







Image-to-Image Translation with Conditional Adversarial Networks
文章目录
前言
Image-to-Image Translation with Conditional Adversarial Networks源自于2017年CVPR,主要是针对GAN存在的一些问题,提出了一个“图像到图像的转换”的通用框架。
论文地址:https://arxiv.org/abs/1611.07004

一、Image-to-Image Translation
图像处理、计算机图形学和计算机视觉导论等等都可以理解为是Image-to-Image Translation,目前对于图像到图像间的转换问题有多种实现方法,例如encoder-decoder、GAN等网络框架均可实现,但是每个任务都是用不同的网络框架,不同的损失函数,尽管目标都是用像素去预测像素,但是都需要专门设定损失函数。针对这个问题,提出一个“图像到图像转换”的通用框架(general-purpose solution)。

二、网络框架
生成器使用了“U-Net”结构,而判别器使用了卷积“PatchGAN”分类器。
1.生成器
(1)U-Net结构图

(1)U-Net网络是一个经典的全卷积网络,网络的输入是572 * 572的图像,输出是一张388 * 388的图像。将输入的image经过两次3 * 3的卷积操作后,在进行一次2 * 2的最大池化操作,完成一次下采样的过程,总共需要完成四次这样的过程。图像的channel变化过程是:1—>64—>128—>256—>512—>1024。接下来进行反卷积,实现上采样过程。这里需要注意的是在上采样过程中左边相同尺寸的feature map会和上采样得到的feature map进行拼接处理。
(2)短连接的作用:在下采样的过程中会丢失一部分信息特征,通过这种短连接的方式,可以补全中间丢失的一些信息,从而可以保证精度。
(3)为什么生成器网络选用U-Net?
对于图像转换的问题,在输入输出之间存在很多可以共享的低级信息,即输入输出图像的外表面可以不同,但一定存在潜在的相似结构。在网络中的表现就是跳连接,而U-Net就存在很多的跳连接。生成器采用U-Net,这是在图像分割领域应用非常广泛的网络结构,能够充分融合特征,保留必要信息不变。
2.判别器
判别器D使用了PatchGAN的判定方式,用来判别感受野是N×N的局部patch是真还是假。
通常判断都是对生成样本整体进行判断,比如对一张图片来说,就是直接看整张照片是否真实。如果网络的输出是1 * 1,那么它对应的感受野就是原图(这个地方好好理解一下), 通过1 * 1的输出来判断原图的真假。
而且Image-to-Image Translation中很多评价是像素对像素的,所以在这里提出了分块判断的算法,在图像的每个块上去判断是否为真,最终平均给出结果。本中判别器的输出是30 * 30大小,相当于900个像素,每个像素感受野对应的是原图的70 * 70的patch,含义对应原图的900个70 * 70的patch是真是假(patch有重叠)。
总结一下就是之前的判别网络用输出1 * 1 的结果来判断图像的真假,而现在PatchGAN采用输出30 * 30的特征图来统计判断图像的真假。
三、损失函数
(1)GAN学习的就是一个区分真实和伪造图像的loss函数,同时训练一个生成模型来最小化这个loss函数。条件GAN是学习一个条件生成模型,使得CGAN适应于图像转换的问题,我们在输入图像上设置条件,从而可以得到相应的输出图像。
(2)GAN的损失就是一个博弈过程,判别器想最大化损失(max),生成器想最小化损失(min)。
(3)条件GAN的损失:
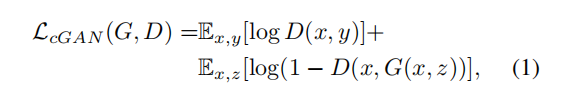
L1的损失函数:
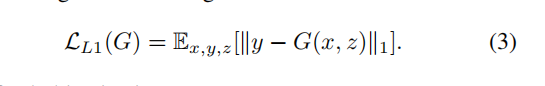
L1损失函数,也称为最小绝对值偏差,具有较强的鲁棒性。
总的损失函数:
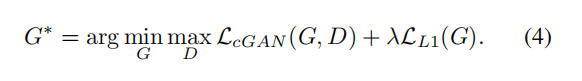
(4)不同的损失函数有着不同的实验结果,只有L1损失函数输出比较的模糊,只有CGAN图像的比较清晰,但是出现了视觉伪像,L1+CGAN生成的图像比较清晰。

(5)选用L1损失作为约束项能够更好地恢复图像的低频信息,使得生成图片更加接近真实图片,也可以更加接近输入的条件图片。通过上图也可以清晰的看到L1+CGAN的结合使得生成的图像更加的真实,更加符合人眼的主观感受。
总结
每次写一篇都是为了让自己可以有更深的思考,当然也希望你们能读懂。
总结一下这篇论文的主要思想就是想使用一个通用的网络框架来实现像素的预测。这里生成器采用了U-Net网络,判别器采用了PatchGAN,损失函数使用了CGAN+L1。里面的知识点有很多值得我们仔细的推敲。
自己理解的可能有些偏差,有问题欢迎指正!
参考文献
[1]https://blog.csdn.net/qq_16137569/article/details/79950092
[2]https://cloud.tencent.com/developer/article/1089012
[3]https://zhuanlan.zhihu.com/p/24248684















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









