






Part1 论文阅读与视频学习
MobileNet V1 & V2
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
网络中的亮点:Depthwise Convolution(DW)大大减少运算量和参数数量;增加超参数α、β。
DW卷积与传统卷积的区别:
传统卷积:卷积核channel=输入特征矩阵channel;输出特征矩阵channel=卷积核个数
DW卷积:卷积核channel=1;输入特征矩阵channel=卷积核个数=输出特征矩阵channel
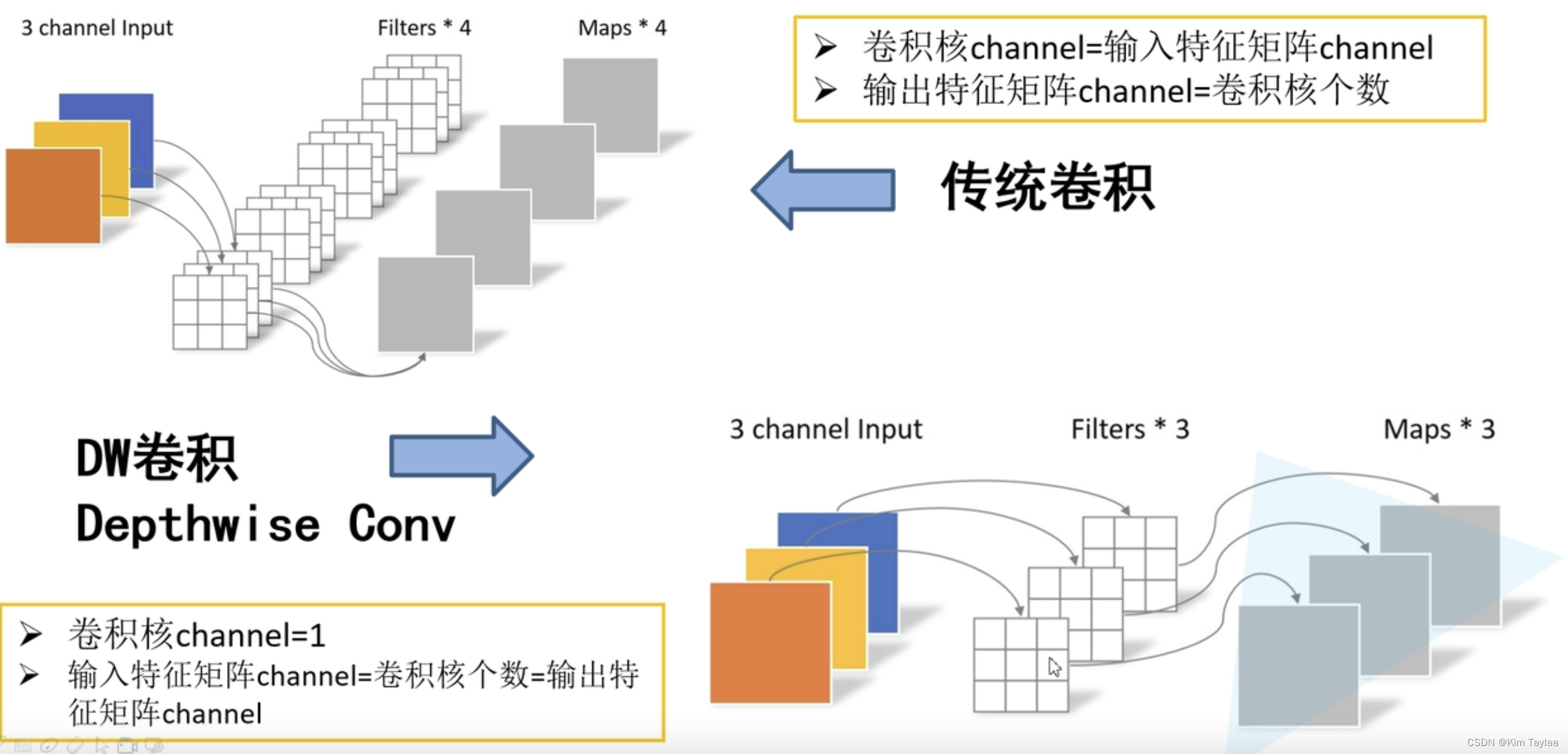
深度可分卷积Depthwise Separab Conv:DW+PW(卷积核大小为1)

理论上普通卷积计算量是DW+PW的8到9倍。
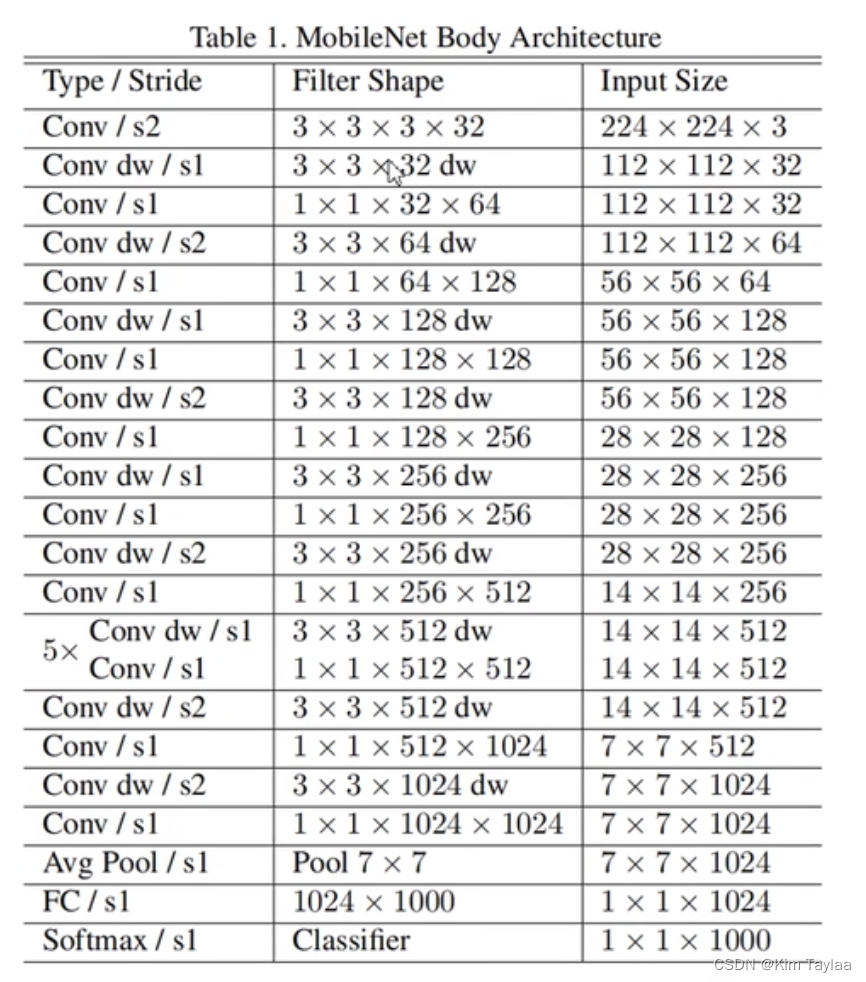
MobileNet网络结构:
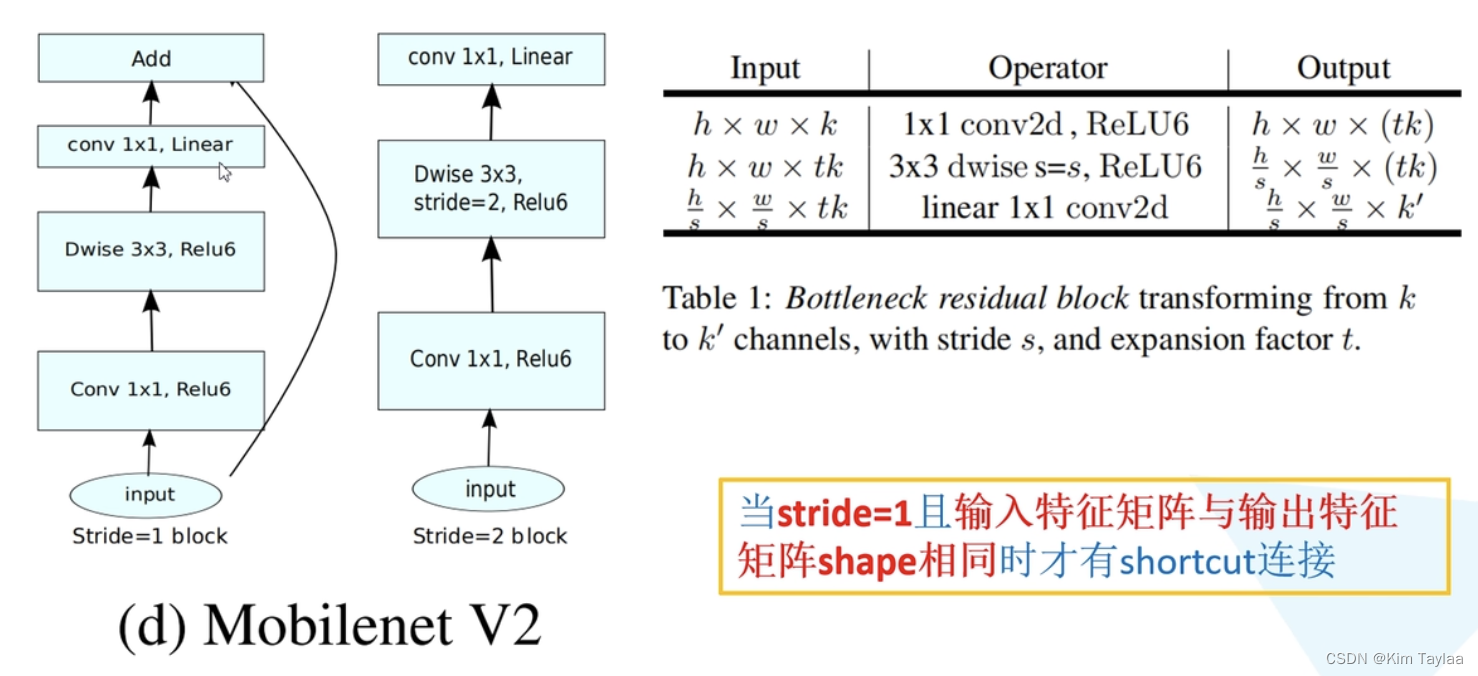
 MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
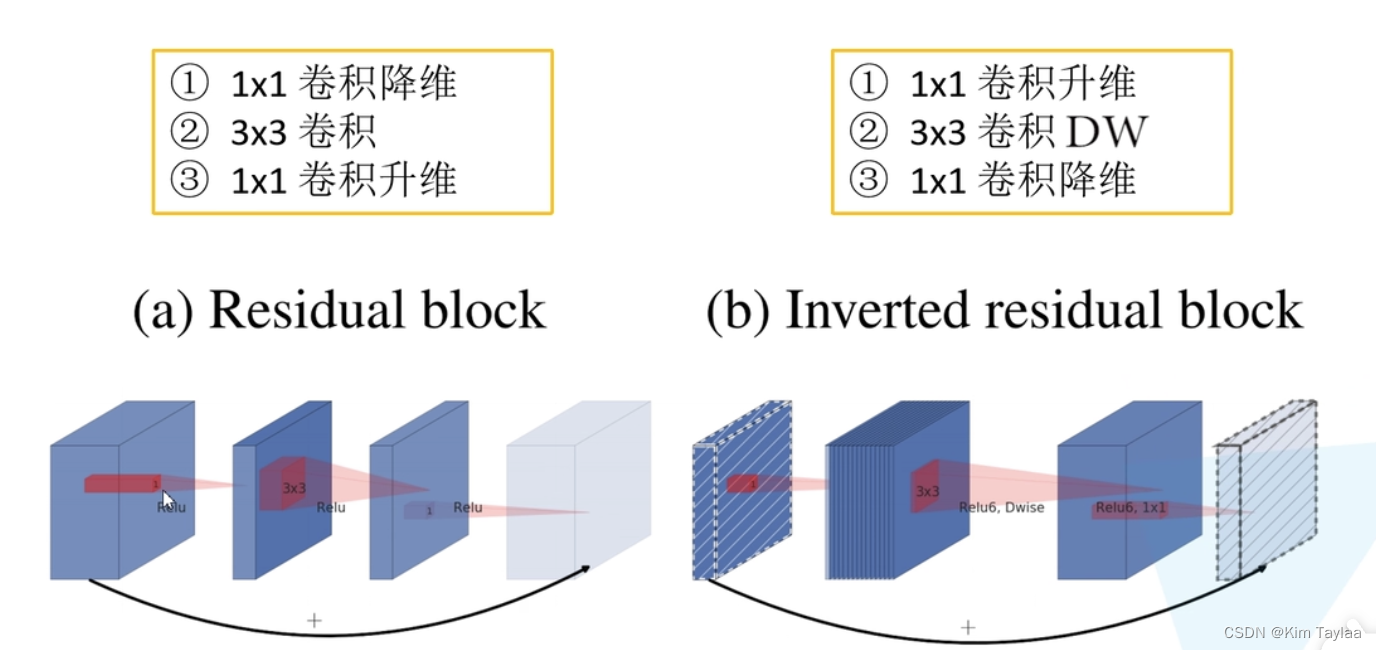
网络中的亮点:Inverted Residuals(倒残差结构);Linear Bottlenecks。
倒残差结构:
ReLU6结构:
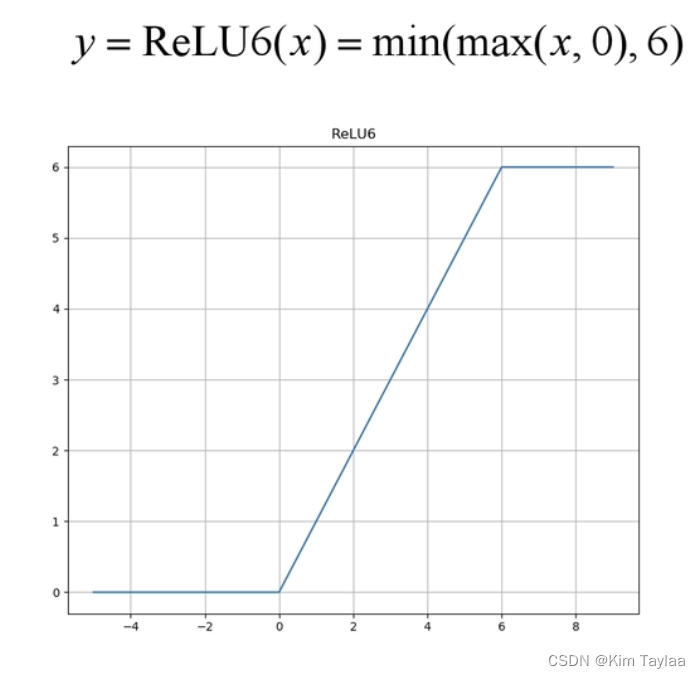
ReLU激活函数对低维特征信息造成大量损失,因为倒残差结构输出是低维的,所以采用线性激活函数来避免损失。
MobileNet v2网络结构:
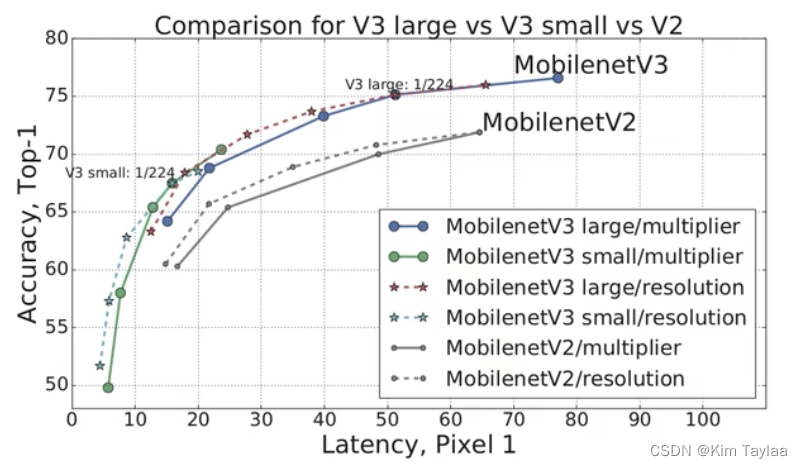
MobileNet V3
MobileNet V3亮点:更新Block(bneck);使用NAS搜索参数;重新设计耗时层结构。
