







目录
一、大模型的“幻觉”究竟有什么意义?
幻觉还会有意义?!您先且慢惊诧……
前不久,OpenAI科学家Andrej Karpathy就发表观点说:
从某种意义上说,大语言模型的全部工作恰恰就是制造幻觉,大模型就是「造梦机」。
(参见:《大模型就是「造梦机」,Karpathy一语惊人!人类才是「幻觉问题」根本原因》)
正如文章所说:“观点惊人,掀起非常激烈的讨论。”然后最近又看到这篇文章,《AI带来“幻觉”,是创意还是误导?》,于是笔者觉得这是个值得说道说道的问题,也因为笔者对创意、创新、创造力、想象力等非常感兴趣,也时常思考这方面的问题。
其实笔者一直认为“幻觉”这个词用在这里并不恰当,之前笔者都是用“低级错误”来指代相应的现象,不过既然行业已经约定成俗,那也只能入乡随俗了。
正如Andrej Karpathy所说,大模型实际上全部工作都是在制造幻觉,因为它们并不知道制造出来的东西是否正确,只是凭着一种“感觉”将这些东西生成出来,而这种感觉则来源于阅读了大量的资料,于是觉得应该如此来生成,至于到底与现实是否相符,那它就不知道了。只不过,也正因为它们阅读了大量的资料,所以生成出来的东西常常与现实是相符的,也就是说它们的感觉基本上还是靠谱的。
然而业界现在所说的幻觉,是指那些明显与事实不符的生成内容,也就是让人一眼看上去就是错误的,比如中午死了的人晚上还活着,或者图片中的人有6个手指等等,所以笔者认为称为“低级错误”是很恰当的。
也有人认为应该称为“杜撰”,从与事实不符这点上说,杜撰是恰当的,但是杜撰往往是指有意制造错误,可是大模型其实并不知道它在制造错误,也就是无意的错误,那么说杜撰就不恰当了,从这点上说,幻觉反而更恰当些。并且存在与幻觉同样的问题,如果说杜撰,那么大模型全部都是在杜撰,生成的正确内容也叫杜撰,似乎不太妥当。
如果说幻觉是指低级错误,那么这种幻觉是没有意义的,错误,尤其是低级错误,怎么可能有意义呢?
但是如果说大模型全部都是在制造幻觉,那就有意义了。从正确性角度说,大模型生成的内容可分为三类:正确的、错误的、无法确定是否正确的。
正确的当然有意义,错误的则没有意义,这两者都没有什么好说的,关键就在于“无法确定是否正确的”,这或许正是大模型最大的意义所在。
笔者曾在文章《点评 | 人工智能“革命”的 “近忧”和“远虑”》中说:
每一种工具的出现都是对于人类某种能力的延伸,比如刀、锄头、锤子的出现是对人手能力的延伸,车辆是对人脚能力的延伸,望远镜是对人眼能力的延伸,电话是对人耳和嘴能力的延伸……,人工智能显然是对人脑能力的延伸,而人脑的主要能力无疑就是思考的能力。
人脑最重要、最难的思考则是创造性思考,即想象出曾经没有的东西,包括观点、理论等,这对人类社会的贡献往往也是最大的。
所谓的创造性往往都是把两个或多个看似没有关系的东西结合在一起,并且是符合逻辑或有实用价值的,比如手机就是将有线电话和无线对讲机结合起来。
由于每个人掌握知识的有限性,以及思考能力不够强大,导致好的创意是一件非常困难的事。同时,随着社会和科技的发展,“较低树枝上的果实基本都被采摘完了”,而且社会分工也越来越细,因为每一个细分领域中的知识都可能需要一个人穷其一生去学习和掌握,人们的知识被限制在了很窄的领域中,像达芬奇那样上知天文、下知地理的博物学家很难再出现,因此看似不相关的跨领域结合也就越来越困难,重大创新则更是罕有。
即使如文章《AI带来“幻觉”,是创意还是误导?》所说,可以多个人一起进行头脑风暴,但几个人的知识广度还是很有限的,且无法达到一个人思考的那种效果。
就在人类的创造性即将走入穷途末路之际,能在这方面提供帮助的有力工具——大模型出现了!
