









1、MobileNets V1
MobileNets Series V1是通过减少参数的计算量以及操作数来加速网络的训练。
1.1 Original Convolution(原始的卷积)

Operations的计算过程:卷积核的参数总和 × \times ×feature map的大小。
D k ⋅ D k ⋅ M ⋅ N D_k \cdot D_k\cdot M\cdot N Dk⋅Dk⋅M⋅N是对feature map的一个点(包含通道)进行操作,所以最后再乘以 D F ⋅ D F D_F\cdot D_F DF⋅DF
1.2 MobileNets V1的步骤
MobileNets Series V1也就是Depthwise Convolution
缺点:
1、生成的通道数必须和原通道数一致;
2、各个通道的卷积计算没有联系;
3、训练效果欠缺;
一、第一步:

过程: 因为Kernel size是
D
K
⋅
D
K
⋅
1
⋅
M
D_K\cdot D_K\cdot1\cdot M
DK⋅DK⋅1⋅M,共有
M
M
M个
D
K
⋅
D
K
⋅
1
D_K\cdot D_K\cdot1
DK⋅DK⋅1,所以
D
K
⋅
D
K
D_K\cdot D_K
DK⋅DK是对feature map的每一个通道进行卷积,卷积后feature map的通道数仍是
M
M
M
下面是我手绘的过程:
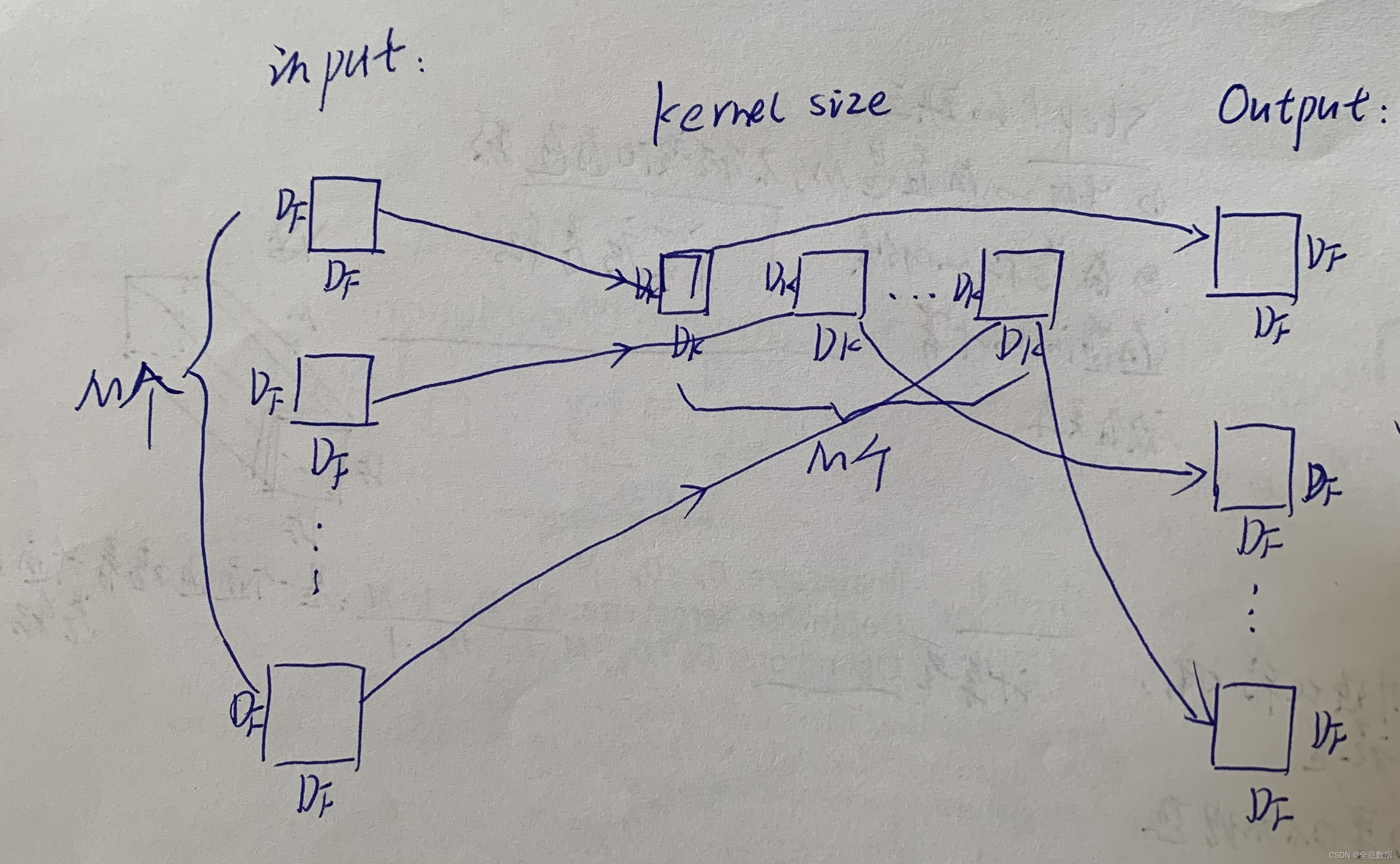