MobileNet V3 block结构: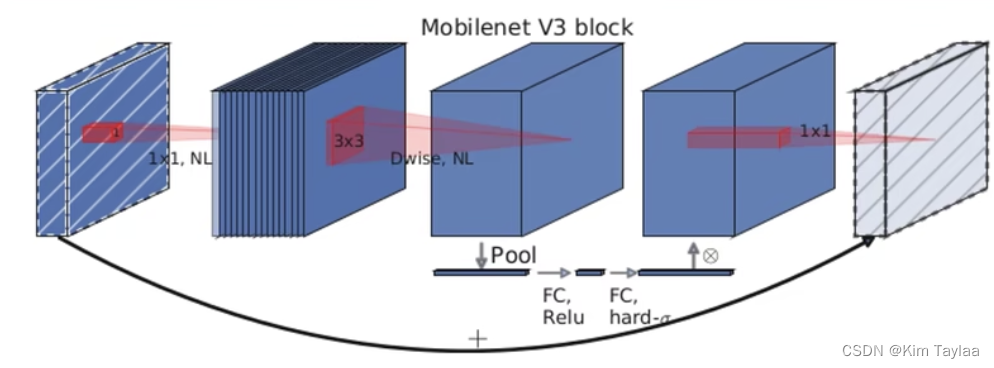
MobileNet V3 中新加入的S1结构:

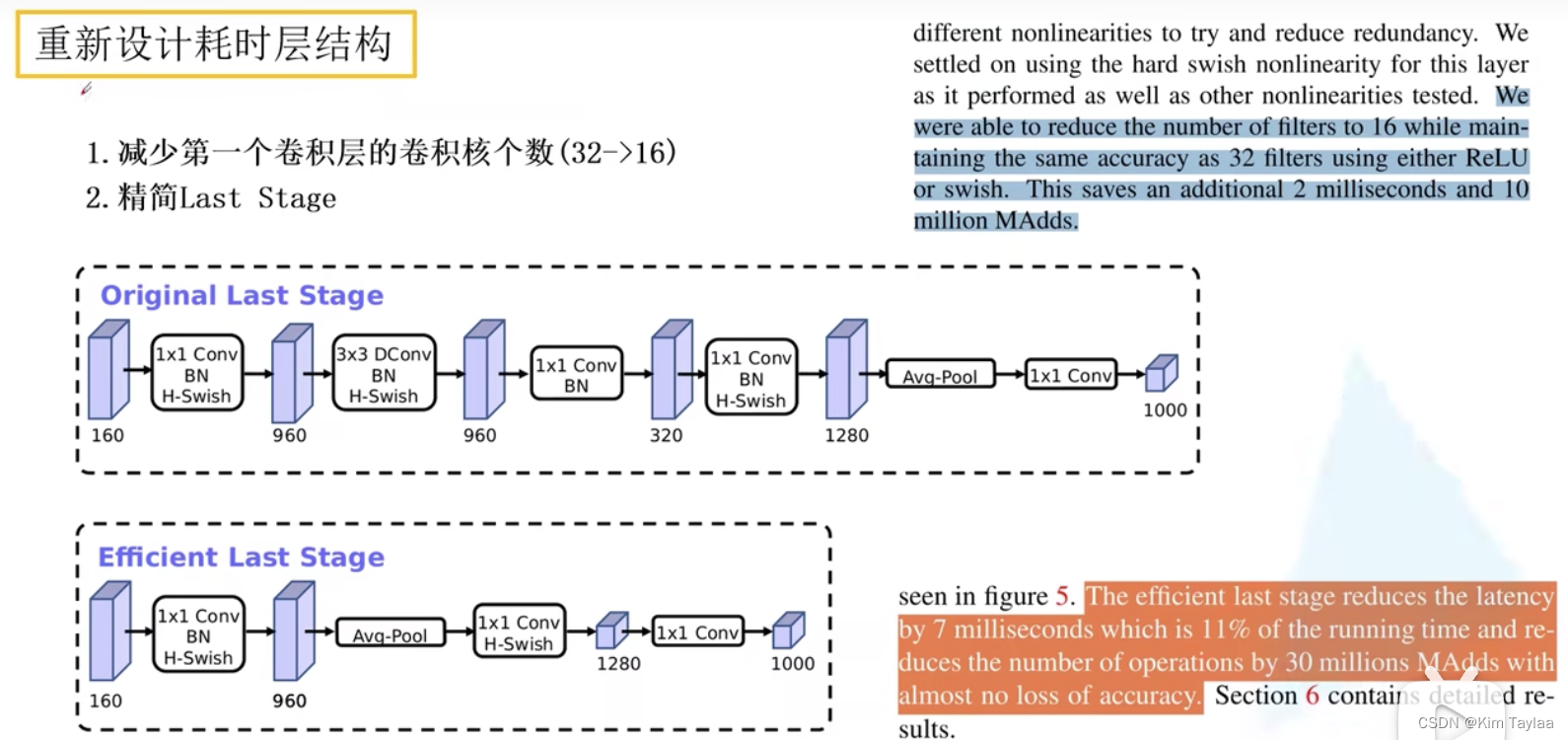
重新设计耗时层结构:
1.减少第一个卷积层的卷积核个数(32->16)
2.精简Last Stage
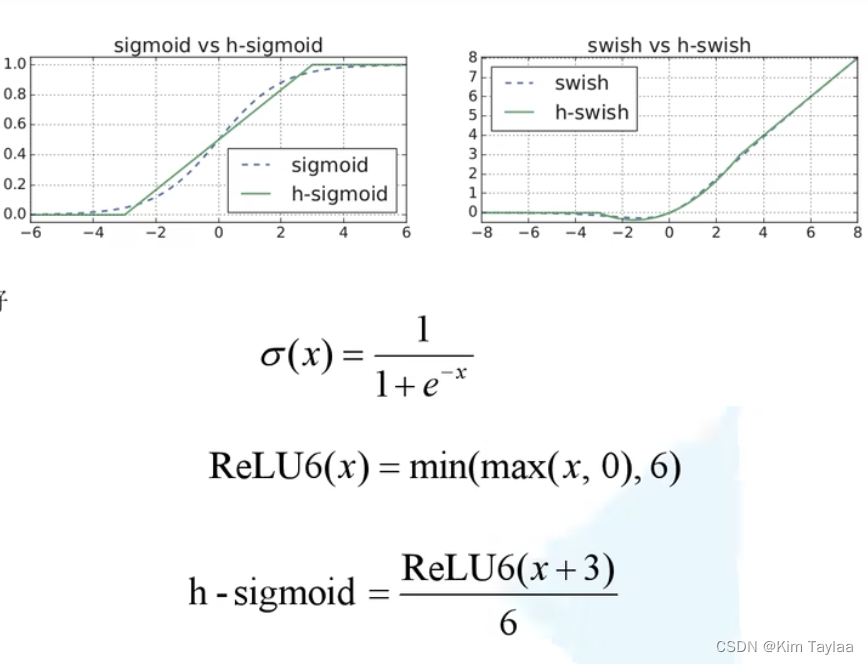
重新设计激活函数:
因为swish函数计算、求导复杂、对量化过程不友好,所以提出h-swish函数。
SE-Net详解
胡杰等人考虑了特征通道之间的关系,并基于这一点提出了Squeeze-and-Excitation Networks (简称SENet)。在此结构中,Squeeze 和 Excitation 是两个非常关键的操作,可以显式地建模特征通道之间的相互依赖关系。另外,该结构采用了一种全新的“特征重标定”策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
SE 模块的示意图:给定一个输入,其特征通道数为,通过一系列卷积等一般变换后得到一个特征通道数为的特征。与传统的CNN不一样的是,接下来我们通过三个操作来重标定前面得到的特征。

1.Squeeze 操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。
2.Excitation 操作,通过参数来为每个特征通道生成权重。
3.Reweight的操作,将Excitation的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
将SE模块嵌入到Inception结构:
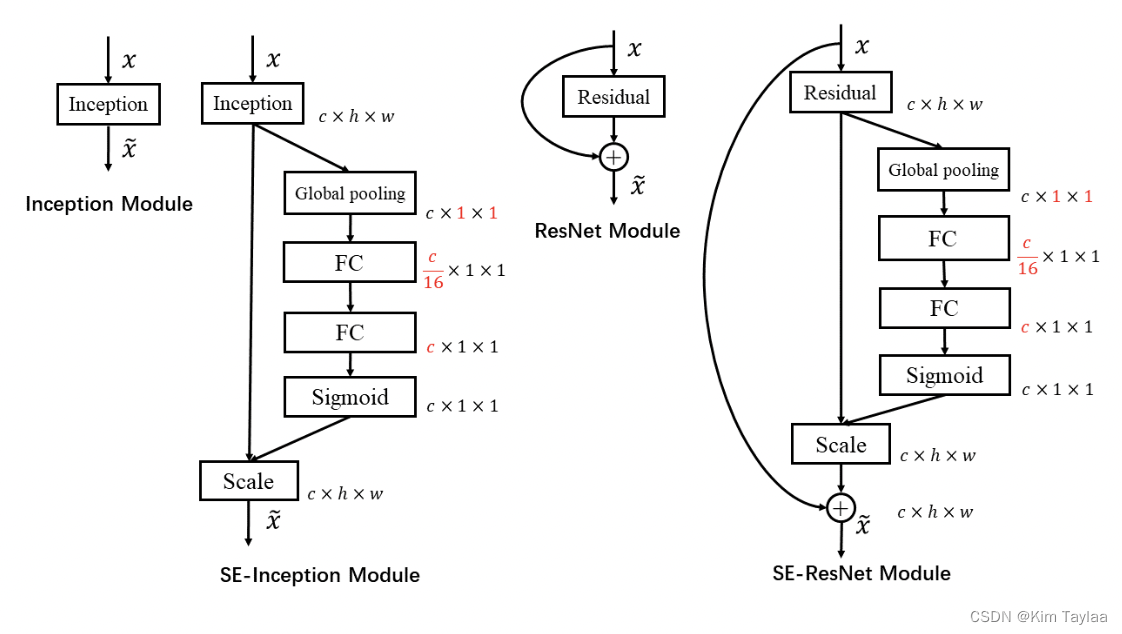 使用global average pooling 作为Squeeze 操作,紧接着两个Fully Connected 层组成一个Bottleneck结构去建模通道间的相关性,并输出和输入特征同样数目的权重。首先将特征维度降低到输入的1/16 ,然后经过ReLu激活后再通过一个Fully Connected 层升回到原来的维度。
使用global average pooling 作为Squeeze 操作,紧接着两个Fully Connected 层组成一个Bottleneck结构去建模通道间的相关性,并输出和输入特征同样数目的权重。首先将特征维度降低到输入的1/16 ,然后经过ReLu激活后再通过一个Fully Connected 层升回到原来的维度。
SENet在single-crop上表现出了最好的性能:

 Part2 代码作业
Part2 代码作业
HybridSN高光谱分类
高光谱图像分类广泛应用于遥感图像的分析。高光谱图像包括不同波段的图像。卷积神经网(CNN)是一种常用的基于深度学习的视觉数据处理方法。CNN用于HSI分类的使用在最近的文章中也可以看到。这些方法大多基于2D-CNN,然而,HSI分类性能高度依赖于空间和光谱信息。由于计算复杂度的增加,很少有方法利用3D-CNN。该文提出了一种用于HSI分类的混合光谱卷积神经网络(HybridSN)。基本上,HybridSN是一个光谱-空间 3D-CNN,然后是空间 2D-CNN。3D-CNN促进了从光谱波段堆栈的联合空间-光谱特征表示。在3D-CNN之上的2D-CNN进一步学习了更抽象的层次空间表示。此外,使用混合CNN比单独使用3D-CNN降低了模型的复杂性。
首先取得数据,并引入基本函数库:
! wget http://www.ehu.eus/ccwintco/uploads/6/67/Indian_pines_corrected.mat
! wget http://www.ehu.eus/ccwintco/uploads/c/c4/Indian_pines_gt.mat