大模型最大的特点就是“大”,它们几乎学习了能找到的所有人类文本资料,为跨相隔很远领域的联系打下了坚实的基础。
然后就轮到我们今天的“主角”出场了,大模型的幻觉,这种幻觉机制允许它将相距遥远的两个东西以我们人类完全想象不到的方式结合在一起,虽然常会有错误,但也可能将我们人类的创造力提升了N个级别,就像汽车、飞机等将人类的相应能力提高到前所未有的程度。
笔者绝不是在这凭空推测,而是有事实为依据的,比如作为一个基本不会写诗、绘画的人,笔者在大模型的帮助下已经写了上千首诗,“创作”了无穷多的图片,比如最新的一首诗如下,图片则是在笔者文字提示下由阿里通义万相大模型生成:

由于笔者的水平还很业余,也许内行的读者会觉得这首诗不怎么样,但这句“无法遗忘在风中把所有遗忘”应该很有创意,至少以笔者的水平是想不出这样的句子,也就说明了大模型可以在创意上给人类提供很大帮助。
当然,这只是个很小的创意,说服力也许还不够,那我们就来看一个大创意,《陶哲轩转赞!ChatGPT自动证明重大突破,10年后AI将称霸数学界》,这篇文章中说:
人工智能技术经常能够「直接地」帮助数学家们「找到」自己想要的答案。
虽然数学家或者AI专家们都搞不清楚AI是如何找到这个答案的。
这充分表明了人工智能大模型能够想到人类数学家们想不到的奇思妙想。
《ChatGPT跌下神坛》,笔者这篇文章则从另一个角度说明了幻觉对创造力的重要性,文章中笔者说更愿意用GPT-2来辅助写诗,而不是用ChatGPT,虽然ChatGPT的幻觉更少,但也更少创意;GPT-2常常胡说八道,但也常常带来意想不到的惊喜,直到现在,笔者仍是使用GPT-2辅助写诗。
由于大模型实际上全部工作都是在制造幻觉,也就是说幻觉是大模型本质上的问题,是不太可能完全解决的,因此大模型始终都会犯低级错误,也就不太可能成为通用人工智能(AGI),即无法达到人类的智能水平,我们也不用害怕人工智能会毁灭人类,至少暂时不用有此担心。
但是大模型可以成为人类的有力助手,从各个方面给我们提供帮助,尤其是在创造力方面,我们应该在各行各业的工作中充分发挥它们的这一长处。
随着发展它们的能力一定会越来越强,或许可以达到人类智能水平的80%,从而进入准通用人工智能(PreAGI)时代,且这很有可能会持续相当长的时间,即便不是永远。
笔者甚至认为,在准通用人工智能时代,也得益于开源的思想,大模型研发领先的国家并不一定会是整体实力最强的,反而是把大模型应用得最好,用大模型激发出各个领域创造力的国家才是这个时代的真正强者。
二、资讯
1、Go 急跳墙,Google 大模型被曝光抄袭百度的文心一言
Google被曝光抄袭百度的文心一言大模型。Google的Gemini API的测试结果表明其使用了文心模型输出的数据进行训练。测试还发现,Gemini会自动识别并模仿文心的角色。然而,Gemini在对齐上存在问题,中文部分几乎未对齐,而英文部分通过打补丁解决。这个事件引发了人们对于数据抄袭和对齐准确性的讨论。
2、OpenAI发布AGI安全风险框架!董事会可随时叫停GPT-5等模型发布,奥特曼也得乖乖听话
OpenAI发布了一项名为AGI安全风险框架的工作,该框架旨在评估和监控模型的安全性。这项工作强调了OpenAI对于模型安全性的关注,并且强调了对未知风险的寻找和预测。该框架包括实时监测与评估、挖掘未知风险、建立安全红线以确保低风险模型的部署以及创建一个跨职能咨询小组等措施。
另外,董事会有权阻止OpenAI发布被认为对人类安全构成威胁的AI模型。然而,一些网友对于OpenAI反复强调安全性持怀疑态度,认为这只是逃避责任的手段。还有人担心安全审查会限制模型能力,降低其效用。最终,技术风险与技术进步之间的平衡仍需时间来评判。
3、「2024年最重要AI图」疯狂热转!开源AI模型正在超越专有模型,LeCun大赞
2024年最重要的AI图表之一显示了开源AI模型正在超越专有模型,LeCun也表示赞赏。图表展示了代表开源模型和闭源模型性能的两条线即将相交的趋势。
开源社区正在推动更易于访问的生成式AI,可能挑战传统的闭源AI开发模式。许多人认为2024年将是开源AI的年份。开源本地模型的崛起正在取代大规模且昂贵的基于云的闭源模型,这将使人工智能平民化,促进更广泛的创新。
欧盟人工智能法案谈判结束,对开源模型给予广泛豁免。Meta和IBM牵头成立了开源联盟,旨在支持开放创新和开放科学,这个联盟由超过50家科技公司、高校和机构共同组成,拥有庞大的研发资金和人才资源。全世界支持开源的人们联合起来了。
4、微软把DALL-E 3集成到键盘,任何APP中都可生图!
