






本文结合深蓝学院课程学习和本人的理解,欢迎交流指正
NeRF流程简述
NeRF的总体流程简单来说是这样的:
沿一条摄像机光线穿过场景得到三维采样点,得到位置坐标(x, y, z),再加上对应的二维观察方向(θ, ψ),形成一个5D坐标,输入神经网络MLP。神经网络会输出一组颜色RGB和密度σ。
有了每个采样点的RGB和密度信息,通过体渲染的方式,把这些色彩合并起来,就得到了当前像素点的值。获取像素点的值之后计算和真实值之间的损失,用这个损失指导神经网络的参数更新。渲染出所有像素点的值,就得到了我们需要的图像。

下面结合代码来具体解释一下训练和测试流程,源代码地址:nerf-pytorch,以源代码run_nerf.py文件中的train()函数为主线。
1.加载参数和数据集
首先要加载各种参数信息,具体的参数配置定义在config_parser()中。
# 加载各种参数信息
parser = config_parser()
# 用于解析命令行输入的参数
args = parser.parse_args()
在源代码中所有参数的作用都给了注释,这里截取解释一部分。
# rendering options
# 允许用户指定在体积渲染过程中,除了基本采样点之外,每条光线上额外的精细采样点的数量。默认值为0不使用
parser.add_argument("--N_importance", type=int, default=0,
help='number of additional fine samples per ray')
# 3D位置编码的最大频率
parser.add_argument("--multires", type=int, default=10,
help='log2 of max freq for positional encoding (3D location)')
# 2D方向编码的最大频率
parser.add_argument("--multires_views", type=int, default=4,
help='log2 of max freq for positional encoding (2D direction)')
# 用于在模型的原始预测中引入噪声,这通常是为了正则化模型的训练过程,防止过拟合
# 在训练过程中,通过引入噪声,模型不会对训练数据的每个细节都过于敏感,这有助于模型在面对新的、未见过的数据时做出更好的预测。
parser.add_argument("--raw_noise_std", type=float, default=0.,
help='std dev of noise added to regularize sigma_a output, 1e0 recommended')
#这个选项指示算法加载预先训练好的模型权重来渲染新的图像或动画。通常用于在模型训练完成后,生成最终的输出结果。
parser.add_argument("--render_only", action='store_true',
help='do not optimize, reload weights and render out render_poses path')
# 如果要生成模型在测试集上的表现,比如为了评估模型的泛化能力或者生成测试数据的可视化,可以在命令行中添加 --render_test
parser.add_argument("--render_test", action='store_true',
help='render the test set instead of render_poses path')
# 用于加速采样的下采样因子
# 通过设置 --render_factor,可以快速预览渲染效果,但图像的分辨率会降低。
parser.add_argument("--render_factor", type=int, default=0,
help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')
# training options
# 预裁剪训练是一种常见的策略,特别是在训练初期,模型尚未学习到足够的特征时。
# 通过在训练的前几轮迭代中仅使用图像的中心区域,模型可以更快地学习到图像的主要结构,而不会被边缘的噪声或不相关的信息干扰。
parser.add_argument("--precrop_iters", type=int, default=0,
help='number of steps to train on central crops')
# 设置参数的默认值为0.5,意味着如果不在命令行中指定该参数,则使用图像中心的一半作为中心裁剪区域。
parser.add_argument("--precrop_frac", type=float,
default=.5, help='fraction of img taken for central crops')
# dataset options
# 设置参数的默认值为8,意味着如果不在命令行中指定该参数,将默认加载测试/验证集中的1/8图像。
parser.add_argument("--testskip", type=int, default=8,
help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels')
## llff flags
# 对于非正对场景,可以选择不使用规范化设备坐标。
parser.add_argument("--no_ndc", action='store_true',
help='do not use normalized device coordinates (set for non-forward facing scenes)')
# 可以选择是否使用线性视差采样
parser.add_argument("--lindisp", action='store_true',
help='sampling linearly in disparity rather than depth')
# 这个选项用于设置球形360度场景
parser.add_argument("--spherify", action='store_true',
help='set for spherical 360 scenes')
# 每8张图像用1张做测试集
parser.add_argument("--llffhold", type=int, default=8,