上图的计算量 Operations: D k ⋅ D k ⋅ 1 ⋅ M ⋅ D F ⋅ D F D_k\cdot D_k \cdot1\cdot M\cdot D_F\cdot D_F Dk⋅Dk⋅1⋅M⋅DF⋅DF
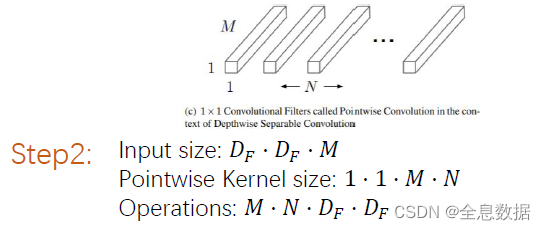
二、第二步:
第2步就是kernel size为1的常规卷积,在第一步得到feature map的基础上再进行1×1的常规卷积;
三、Depthwise Convolution的操作量与常规卷积的比较
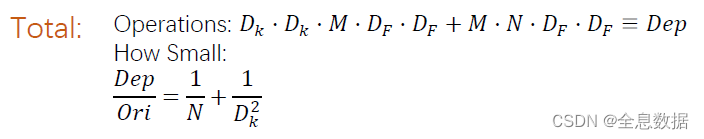
2、MobileNets V2
先看一下MobileNets V2的结构图:
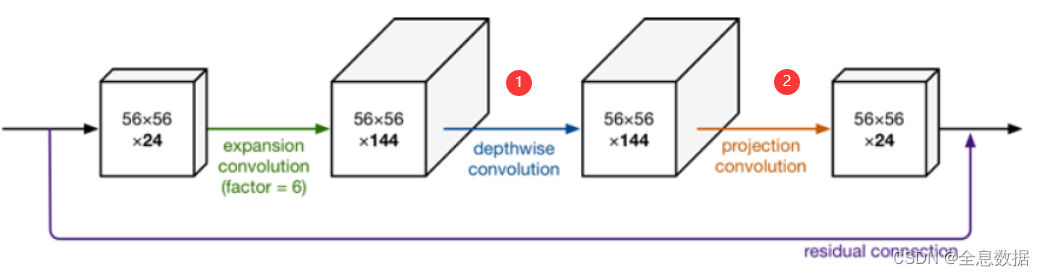
这个结构体比较详细:
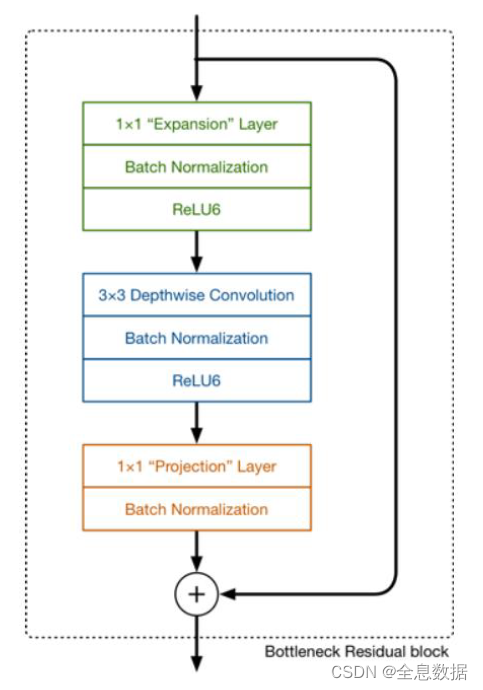
下面开始解释MobileNets V2的过程:
1、首先进行channel的增加,一般是×6,即图中的
24
×
6
=
144
24\times 6=144
24×6=144,
2、再进行Depthwise Convolution,
3、再再进行projection convolution,也就是常规的1×1卷积,
4、shortcut操作,注意shortcut后没有relu,
备注:
1、上图标红色序号分别是V1的第一和第二步骤;
2、紫线是residual,就是shortcut;
2.1 MobileNets V2的解疑
1、为什么使用Inverted Residuals?