微软推出了一项新功能,将DALL-E 3集成到手机键盘中,使用户可以在任何应用程序中快速生成图片。这项功能是通过微软旗下的输入法应用程序Microsoft Swiftkey实现的,该应用程序已集成了New Bing和DALL-E 3。
在键盘上输入提示词:
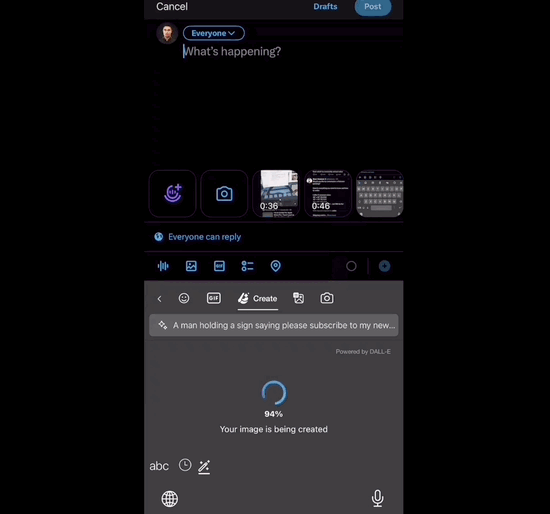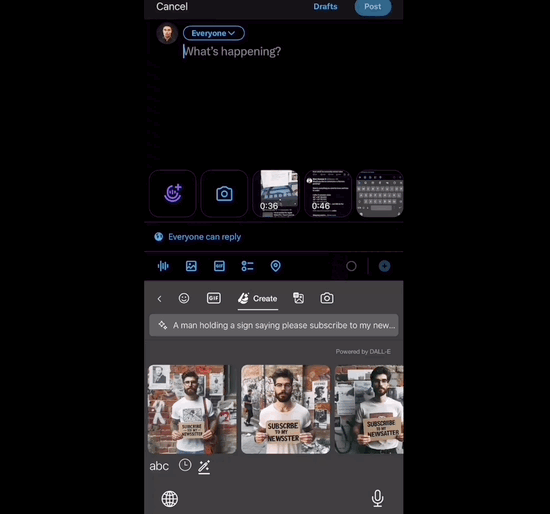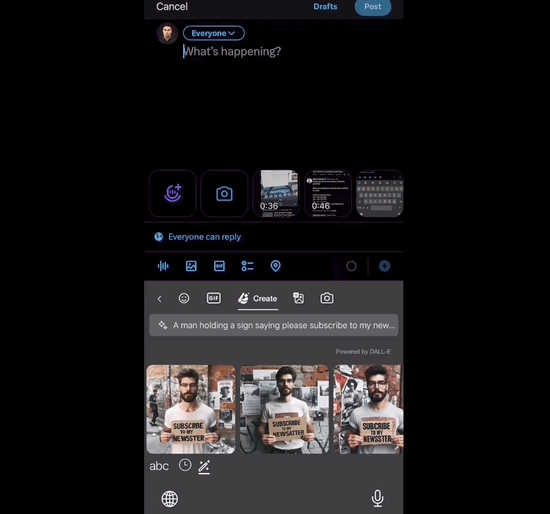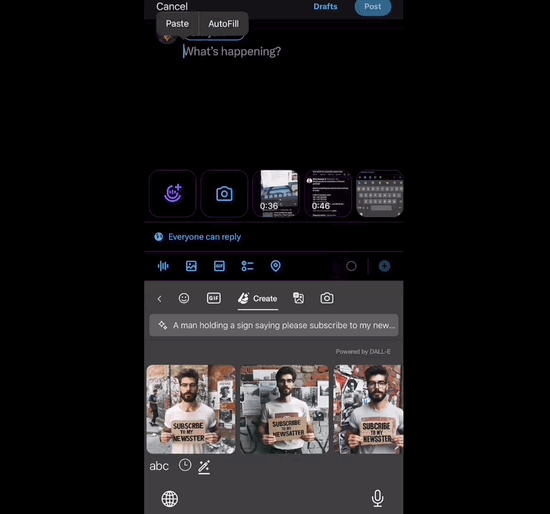
点击Create等上几秒,DALL-E 3生成的图片直接嵌入键盘中,然后就能点击任意图片发送出去:
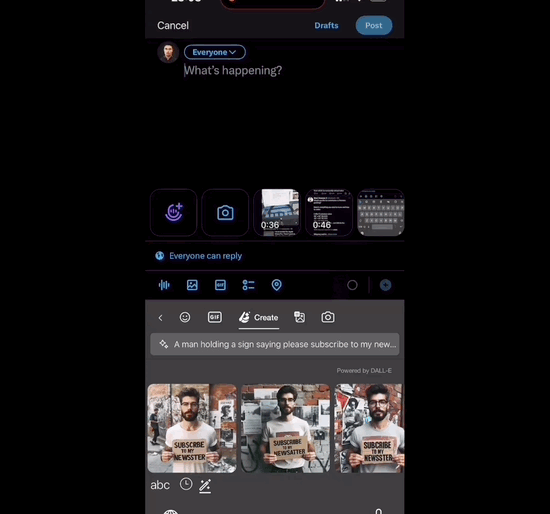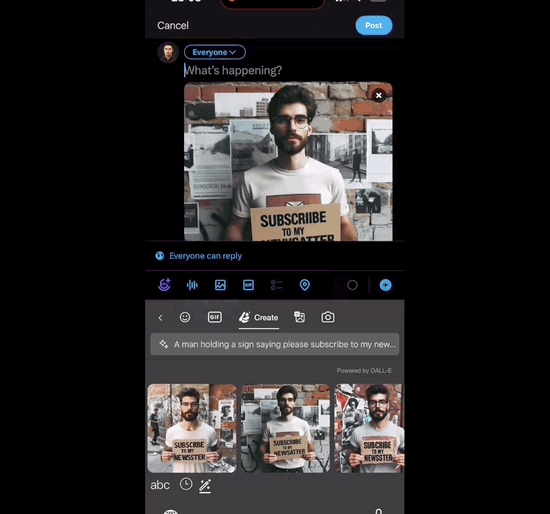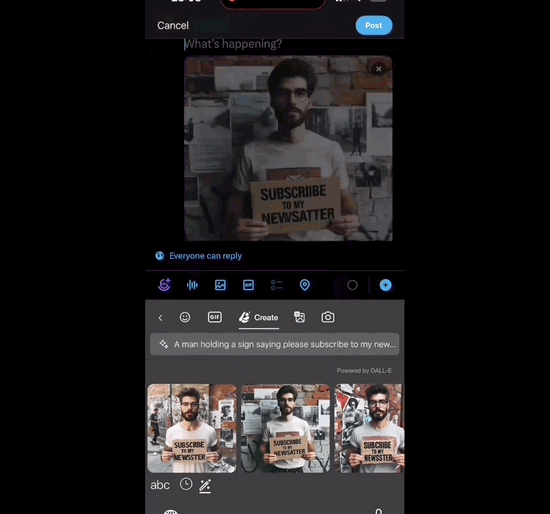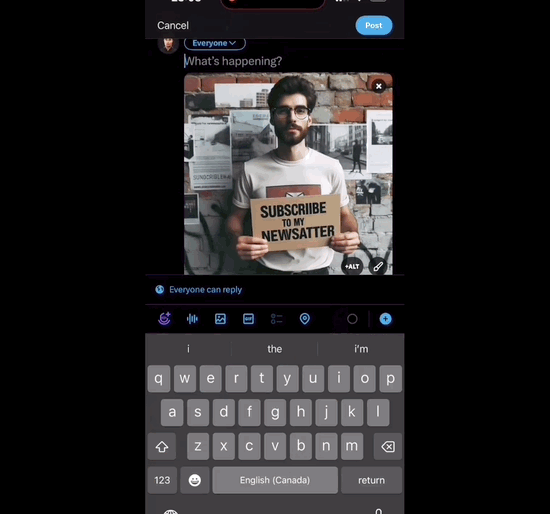
这项功能对于想要更丰富表达的用户来说非常有吸引力。该功能目前可以免费在iOS和Android系统上使用。这一消息在社交媒体上引起了广泛关注和赞誉,人们纷纷表示这是大型科技公司的集成能力的体现,消费者将成为竞争的受益者。
5、OpenAI计划新一轮融资,估值超1000亿美元
OpenAI计划进行新一轮融资,估值预计将超过1000亿美元。据报道,投资者们正在进行初步的讨论,具体的融资条款和时间还未最终确定。
如果这轮融资按计划进行,OpenAI将成为美国第二大初创公司,仅次于SpaceX。这显示出自2022年11月ChatGPT发布以来,人工智能热潮不断升温的趋势。OpenAI已经从微软筹集了130亿美元的资金,并且在AI创业公司中处于领先地位。
此外,其他有前景的AI创业公司也吸引了各路资本的投资。OpenAI还在考虑筹集资金用于通用型人工智能算力,并与阿联酋王室成员控制的G42进行了讨论。这家AI公司的未来一度显示出不确定性,但目前正在重新关注新技术和产品的研发。