help='will take every 1/N images as LLFF test set, paper uses 8')
然后就是加载数据集,源代码中有四个加载数据集的.py文件,针对不同的数据集类型,函数中会调用不同的函数实现数据加载,这里以加载blender数据集的文件load_blender.py为例。
import os
import torch
import numpy as np
import imageio
import json
import torch.nn.functional as F
import cv2
# 平移矩阵 参数t是平移距离
trans_t = lambda t : torch.Tensor([
[1,0,0,0],
[0,1,0,0],
[0,0,1,t],
[0,0,0,1]]).float()
# 旋转矩阵 参数phi是旋转角度
rot_phi = lambda phi : torch.Tensor([
[1,0,0,0],
[0,np.cos(phi),-np.sin(phi),0],
[0,np.sin(phi), np.cos(phi),0],
[0,0,0,1]]).float()
# 旋转矩阵θ 参数th是旋转角度
rot_theta = lambda th : torch.Tensor([
[np.cos(th),0,-np.sin(th),0],
[0,1,0,0],
[np.sin(th),0, np.cos(th),0],
[0,0,0,1]]).float()
# 生成相机位姿,也就是外参矩阵,用于世界坐标系和相机坐标系的相互转换
def pose_spherical(theta, phi, radius):
c2w = trans_t(radius)
c2w = rot_phi(phi/180.*np.pi) @ c2w
c2w = rot_theta(theta/180.*np.pi) @ c2w
#这里在调整坐标系
c2w = torch.Tensor(np.array([[-1,0,0,0],[0,0,1,0],[0,1,0,0],[0,0,0,1]])) @ c2w
return c2w
# 加载blender数据,"Blender" 指使用Blender软件生成的合成数据集 basedir-包含数据集的基础目录 half_res-是否将图像下采样到半分辨率 testskip-在加载测试集时跳过一定数量的帧。
def load_blender_data(basedir, half_res=False, testskip=1):
splits = ['train', 'val', 'test']
metas = {}
# 相机位姿存储在JSON文件中
for s in splits:
with open(os.path.join(basedir, 'transforms_{}.json'.format(s)), 'r') as fp:
metas[s] = json.load(fp)
# 读取所有图像及对应位姿
all_imgs = []
all_poses = []
counts = [0]
for s in splits:
meta = metas[s]
imgs = []
poses = []
if s=='train' or testskip==0:
skip = 1
else:
skip = testskip
# meta['frames'][::skip] 会生成一个序列,其中只包含 meta['frames'] 列表中每隔 skip 个元素的一个元素。
for frame in meta['frames'][::skip]:
#构建图像完整路径并添加到imgs
fname = os.path.join(basedir, frame['file_path'] + '.png')
imgs.append(imageio.imread(fname))
poses.append(np.array(frame['transform_matrix']))
# 将读取的图像转换为浮点数类型,并将像素值归一化到 [0, 1] 范围内。同时,保持图像的所有4个通道(RGBA)。
imgs = (np.array(imgs) / 255.).astype(np.float32) # keep all 4 channels (RGBA)
poses = np.array(poses).astype(np.float32)
# Python中列表从左侧开始计数,列表的第一个元素的索引是 0,第二个元素的索引是 1,依此类推。
# 负数索引用于从列表的右侧开始计数,其中 -1 表示最后一个元素,-2 表示倒数第二个元素,以此类推。
counts.append(counts[-1] + imgs.shape[0])
all_imgs.append(imgs)
all_poses.append(poses)
# i_split 将包含三个数组,分别对应于训练集、验证集和测试集的索引范围
i_split = [np.arange(counts[i], counts[i+1]) for i in range(3)]
# 使用 np.concatenate 将所有split的图像和姿态合并成两个大数组。 列表中的所有图像数组沿着第一个轴合并成一个单独的数组imgs。
# 参数0指定了合并的轴,即第一个轴,这通常是图像的批次或序列。
imgs = np.concatenate(all_imgs, 0)
poses = np.concatenate(all_poses, 0)
# 提取图像的高度和宽度
H, W = imgs[0].shape[:2]
camera_angle_x = float(meta['camera_angle_x'])
# 根据相机的x轴视角计算焦距
focal = .5 * W / np.tan(.5 * camera_angle_x)
# pose_spherical是前面定义的生成相机位姿矩阵的函数
# 结果是一个包含40个不同位姿变换矩阵的列表
# 注意render_poses和poses的区别,前者是用于渲染新视角图像的相机姿态矩阵,后者是从图像参数中得到的相机位姿
render_poses = torch.stack([pose_spherical(angle, -30.0, 4.0) for angle in np.linspace(-180,180,40+1)[:-1]], 0)
if half_res:
H = H//2
W = W//2
focal = focal/2.