! pip install spectral
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report, cohen_kappa_score
import spectral
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
定义HybridSN类
模型的网络结构为如下图所示:
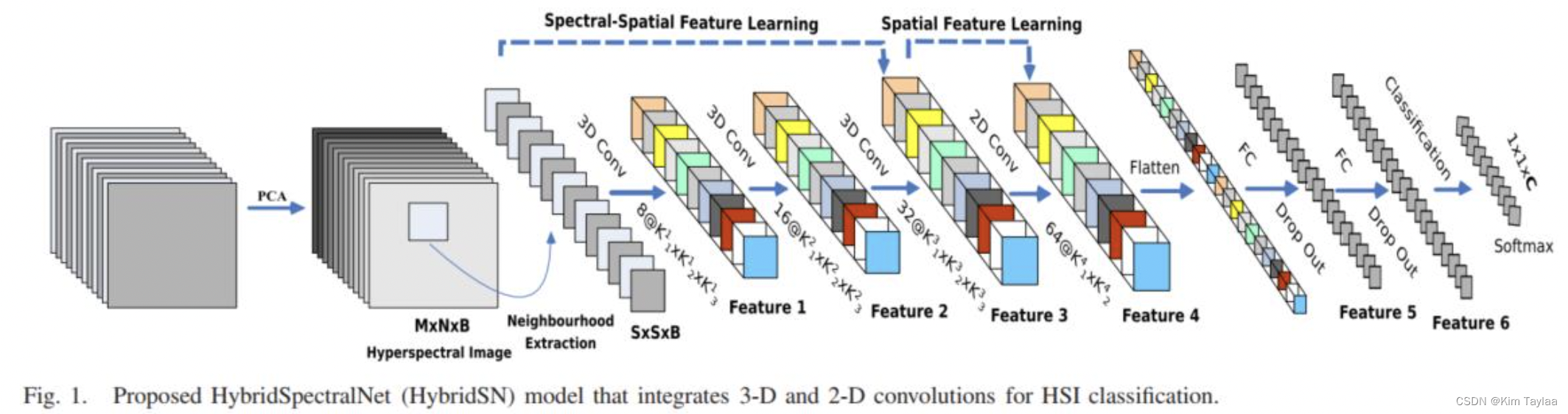
三维卷积部分:
- conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,最后输出为 16 个节点,是最终的分类类别数。
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
#conv1:(1, 30, 25, 25),8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
self.conv1 = nn.Sequential(
nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True)
)
#conv2:(8, 24, 23, 23),6个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
self.conv2 = nn.Sequential(
nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True)
)
#conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
self.conv3 = nn.Sequential(
