







一、为什么要有智能指针
C++中已经有了new和delete关键字,在堆上能开辟内存也能释放内存,那为什么还需要智能指针呢?或者说采用new和delete关键字还有什么缺点吗?下面来举一个例子
int* fun()
{
int *x = new int(10);
return x;
}
int main()
{
int *y = fun();
}
在该代码中,fun()函数负责返回一个指针,main()函数中用一个指针来接收它,但是全篇都没有使用delete函数,也就是说发生了内存泄漏,那么内存泄漏的责任该是谁来负呢?接下来对这两个函数进行问责:
fun()说:我只负责创建这样一个指针并且返回,如果我删除了,你就接收不到了,所以你要接收的话就要你负责删除。
main()说:这个空间是你开辟的,你开辟就得你负责删除。
双方好像说的都有道理,但是最终出了事故却不好问责,这也就是使用new和delete的缺点,也就是内存的所有权不清晰,当如上面两个函数都比较懒都不销毁的时候,就会产生内存泄漏的问题,有时候可能出现多销毁的情况导致程序崩溃。
二、智能指针基本实现
智能指针本质上是一个类模板,可以存放不同数据类型的指针,并且在使用完之后可以调用析构函数自动释放指针指向的内存。所以一个智能指针至少需要以下几个部分:构造函数、析构函数、指针对象、*运算符重载、->运算符重载。
template<class T>//类模板
class smartPtr
{
private:
T* m_ptr;//指针对象
public:
smartPtr(T* ptr)//构造函数
:m_ptr(ptr)
{}
~smartPtr()//析构函数
{
if(m_ptr!= nullptr)
{
std::cout<<"smart point delete"<<std::endl;
delete m_ptr;
m_ptr = nullptr;
}
}
T& operator*()//重载*运算符
{
return *m_ptr;
}
T* operator->()//重载->运算符
{
return m_ptr;
}
};
使用该智能指针进行测试:
int main() {
smartPtr<int> x(new int(5));
smartPtr<float> y(new float(3.14));
std::cout<<"the x value is: "<<(*x)<<std::endl;
std::cout<<"the y value is: "<<(*y)<<std::endl;
return 0;
}
测试结果为:
the x value is: 5
the y value is: 3.14
smart point delete
smart point delete
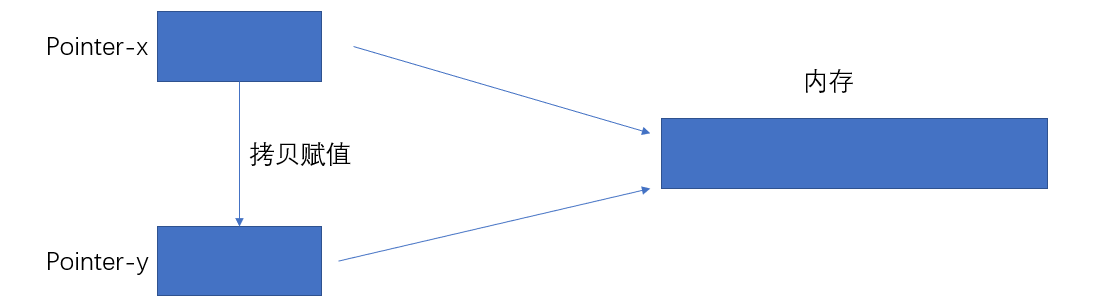
可见该智能指针的表现与预期一致,在程序结束时,会自动调用析构函数释放内存,避免了内存泄漏。上述测试案例使用的是赋值构造函数,如果使用拷贝构造的话,会调用默认的拷贝构造函数,也就是值复制(指针指向的地址一样),这种复制在析构的时候会重复删除同一片内存,造成程序崩溃,示意图如下:
实际的智能指针需要提供拷贝构造函数和赋值重载函数来避免这样的问题,所以接下来对实际的一些智能指针进行介绍。
三、实际的智能指针的实现
1、auto_ptr
该智能指针早在C++98时就被提出,在C++17的时候被废除,该智能指针对于拷贝赋值的解决办法是将被拷贝的智能指针的指针对象变为空指针nullptr,实现的代码如下:
std::auto_ptr<T> operator=(std::auto_ptr<T>& copyptr)
{
if(ptr != copyptr)
{
ptr = copyptr.ptr;
copyptr.ptr = nullptr;
}
return ptr;
}
当auto_ptr使用拷贝构造或者赋值重载的时候,被拷贝的对象的指针就会为空指针,如果这时候再使用原来的智能智能可能就会造成程序崩溃,所以尽量避免出现这种问题,或者说尽量避免使用auto_ptr。
2、unique_ptr
为了防止拷贝构造和赋值重载时出现的问题,unique_ptr直接把该拷贝构造函数和赋值重载函数删除了,如果程序中使用到此类函数,编译器会直接报错。
unique_ptr(unique_ptr&) = delete;
unique_ptr<T> operator=(unique_ptr&) = delete;
如果想要给unique_ptr对象赋值,只能使用make_unique(value)方法。
从这个只能指针的名字也能看出其性质,unique_ptr禁止一切想与其共享内存的行为,例如unique_ptr作为实参传入函数时,只能使用引用传递、不能进行拷贝构造等等。