Skip connection 这种 bottleneck 的结构被证明很有效, 所以想用;但是如果像以前那样先压缩 channel, channel 数本来自就少, 再压没了, 所以不如先增大再减少 。
2、为什么不用shortcut后不用relu?
ReLU让负半轴为 0 。 本来我参数就不多,学习能力就有限,这一下再让一些参数为 0 了, 就更学不着什么东西了 。 干脆在 eltwise 那里不要 ReLU 了。
2.2 MobileNets V2和V1的比较
1、V1使用Depthwise Convolution减少卷积的参数量和计算量,所以可以使网络进行加速;
2、 V2是借鉴了resnet的思想,又在V1的基础上进行设计,所以不能照搬resnet的结构,所以V2是先进行通道数的增加,一般增加6倍,然后再是V1的结构,最后把relu去掉了,因为参数本来就不多,所以就不使用relu了。
3、MobileNets V3
V3是在V2的基础上增加了SENet
下面先介绍SENet,然后再介绍SENet如何与V2进行结合。
3.1 SENet
SENet结构图:
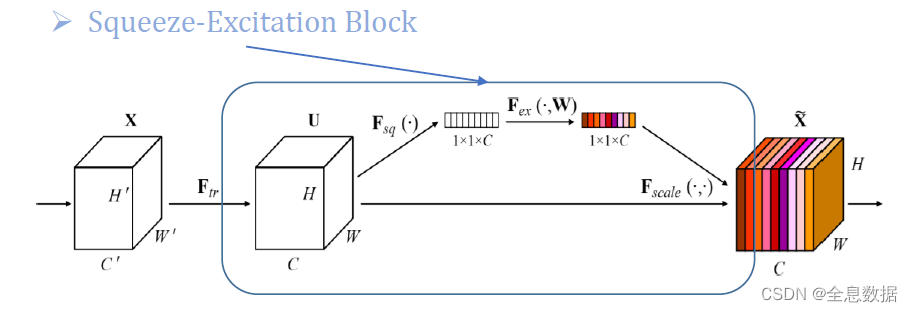
3.1.1 F s q ( ⋅ ) F_{sq}(\cdot) Fsq(⋅)介绍
其实也就是𝐺𝑙𝑜𝑏𝑎𝑙 𝐴𝑣𝑒.𝑃𝑜𝑜𝑙𝑖𝑛𝑔,对输入的feature map进行每一个通道的𝐺𝑙𝑜𝑏𝑎𝑙 𝐴𝑣𝑒.𝑃𝑜𝑜𝑙𝑖𝑛𝑔,所以输出就是
1
×
1
×
C
1\times1\times C
1×1×C了,
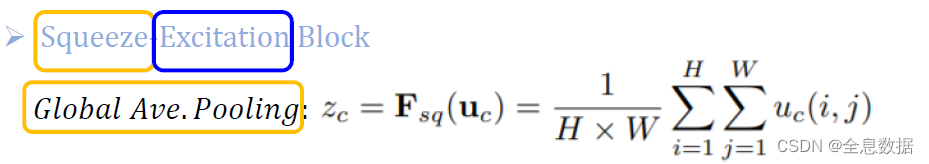
3.1.2 F e x ( ⋅ , W ) F_{ex}(\cdot,W) Fex(⋅,W)介绍
先上图:
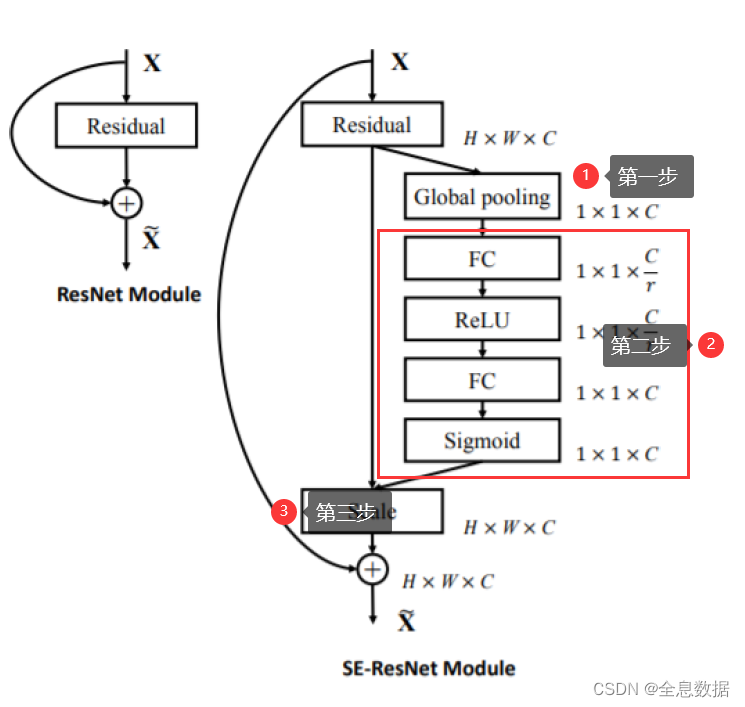
上图中的第一步已经介绍过了,就是
F
s
q
(
⋅
)
F_{sq}(\cdot)
Fsq(⋅),
F
e
x
(
⋅
,
W
)
F_{ex}(\cdot,W)