imgs_half_res = np.zeros((imgs.shape[0], H, W, 4))
for i, img in enumerate(imgs):
imgs_half_res[i] = cv2.resize(img, (W, H), interpolation=cv2.INTER_AREA)
imgs = imgs_half_res
# imgs = tf.image.resize_area(imgs, [400, 400]).numpy()
# 返回读取的图像,位姿(相机外参),用于渲染新视角的生成位姿,包含图像高度宽度和焦距的列表(相机内参),不同数据集分割的索引范围
return imgs, poses, render_poses, [H, W, focal], i_split
得到我们需要的数据集之后,可以从数据集中得到相机内参、位姿等信息。然后就可以将参数传入create_nerf()函数创建模型了。
2.创建模型(位置编码)
首先我们明确一下神经网络的输入和输出:
输入:坐标位置x的位置编码和视角向量d的位置编码
输出:坐标位置x的体密度σ以及视线d方向观察时x处的RGB值
如下图,神经网络在某层直接输出了σ信息,因为体密度σ与观察视角无关,在输出σ后神经网络加入r(d)光线方向位置编码,输入下一层神经网络,最终输出RGB信息。RGB值是3维的,每一个值最小是0最大是1。因此除了最后一层激活函数是sigmoid之外其它层都是ReLU。
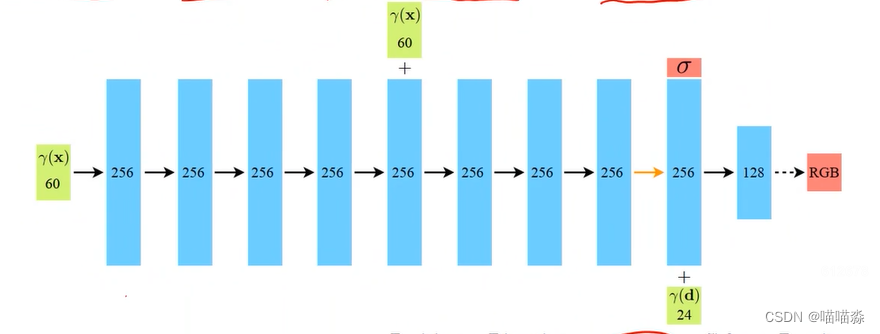
创建模型的部分会涉及到一个重要概念,也就是位置编码:
神经网络并不是直接输入三维坐标,而是把坐标通过一个位置编码函数映射到一个高维空间里输入给神经网络。位置编码函数定义为一系列正弦和余弦函数的组合,正弦和余弦函数是周期性的振荡函数,它们在数学上具有良好的频率特性。通过将输入坐标映射到更高维度的空间,引入了额外的频率信息,使得MLP能够更容易地捕捉到高频变化。这样,即使MLP的层数和神经元数量保持不变,网络也能够更有效地学习和表示复杂的几何和纹理细节。
NeRF中说的空间场景的高频信息的意思是,相邻两个点的体密度相差较大,比如一个点是空气,相邻的一个点是物体上的纹理。体现出突变的情况。我们说的高频信息丢失就是指网络没有学习到这种突变的特性,体现出平滑的特点。也就是说对于两个坐标上相邻的包含高频信息的两个点,尽管它们坐标差异较小,但是我们希望学习到的体密度的差异是比较大的。这个时候神经网络很难抉择,因为在某些情况下我们希望神经网络放大差异,但在大部分情况下,我们希望学习到的信息是平滑的。
通过位置编码,将点的三维坐标映射成高维坐标,坐标特点是在越前面的坐标维度上,两个点的差异越小,越往后的维度上差异越大。这就给神经网络提供了选择,如果它关注两个点坐标前面的维度,就会学习到两个点的差异很小,但如果它关注最后一个维度,就会学习到很大的差异。也就是说在这个高维坐标里,不同的维度使神经网络看到的差异不同,使神经网络有了自适应的调节能力。具体的位置编码公式是:

那么为什么这样可以实现后面的维度是高频的呢?可以画一下sin和cos的图像看看,在前面的维度,由于L的值比较小,在一个固定长度内函数上下摆动的频率较低,但在后面的维度,随着L的值逐渐增大,同样的固定长度内函数的摆动频率高了很多。