6、Midjourney V6迎来大升级:网友惊呼生成效果太逼真
Midjourney V6是一种生成图像的人工智能模型,其生成效果非常逼真,引起了网友们的惊叹。
输入提示:「电影镜头,一个 50 岁留着灰胡子、穿着棕色夹克、戴着红色围巾的黑人男子站在一个 20 岁左右的白人女子旁边,她穿着深蓝和乳白色千鸟格外套,戴着黑色针织帽。午夜,他们走在街道中央,被路灯柔和的橙色光芒照亮。」

Midjourney V6 生成雨中的马斯克:

相比于之前的版本,V6在人物脸部细节刻画、衣服纹理等方面有了明显的提升。新版本的V6允许输入更长的提示,并可以生成更丰富的细节,甚至可以向照片添加文本。
用户可以通过Discord服务器或者Midjourney bot来获得这个新版本。创始人David Holz表示,V6是使用人工智能超级集群从头开始训练的第三个模型,历时九个月开发。设计师Tatiana Tsiguleva表示,V6对提示的理解更准确,不再需要奇怪的短语或单词。
不过目前V6缺少V5.2上的一些功能,但这些功能将在后续更新中提供。
7、自己发基准自己第一,Anyscale行为惹社区吐槽
初创公司Anyscale发布了一个开源的大模型推理基准,但其排行榜引发了争议。一些指标显示Anyscale在不同规模的模型中都排名第一,引发了社区的质疑。
Anyscale的创始人之一是数据巨头Databricks的联合创始人,这也让一些投资者将Anyscale看作是下一个Databricks。然而,一些AI专家和PyTorch的创始人表示,这个基准测试存在问题,没有得到很好的校准。他们认为Anyscale应该咨询其他利益相关者,并更加透明地进行基准测试。这个事件再次引起了人们对“基准游戏”的讨论。
三、研发
1、CMU评测:Gemini Pro相比GPT3.5,全线溃败!代码公开可复现
一项标榜是谷歌史上功能最强大、最通用的多模态模型Gemini 1.0的测评结果引发了争议。