因为其不能进行拷贝和复制,所以如果想要将一个智能指针的值赋给另一个指针,只能先将使用std::move将其转化为将亡值,再复制过去,这样也能避免共享内存的行为。
3、shared_ptr
从名字上可以看出这个指针相对于unique_ptr来说更加大方,其允许多个智能指针指向同一片资源,并且其能够保证不论多少个指针使用同一内存资源,最后释放的时候只会释放一次,因此不会因为多次释放导致程序崩溃。
(1)实现原理
shared_ptr使用的引用计数的方法来解决一次释放的问题,在该模板类的内部,存放着一个引用计数,该数值表明了现在正在有多少个对象在使用这一个内存资源,当调用析构函数的时候(shared_ptr 对象被销毁),该引用计数会减1,当计数到达0的时候,表明自己是最后一个使用该资源的对象,因此需要完成资源的释放。
(2)存在的问题
- 引用计数需要加锁
由于引用计数的值在堆上,当有多个线程的时候,由于不同的线程可能都会修改引用计数的值,这样可能会产生错误,出现线程安全的问题,因此需要在修改引用计数的时候加锁来保证其数据的正确性,防止程序出现问题。
- 循环引用问题
如果我们需要定义一个双向链表,在定义节点的时候,指针的部分使用shared_ptr智能指针
struct DoublyLinkList
{
shared_ptr<DoublyLinkList> pre;
shared_ptr<DoublyLinkList> next;
}
当使用下面的代码进行测试:
int main()
{
std::shared_ptr<DoublyLinkList> ptr1(new DoublyLinkList);
std::shared_ptr<DoublyLinkList> ptr2(new DoublyLinkList);
ptr1->next = ptr2;
ptr2->pre = ptr1;
std::cout<<"the node1's count is: "<<ptr1.use_count()<<std::endl;
std::cout<<"the node2's count is: "<<ptr2.use_count()<<std::endl;
return 0;
}
输出结果为:
the node1's count is: 2
the node2's count is: 2
出现上面现象的原因为:
当node1和node2被创建的时候,二者的引用计数都为1;
当ptr1->next指向node2时,node2的引用计数加1变为2,当ptr->pre指向node1时,node1的引用计数也加1;
当程序结束时,node1和node2对象销毁,此时引用计数都减1,但是都不是,所以此时内存并不会被释放。
如果想要释放二者的资源
若想要释放node1的资源,首先要销毁node2->pre;
而要销毁node2->pre就需要释放node2;
要释放node2的资源,就得销毁node1->next;
要销毁node1->next,就要释放node1;
这样形成了一种循环引用,导致最终资源并不会被释放。
这种循环引用的问题该怎么解决呢?这就需要下面的weak_ptr智能指针了。
4、weak_ptr
weak_ptr类型的指针可以指向shared_ptr类型的对象,但是并不会改变shared_ptr类型对象的引用计数,我们将上面循环引用的代码修改成weak_ptr重新执行查看效果。
struct DoublyLinkList
{
std::weak_ptr<DoublyLinkList> pre;
std::weak_ptr<DoublyLinkList> next;
};
int main()
{
std::shared_ptr<DoublyLinkList> ptr1(new DoublyLinkList);
std::shared_ptr<DoublyLinkList> ptr2(new DoublyLinkList);
ptr1->next = ptr2;
ptr2->pre = ptr1;
std::cout<<"the node1's count is: "<<ptr1.use_count()<<std::endl;
std::cout<<"the node2's count is: "<<ptr2.use_count()<<std::endl;
return 0;
}
运行结果:
the node1's count is: 1
the node2's count is: 1
可见此时就不会出现循环引用的问题,资源能正确释放了。
因此在定义双向链表或者二叉树等有多个指针的时候,如果想要将指针定义为智能指针,那么结构体内部的指针需要定义为weak_ptr来防止循环引用的问题。















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