这就是位置编码引入高频信息的原理。
在代码实现中,通过create_nerf()函数创建模型,其中调用get_embedder()函数获取位置编码。
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
# 获取3D位置编码的嵌入函数和输入通道数
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
# 初始化不使用视图方向信息作为输入特征
input_ch_views = 0
embeddirs_fn = None
# 如果使用视图方向信息,再生成对应的嵌入函数
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
# 根据是否使用重要性采样(args.N_importance),定义模型的输出通道数。
# 如果使用重要性采样,输出通道数会多出第五个维度,就是累积不透明度/权重,前三个通道是RGB值,第二个通道是体密度
output_ch = 5 if args.N_importance > 0 else 4
# 定义在第四层进行跳跃连接
skips = [4]
# 实例化一个NeRF类
# model.to(device)将模型转换到指定设备上训练,这里指定的是cuda
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
# 获取模型参数,优化器需要一个参数列表,来决定更新哪些变量
grad_vars = list(model.parameters())
model_fine = None
# 如果使用重要性采样的话创建精细模型
# 这里说的重要性采样是在粗网络采样的基础上,对每条射线上的点进行更有依据的采样
if args.N_importance > 0:
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
# 精细模型的参数也要添加到参数列表中
grad_vars += list(model_fine.parameters())
# 执行网络前向传播的一个lambda函数(更精确的说应该是它为网络的前向传播做了数据准备?)
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
在代码中可以看到一个关于是否使用视图方向信息的判断,输入视角向量的重要意义就在于可以学习到物体的反光特性,如下图所示,没有输入视角向量的履带上没有学习到反光的现象,没有位置编码引入高频信息的结果也显而易见。

从神经网络中得到RGB和体密度信息之后就需要根据这些信息进行体渲染了。
3.体渲染(采样策略)
体渲染是视线上所有的点投射到图像上形成像素颜色的过程。
视线表现为ψ和θ两个参数,所有通过摄像机光心的射线都可以用这个参数表达,如下图:
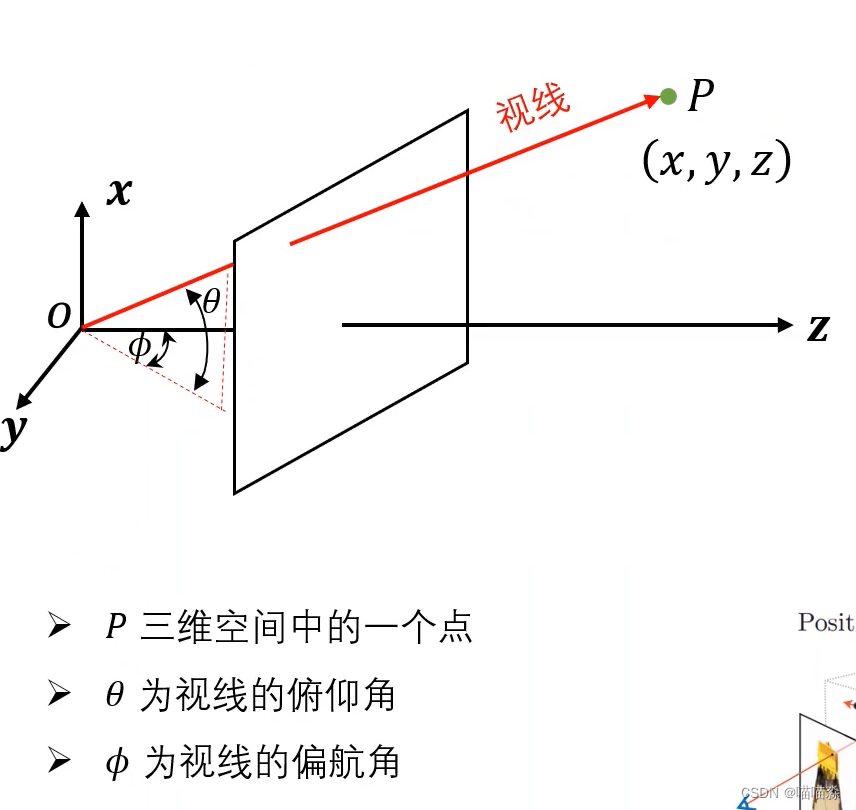
在流程图中我们是用ψ和θ两个参数表示方向,但在实际代码中还是用一个三维向量d表示方向,所以在给定一条光线后,不同的t就代表不同的三维点。

体渲染的公式如下:

积分的原因是要把空间中所有点的信息累积起来,考虑的积分边界是t_n和t_f,这个是根据经验设置好的。在实际代码中我们有两个参数near和far,实际上就是积分的上下限。
c(r(t),d)的值和体密度σ(r(t))的值都是神经网络根据当前三维点的结构信息算出来的。
T(t)表示的是从近点t_n到当前点t的累积透射率,可以理解成光强。实际上就是把这些所有点的吸光材料累加起来,这个积分值可能很大,但我们希望将其控制在0到1范围内便于表达,所以通过变换加上负号取指数,就得到了T(t),由于经过了变换,随着吸光率的累加,T(t)会逐渐减小。
σ反映的是吸收光线的能力,体密度值σ越小,说明光线越容易从这里通过。可以这样去理解体密度σ:从海面上打一束光线,每个点都有一个σ值,空气的部分σ值为0,海平面以下每一个σ值都会吸收一点光线,只要是吸收了光线的点,颜色值就可以被我们看见。在这个过程中光线的强度不断减弱,光线到不了的地方颜色我们是看不见的,光强的概念就可以用T(t)来表示。
在σ或T等于0的时候,该点的颜色就与最终的颜色无关,σ和T越大,当前的c(t)对最终C的贡献就越大,这就是对公式物理含义的理解。
在实际的代码实现过程中,从一组图像中随机生成射线并将其组织成适合批量处理的格式,也就是从图像中获取射线的原点和方向,具体的实现函数是get_rays_np(),选择射线的过程中,要决定是否使用批处理,之后就调用 render 函数渲染给定的射线,实际上底层完成对每个射线渲染操作的是render_rays()函数。
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
network_fn: function. Model for predicting RGB and density at each point
in space.
network_query_fn: function used for passing queries to network_fn.
N_samples: int. Number of different times to sample along each ray.
# 用于返回模型的原始预测数据
retraw: bool. If True, include model's raw, unprocessed predictions.
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
# 由精细模型得到的每条射线的RGB颜色
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
# 视差值,是深度信息的倒数
disp_map: [num_rays]. Disparity map. 1 / depth.
# 由精细模型得到的每条射线累积的不透明度
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
# 如果 retraw 参数为 True,则返回这个值。它包含了模型对沿射线路径的每个采样点的颜色和密度的原始预测。
raw: [num_rays, num_samples, 4]. Raw predictions from model.