nn.Conv3d(in_channels=16, out_channels=32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True)
)
#接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
#二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=576, out_channels=64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
#接下来是一个 flatten 操作,变为 18496 维的向量,其中18496 = 64*17*17
#接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
#最后输出为 16 个节点,是最终的分类类别数。
self.fc1 = nn.Linear(in_features=18496, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=class_num)
self.drop = nn.Dropout(p=0.4)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = out.reshape(out.shape[0], -1, 19, 19)
out = self.conv4(out)
out = out.reshape(out.shape[0],-1)
out = F.relu(self.drop(self.fc1(out)))
out = F.relu(self.drop(self.fc2(out)))
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)创建数据集
首先对高光谱数据实施PCA降维;然后创建 keras 方便处理的数据格式;然后随机抽取 10% 数据做为训练集,剩余的做为测试集。
首先定义基本函数:
# 对高光谱数据 X 应用 PCA 变换
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
# 对单个像素周围提取 patch 时,边缘像素就无法取了,因此,给这部分像素进行 padding 操作
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
# 在每个像素周围提取 patch ,然后创建成符合 keras 处理的格式
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
# 给 X 做 padding
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test下面读取并创建数据集:
# 地物类别
class_num = 16
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
# 用于测试样本的比例
test_ratio = 0.90
# 每个像素周围提取 patch 的尺寸
patch_size = 25
# 使用 PCA 降维,得到主成分的数量
pca_components = 30
print('Hyperspectral data shape: ', X.shape)
print('Label shape: ', y.shape)
print('\n... ... PCA tranformation ... ...')
X_pca = applyPCA(X, numComponents=pca_components)
print('Data shape after PCA: ', X_pca.shape)
print('\n... ... create data cubes ... ...')