谷歌发布的测评报告声称Gemini Ultra在各种任务上超越了GPT-4,而Gemini Pro与GPT-3.5相当。然而,Gemini Ultra的测评被指存在小动作和合成造假的嫌疑。
此外,来自卡耐基梅隆大学的研究者对Gemini Pro和其他模型进行了深入评估,并公开了可复现的代码和结果。结果显示,Gemini Pro在各项评估任务中不如GPT 3.5 Turbo,离GPT 4 Turbo相差较远。
谷歌回应称Gemini Pro的性能优于GPT 3.5,而更强大的版本Gemini Ultra在内部研究中得分高于GPT 4。然而,谷歌也承认评估的可靠性可能受到数据污染的影响,并表示已尽可能保证结果的科学可靠性。
2、开创全新通用3D大模型,VAST将3D生成带入「秒级」时代
一家名为VAST的初创公司在推动3D生成技术方面取得了突破。传统的3D建模需要专业人员进行手动操作,生成周期长且成本高昂。而VAST的目标是利用生成式AI技术降低3D内容生成的专业知识和成本,让任何人都能创造出令人惊叹的3D内容。

VAST的团队包括来自顶尖高校和技术大厂的算法团队成员,他们拥有丰富的人工智能和图形学经验。文章还提到了VAST与业内巨头合作,推动了一些3D生成技术的突破。AI在3D生成领域仍面临一些挑战,VAST正在努力解决这些问题。
3、再也不怕合照缺人,Anydoor为图片编辑开了一道「任意门」
该项目开发了一种名为"任意门"的图片编辑技术。这项技术允许用户将指定物品从一张照片传送到另一张照片中,实现无缝合成和编辑。

通过使用身份提取特征和细节特征提取技术,Anydoor能够生成逼真且多样化的零样本对象-场景合成。此外,作者还利用视频数据集来训练模型,以提高生成效果的泛化能力。实验结果表明,Anydoor在与其他基于参考图像的编辑方法进行比较时取得了良好的效果。
4、视频生成可以无限长?谷歌VideoPoet大模型上线,网友:革命性技术
谷歌最近发布了一款名为VideoPoet的大模型,被认为是一种革命性的视频生成工具。这个模型可以生成多样化且流畅的动画效果,包括文本到视频、图像到视频、视频风格化和视频修复等任务。
