







目录
概要
重参数化(Reparameterization)方法在深度学习中,尤其是在涉及概率模型和变分推断的场景下,如变分自编码器(Variational Autoencoders, VAEs)与扩散模型(diffusion model),是非常重要的一项技术。它主要用于解决随机变量梯度估计的问题,使得我们可以有效地通过反向传播算法训练包含随机层的神经网络。以下是使用重参数化方法的主要原因及其优势:
1. 为什么需要重参数化?
1.1 正常的反向传播过程
我们首先考虑一个问题,普通的神经网络是如何通过可导来实现反向传播的?
假设我们有一个非常简单的神经网络:单层感知机,单层感知器(Perceptron),它只有一个输入层、一个输出层和一个权重w以及一个偏置b。我们的任务是二分类问题,使用均方误差(Mean Squared Error, MSE)作为损失函数。为了简化,我们将忽略激活函数,假设它是线性的。
那么它的网络结构就是这样:
输入层:1个特征权重:w
偏置:b
输出层:预测值y_pred
目标值:y_true
正向传递过程:
模型预测值:
![]()
计算损失,这里我们使用均方误差(MSE):
![]()
损失函数前添加一个1/2是为了求导的时候简化计算过程
反向传递过程:
我们的目标是计算损失函数L相对于权重w和偏置b的梯度,并使用这些梯度来更新w和b。这需要应用链式法则来逐步计算。
1.计算损失对预测值的梯度:
![]()
2.计算预测值对权重的梯度:
![]()
3.计算预测值对偏置的梯度:
![]()
最后我们使用链式法则计算损失对权重和偏置的梯度:
对于权重w:
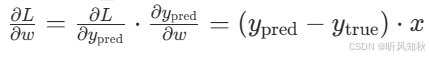
对于偏置b:
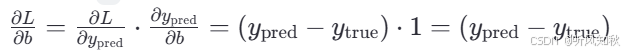
更新权重和偏置:
使用梯度下降法来更新参数,学习率我们这里使用(这通常是一个小的正数,如0.01)
更新权重w:
![]()
更新偏置b:
![]()
这样我们就完成了一个最简单的神经网络的反向传播过程,我们可以看到,反向传播的基础是模型可以用一个连续的数学函数来表达。这里的神经网络可以被概括为这个函数:
x是模型输入,w,b是模型的参数。
而随着神经网络的发展,这里的“连续”条件就出现了问题。
1.2 采样中的不可导情况
考虑一个简单的例子:假设我们有一个高斯分布,并且我们想要从这个分布中采样得到一个值
z。采样操作可以看作是从所有可能的z值中随机选择一个,这个选择是基于分布的概率密度函数(PDF)。由于采样结果是随机的,对于任意给定的和
,我们不能确定地预测采样出的具体
z值,因此也不能确定地计算z关于μ或σ的导数。换句话说,采样操作引入了一个非确定性的、离散的选择步骤,而这种选择是不可微分的。
而采样操作是VAE或扩散模型中最基本的方法,如下图红框中的解码过程,就是在一个学习到的潜在分布Z中通过采样来生成随机值,输入到解码器中得到最终模型输出,而这个采样过程是不可微分的。
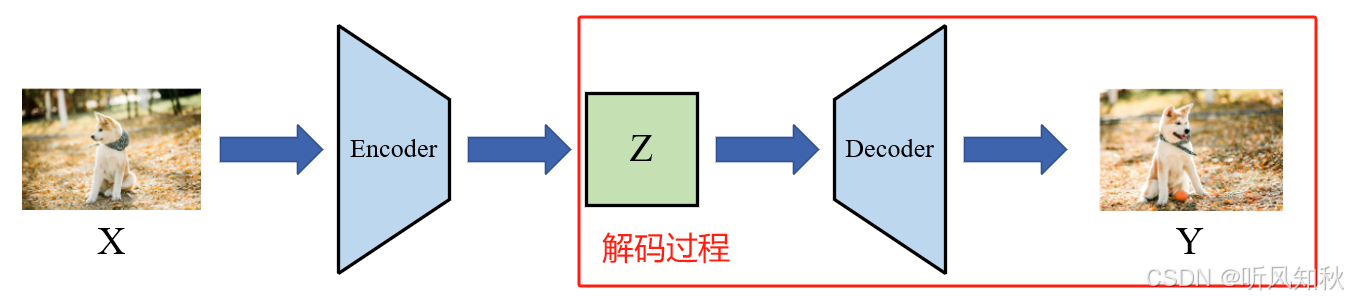
这就需要我们采取方法来解决不可微分的问题,这就是本章要讲的重参数化技术。
2.重参数化技术原理详解
上述采样过程中,直接采样Z是不可导的,而根据我们根据受1.1中权重w和b的启发,能否把采样Z的过程给拆开呢?把我们需要学习的参数单独提取出来,而把不可导的采样过程隔离出来,我们只对可导的和
进行反向传播不就可以了吗?
