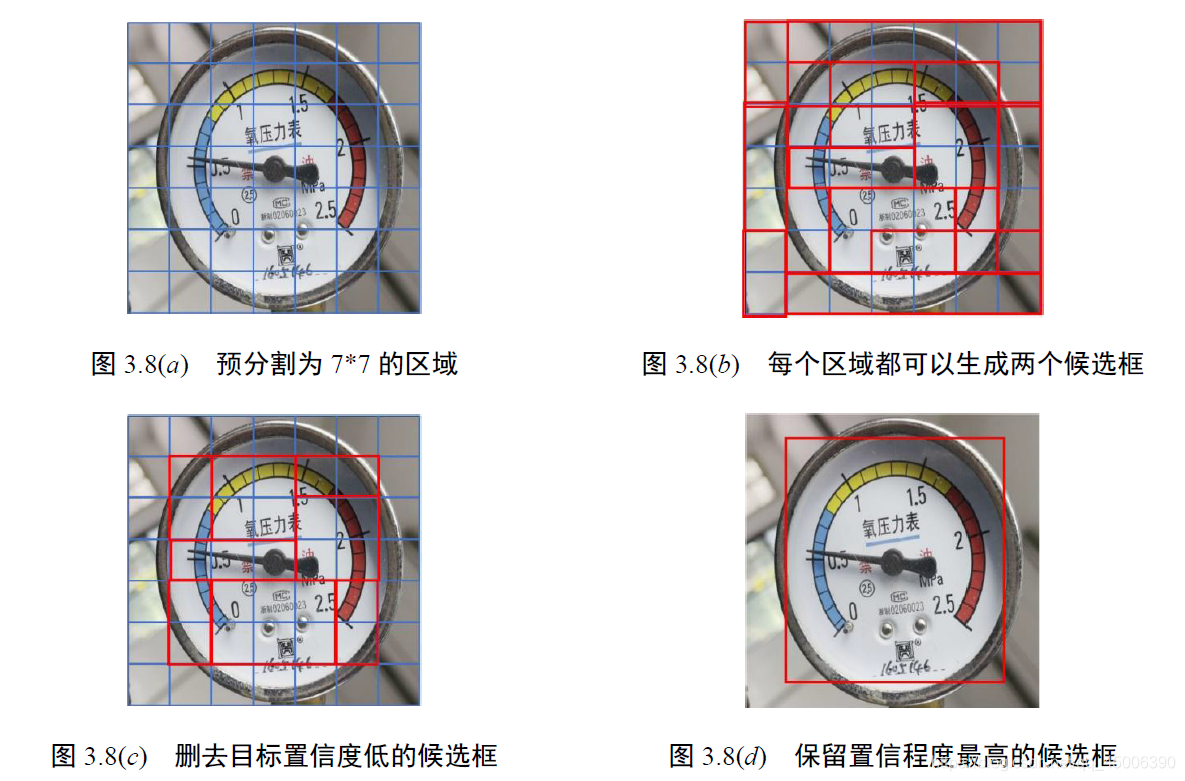
无需区域提名的目标检测算法预先划分了n * n 个网格,在输入的图像上只需生成2n^2 个候选框,大大减少了所需的候选框的数量,虽然这也导致了其对于图像中小物体的辩识能力较差,但是这2n^2 个候选框中的每一个都可以对多种目标进行置信度评价,使得检测识别速度得到大幅提高,更加适合基于视频流的目标检测与识别。

















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