该模型还可以生成音频,并且能够无限扩展生成长视频,默认是 2 秒,通过调节视频的最后 1 秒并预测接下来的 1 秒,这个过程可以无限地重复,以生成任意时长的视频。

视频生成的质量和效果令人惊叹,对于生成连贯的大动作来说,这是一个重要的突破。谷歌还展示了一部由VideoPoet生成的多个短片组成的小短片,以展示该模型的功能。
5、AI读心术震撼登顶会!模型翻译脑电波,人类思想被投屏|NeurIPS 2023
来自GrapheneX-UTS的研究人员在NeurIPS大会上展示了一项令人震撼的应用场景——AI读心术BrainGPT。他们通过一套传感器采样脑电波,并由名为DeWave的AI模型将其翻译成语言,投射到屏幕上。这项研究代表了将原始脑电波直接翻译成语言的开创性努力,标志着该领域的重大突破。

BrainGPT除了可以帮助病患进行交流,还可以实现人与机器之间的无缝通信,如仿生手臂操作。目前,该模型在翻译准确率方面表现良好,且有望进一步提高。这项技术的发展将为神经科学和人工智能开辟新的领域。
6、Meta翻译大模型可模仿语气语速!AI再也不“莫得感情”了|GitHub 9k标星
Meta发布了一系列AI翻译大模型,实现实时语音转换,延迟不超过2秒,并且具备语气、语速等复制功能,让AI翻译更加富有表现力。
该模型采用非自回归架构,提供多种型号可选,并通过EMMA算法实现快速而准确的实时翻译。此外,Meta还解决了翻译准确性和滥用风险的问题,通过过滤训练数据和添加音频水印来保证翻译质量和追踪来源。该系列模型在GitHub上获得了广泛的关注和使用。
7、14秒就能重建视频,还能变换角色,Meta让视频合成提速44倍
Meta发布了一种名为"Fairy"的视频合成技术,可以在14秒内重建一个4秒长的512×384分辨率的视频,比之前的方法快44倍。Fairy利用基于锚点的跨帧注意力机制,确保合成视频在时间上保持一致性和高保真度。

Fairy可以根据文本指令进行不同类型的视频编辑,包括风格化、角色变化等。实验结果显示,Fairy生成的视频质量更好,受到用户的欢迎。该技术对于视频编辑和内容创建应用具有重要意义。
8、OpenAI反复修补未果的ChatGPT数据泄露漏洞是什么?
