







1.代码
# 第一步:数据预处理
import pandas as pd
import numpy as np
# 导入数据集
dataset = pd.read_csv(r'D:\Python\100-Days-Of-ML-Code-master\datasets\50_Startups.csv')
X = dataset.iloc[:, :-1].values
Y = dataset.iloc[:, 4].values
# 将类别数据数字化
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
labelencoder = LabelEncoder()
X[:, 3] = labelencoder.fit_transform(X[:, 3])
ct = ColumnTransformer([("encoder", OneHotEncoder(), [3])], remainder='passthrough')
X = ct.fit_transform(X)
# 躲避虚拟变量陷阱
X = X[:, 1:]
# 拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 第二步:在训练集上训练多元线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, Y_train)
# 第三步:在测试集上预测结果
y_pred = regressor.predict(X_test)
# 测试集结果可视化
import matplotlib.pyplot as plt
m = np.arange(0, 10)
plt.scatter(m, Y_test, color='red')
plt.plot(m, y_pred, color='blue')
plt.show()
2.函数学习
什么是虚拟变量陷阱?
当由 one-hot 编码创建的两个或多个虚拟变量高度相关(多重共线)时,就会出现虚拟变量陷阱。这意味着可以从其他变量中预测一个变量,从而难以解释回归模型中的预测系数变量。换言之,由于多重共线性,虚拟变量对预测模型的个体影响无法很好地解释。
使用 one-hot 编码方法,为每个分类变量创建一个新的虚拟变量,以表示分类变量的存在 (1) 或不存在 (0)。例如,如果树种是由值橡树或松树组成的分类变量,则可以通过将每个变量转换为 one-hot 向量将树种表示为虚拟变量。这意味着为每个类别获得一个单独的列,其中第一列表示树是否为松树,第二列表示树是否为橡树. 如果所讨论的树属于该列的物种,则每列将包含 0 或 1。这两列是多重共线的,因为如果一棵树是松树,那么我们就知道它不是橡树,反之亦然。
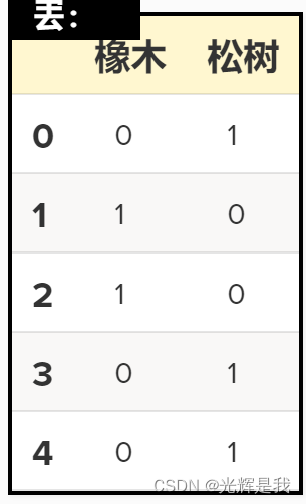

解决办法:
删除生成的虚拟变量其中一列














 4366
4366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