为了实现这个想法,我们采用重参数化技巧。其核心思想是将采样过程重新表述为一个由噪声变量ε和模型参数θ(例如μ和σ)决定的确定性函数(这就是刚刚说的“分离”思想)。具体来说,我们不再直接从分布N(μ, σ^2)中采样z,而是从一个简单且固定的分布(如标准正态分布N(0, 1))中采样一个噪声变量ε,然后通过一个确定性的变换函数g(ε, θ)来计算z:
![]()
对于高斯分布,这个变换可以写作:
![]()
这里,ε是从标准正态分布N(0, 1)中采样的,μ和σ是模型的参数。现在,z变成了μ和σ的确定性函数。
这意味着我们可以使用链式法则来计算损失函数L相对于μ和σ的梯度:
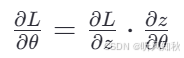
因为ε是独立于θ的,所以我们只需要关注z如何依赖于θ。这样,即使ε是随机的,整个过程依然是可导的,因为我们只对确定性的部分求导。
我们还是将模型表达为一个函数形式:
这里μ和σ是模型的参数,z变成了模型的输入
我们对比一下普通神经网络和重参数化下的网络图结构就能一目了然了:
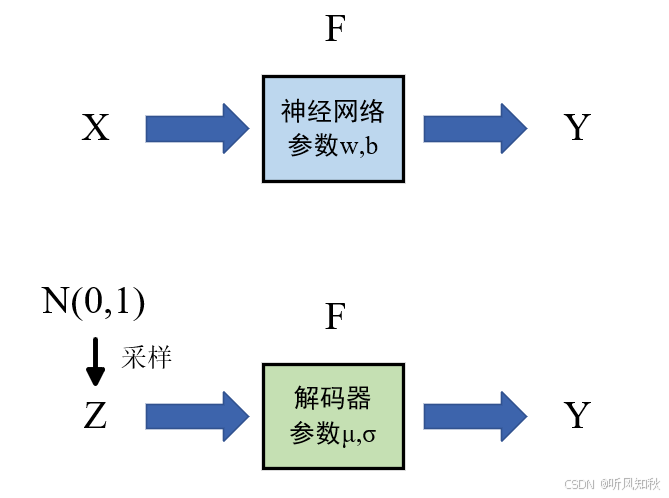
3.重参数化代码
虽然上述原理我们花了大篇幅来进行详解,但是重参数化技巧在代码中的应用却十分简单,我们用一个VAE模型的小例子来实现重参数化:
class VAE(nn.Module):
def __init__(self, input_dim, latent_dim):
super(VAE, self).__init__()
# 编码器部分
self.fc1 = nn.Linear(input_dim, 512)
self.fc21 = nn.Linear(512, latent_dim) # 均值
self.fc22 = nn.Linear(512, latent_dim) # 对数方差
# 解码器部分
self.fc3 = nn.Linear(latent_dim, 512)
self.fc4 = nn.Linear(512, input_dim)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std) # 从标准正态分布N(0, 1)中采样
return mu + eps * std # 重参数化公式
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3)) # 使用sigmoid激活函数输出到[0, 1]区间
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
重参数化在其中只需要两行代码就可以完成,也就是采样+公式计算。
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std) # 从标准正态分布N(0, 1)中采样
return mu + eps * std # 重参数化公式
4.结语
本文章是新系列的第一篇文章,这个系列会从头开始手把手教你深度学习相关的一切,主流技术、模型原理、网络搭建、代码实战,让你从小白变高手!
本文仅在个人学习过程中所写就,难免有错误与疏漏,请大家不吝赐教。
如果这篇文章对你有所帮助,请点赞收藏!

















 5975
5975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