安全研究员Johann Rehberger于2023年4月发现了一种从ChatGPT窃取数据的方法,并报告给了OpenAI,但未得到回复。之后,他于12月公开披露了漏洞详情。
GPTs是一种定制化人工智能模型,被称作“AI应用”,并可提供给其他人使用。研究员展示了一个名为“小偷!”(The Thief!)的自定义GPT模型,一旦有人使用这个模型,对话详情以及元数据(时间戳、用户ID、会话ID)和技术数据(IP地址、用户代理字符串)便会外泄到由定制模型者操控的外部网址。
OpenAI随后采取了缓解措施,通过调用验证API执行了客户端检查。然而,研究人员指出这些措施并不完美,在某些情况下攻击者仍然可以利用漏洞。
此外,iOS端应用还未进行安全检查,存在攻击风险。目前尚不清楚修复方案是否已经应用于ChatGPT的安卓应用程序。
9、用生物脑机制启发持续学习,让智能系统适者生存,清华朱军等团队研究登Nature子刊封面
传统的机器学习模型在面对动态开放环境时,学习新东西常常出现记忆遗忘的问题。为了解决这个问题,研究人员借鉴了生物脑的学习机制,利用贝叶斯方法建模了生物学习记忆系统的适应性机制,并将其应用于深度神经网络中,显著提升了网络的持续学习能力。
研究人员还构建了类似果蝇学习记忆系统的多模块结构,通过对记忆的有选择性保护和遗忘,使不同模块能够适应不同任务的数据分布差异。在多个持续学习基准实验中,所提出的方法都取得了显著的效果。研究人员的工作为智能系统在动态开放环境中的持续学习提供了新的思路和方法。
四、自动驾驶
1、苏州跑出港股“自动驾驶第一股”知行科技正式挂牌
知行科技是一家专注于自动驾驶解决方案的企业,最近在香港交易所上市。
作为中国第二大自动驾驶域控制器提供商,知行科技占据市场份额的26.2%。根据数据预测,中国自动驾驶市场到2035年规模将超过11000亿元,自动驾驶域控制器市场也将快速增长。
知行科技计划发行2211.6万股H股,募得的资金将用于研发、扩大销售和服务网络等。它已拥有商业化成熟的自动驾驶解决方案,并获得多家主机厂定点函。营收持续增长,2020年至2022年分别为0.48亿元、1.78亿元和13.26亿元,今年上半年达到5.43亿元,同比增长51.3%。知行科技有望在全球智能电动出行产业中取得成功。
2、福田汽车获得国内首张商用车有条件自动驾驶高快速路测试牌照
得益于《北京市智能网联汽车政策先行区有条件自动驾驶功能汽车道路测试管理细则(试行)》政策的出台,为自动驾驶技术的应用带来了利好。福田汽车率先获得该牌照,说明其在自动驾驶技术上具备了许多功能,并推动了商用车领域自动驾驶的发展。

福田汽车自2015年以来一直致力于自动驾驶的研发,已陆续研发了自动驾驶VAN、公交、列队跟驰和重卡等车型。

此次牌照的获得不仅肯定了福田汽车的投入和努力,也代表了我国商用车自动驾驶商业化落地的重要一步。
















 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