Fex(⋅,W)是上图中的第二步,即对第一步的输出分别进行FC、ReLU、FC、Sigmoid,注意最后一步是Sigmoid,所以输出的值在0-1之间,也就是每一个通道的权重;
有的版本把最后一步的Sigmoid替换成了h-swish,目的是为了加速,但没有起到加速的效果。
h-swish
[
x
]
=
x
R
e
l
u
6
(
x
+
3
)
6
[x]=x\frac{Relu6(x+3)}{6}
[x]=x6Relu6(x+3)
3.1.3 F s c a l e ( ⋅ , ⋅ ) F_{scale}(\cdot,\cdot) Fscale(⋅,⋅)介绍
第二步Sigmoid输出后,再与第一步输入的feature map进行相乘,即得到带有通道(channel)权重的feature map。
3.2 SENet与V2的结合
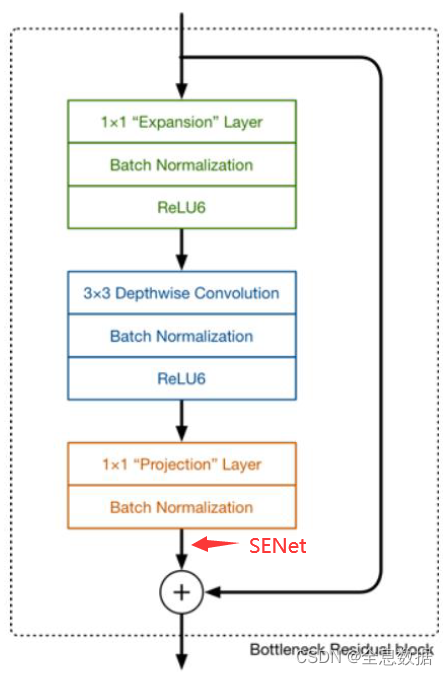
即是V2的基础上添加SENet就是V3,添加地方如上图。
SENet代码:
import torch
import torch.nn as nn
import math
class SeBlock(nn.Module):
def __init__(self, channel, ratio=16):
super(SeBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
print(y.shape)
print(y)
print('------')
y = self.fc(y).view(b, c, 1, 1)
print(y)
return x * y
inputs = torch.randn(1, 32, 5, 5)
model = SeBlock(32)
# print(model)
outputs = model(inputs)
print(outputs)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