X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size)
print('Data cube X shape: ', X_pca.shape)
print('Data cube y shape: ', y.shape)
print('\n... ... create train & test data ... ...')
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio)
print('Xtrain shape: ', Xtrain.shape)
print('Xtest shape: ', Xtest.shape)
# 改变 Xtrain, Ytrain 的形状,以符合 keras 的要求
Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1)
Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1)
print('before transpose: Xtrain shape: ', Xtrain.shape)
print('before transpose: Xtest shape: ', Xtest.shape)
# 为了适应 pytorch 结构,数据要做 transpose
Xtrain = Xtrain.transpose(0, 4, 3, 1, 2)
Xtest = Xtest.transpose(0, 4, 3, 1, 2)
print('after transpose: Xtrain shape: ', Xtrain.shape)
print('after transpose: Xtest shape: ', Xtest.shape)
""" Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
# 创建 trainloader 和 testloader
trainset = TrainDS()
testset = TestDS()
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=2)
开始训练:
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 网络放到GPU上
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 开始训练
total_loss = 0
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')
模型测试:
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)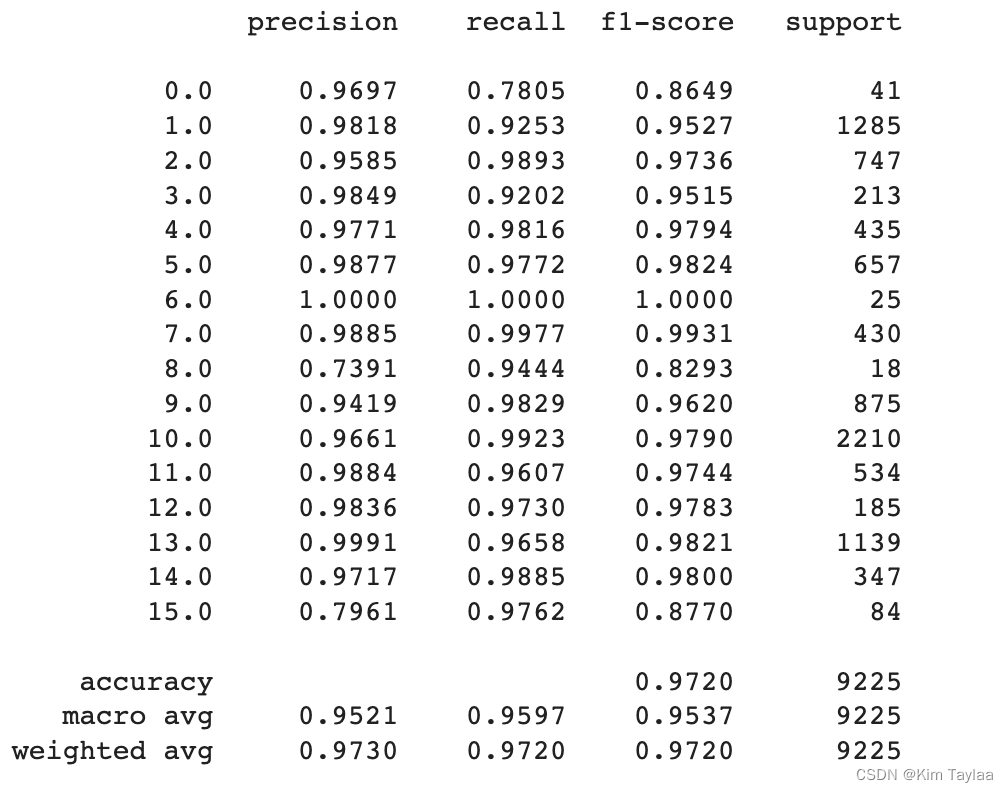
准确率为97.2%。
Part3 问题思考
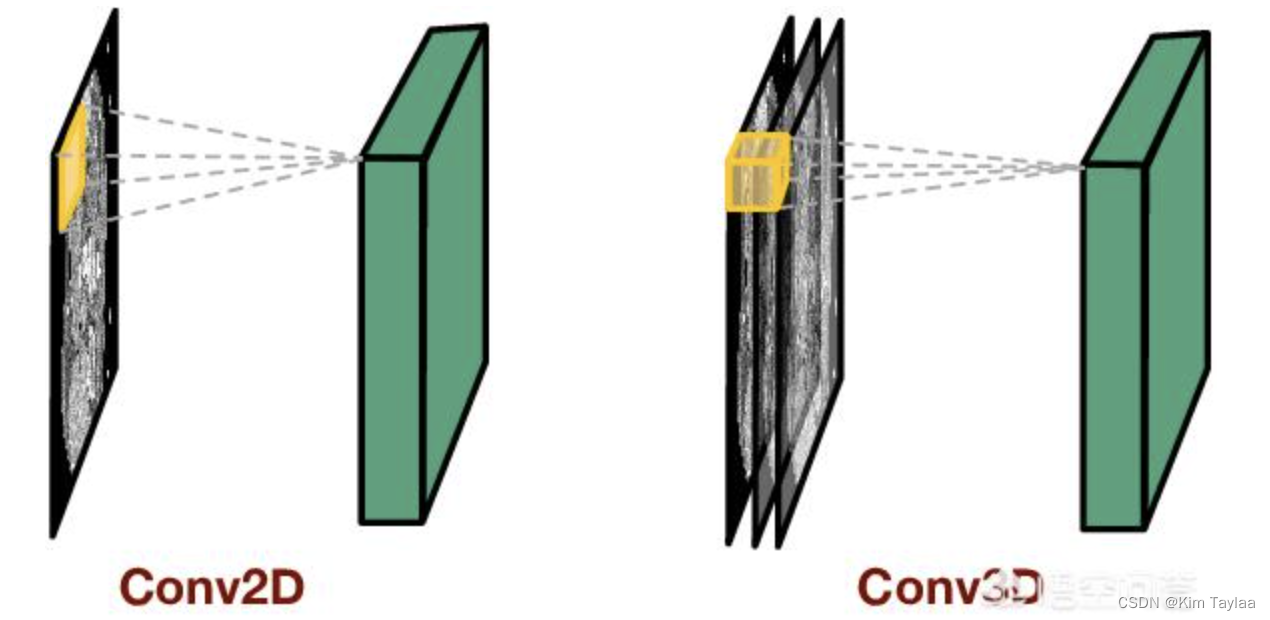
3D卷积和2D卷积的区别
2D卷积和3D卷积的主要区别为滤波器滑动的空间维度。2D卷积是提取的单张静态图像的空间特征,为了能够对视频进行特征,以便用来分类等任务,就提出了3D卷积,在卷积核中加入时间维度。
每次分类的结果都不一样,为什么?
网络中采用了Dropout,丢弃的参数不同,网络层的节点会随机失活。可以在训练模型时使用model.train()开启drop,在测试模型时,使用model.eval()关掉drop来使结果保持一致。
如何进一步提升高光谱图像的分类性能?
优化网络结构,添加注意力机制,增加网络深度等。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