# 下面三条是从粗略模型得到的每条射线的RGB颜色、视差值、不透明度
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
# 在重要性采样中,z_std 用于量化采样点的分布情况
# 如果 z_std 值较大,意味着采样点在射线上的分布较为分散;如果 z_std 值较小,意味着采样点较为集中
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
# 从ray_batch中提取各项数据
N_rays = ray_batch.shape[0]
rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each
viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2])
near, far = bounds[...,0], bounds[...,1] # [-1,1]
# 生成一个从0到1的线性空间采样数组
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp:
# 非线性视差采样,采用近处密集、远处稀疏的采样策略。
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
# 线性视差采样,则在逆深度上均匀采样。
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
# 将一维采样位置扩展成与射线批次大小相同的二维数组
z_vals = z_vals.expand([N_rays, N_samples])
# 分层随机采样,对于每个采样间隔(由 lower 和 upper 定义),使用 t_rand 中的随机值来确定该间隔内的具体采样点。
# 通过这种方式,可以在每个间隔内获得一个随机扰动的采样点,而不是简单地在中点采样。
if perturb > 0.:
# get intervals between samples
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
# 检查是否处于测试环境
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
# 根据随机数 t_rand 计算实际的采样位置 z_vals
z_vals = lower + (upper - lower) * t_rand
# 计算三维空间中的采样位置,公式 o+td
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3]
# raw = run_network(pts)
# 将采样点 pts 和视图方向 viewdirs 传递给神经网络 network_fn,获取原始预测 raw。
raw = network_query_fn(pts, viewdirs, network_fn)
# 将原始预测 raw 转换为语义上有意义的输出,如RGB颜色图、视差图和累积不透明度图。
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
# 检查是否使用重要性采样(每个射线上除了基础采样外额外采样的次数)
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
# 计算基础采样点之间的中间位置
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
# 调用sample_pdf执行重要性采样,返回最终样本值
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
# 分离额外采样点
z_samples = z_samples.detach()
# 合并基础采样点和额外采样点
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
# 计算新的采样点位置
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
# 选择网络模型
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
# 将采样点的位置 pts 和观察方向 viewdirs 传递给神经网络模型 run_fn,获取模型输出raw
raw = network_query_fn(pts, viewdirs, run_fn)
# 使用 raw2outputs 函数处理模型的原始输出 raw
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
# 采样点沿射线的标准差
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
# 检查数值错误
# 遍历返回字典中的每个键,检查是否存在 NaN(非数字)或无穷大(inf)值
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret
在体渲染的过程中可以看到NeRF使用的采样策略:
前面说训练基本流程的时候提到,loss实际上就是通过神经网络计算出的颜色值和真值的颜色值相减求误差,但在实际的应用中这样计算每个点的误差反馈给神经网络计算量是很大的,而且射线上大部分区域是空的或是被遮挡的,对最终的颜色没有贡献,所以NeRF采用的是“coarse to fine”的层级采样策略:
在粗网络采样N_c个位置之后,可以根据w_i的值判断这个点对最终颜色的贡献,如果w_i为0的话,就说明这个点是空气或被遮挡点。根据归一化的权重w_i对贡献大的位置多采样,采样N_f个点,单条光线采样总数为N_c+N_f。
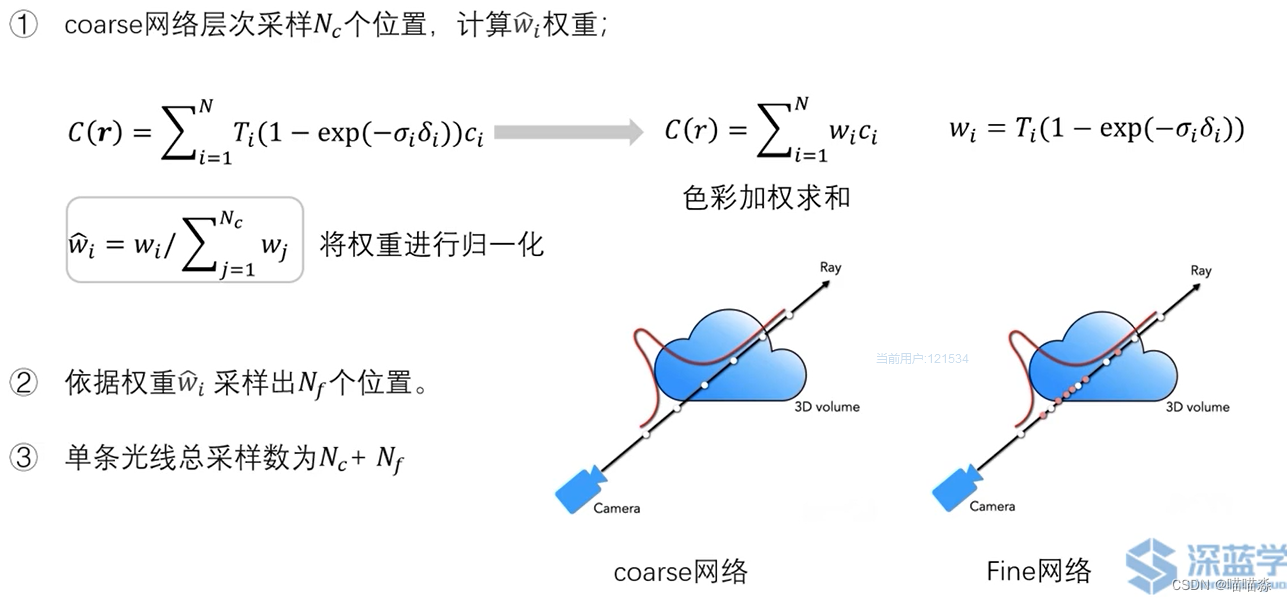
# Hierarchical sampling (section 5.2) 分层采样
# bins:定义了将概率分布分割成多个小区间的边缘 weights:每个区间上的概率权重
# N_samples:要抽取的样本数量 det:如果为 True,则使用确定性采样 pytest:如果为 True,则使用固定的随机数进行测试
def sample_pdf(bins, weights, N_samples, det=False, pytest=False):
# Get pdf
weights = weights + 1e-5 # prevent nans 为了防止权重为0导致的除以0操作出现NaN现象
# 通过将权重除以他们的总和来计算概率密度
pdf = weights / torch.sum(weights, -1, keepdim=True)
# 计算pdf的累积和
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[...,:1]), cdf], -1) # (batch, len(bins))
# Take uniform samples 如果det为True,使用 torch.linspace 生成均匀间隔的样本
if det:
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else: # 否则,使用 torch.rand 生成随机样本
u = torch.rand(list(cdf.shape[:-1]) + [N_samples])
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
new_shape = list(cdf.shape[:-1]) + [N_samples]
if det:
u = np.linspace(0., 1., N_samples)
u = np.broadcast_to(u, new_shape)
else:
u = np.random.rand(*new_shape)
u = torch.Tensor(u)
# Invert CDF
# 逆变换采样是一种常用的从概率分布中抽取样本的方法
u = u.contiguous() # 确保 u 是一个连续的张量,对于 torch.searchsorted 操作是必要的
inds = torch.searchsorted(cdf, u, right=True) # 对于每个样本 u,使用 torch.searchsorted 在 CDF 中找到它应该插入的位置索引
# 计算每个样本的上下边界索引,确保下边界不小于0,上边界不会超过CDF最大索引
below = torch.max(torch.zeros_like(inds-1), inds-1)
above = torch.min((cdf.shape[-1]-1) * torch.ones_like(inds), inds)
# 创建一个包含每个样本上下边界索引的网格
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2)
# cdf_g = tf.gather(cdf, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# bins_g = tf.gather(bins, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# 采集CDF和bins的值
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
# 计算插值比例
denom = (cdf_g[...,1]-cdf_g[...,0])
denom = torch.where(denom<1e-5, torch.ones_like(denom), denom)
# 计算插值位置
t = (u-cdf_g[...,0])/denom
# 使用线性插值计算最终的样本值
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0])
return samples
4.损失函数与训练策略
由于NeRF“coarse to fine”的采样策略,实际的loss函数如下图:

# Misc
# 计算渲染图像 rgb 和目标图像 target_s 之间的均方误差(MSE)损失
img2mse = lambda x, y : torch.mean((x - y) ** 2)
# 用于将均方误差(MSE)转换为峰值信噪比
# PSNR 值越高,表示重建的质量越好
mse2psnr = lambda x : -10. * torch.log(x) / torch.log(torch.Tensor([10.]))
to8b = lambda x : (255*np.clip(x,0,1)).astype(np.uint8)















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









