







文章目录
系列前言
本系列为论文文章精度,涵盖内容方向比较广泛,均围绕人工智能相关领域工作展开,包括但不限于:大语言模型、多模态、图像处理、海洋数值预报、数据处理等多个细分方向论文。
写这个系列的目的与论文复现系列相同,一是作为自己工作的记录,二是做为相关领域学术研究者的入门指引。
这个系列与论文复现系列是相辅相成的,一般能够做复现的论文都会继续更新在复现系列,帮助更多有需要的人获取想要的知识。受限于本人工作时间,每一篇文章精度和复现的更新时间可能不尽相同,请大家理解。
注意:黑体字为论文原内容,加粗部分为值得细读的重点,红色加粗字体为我对文章内容的进一步解释和补充。蓝色加粗字体为我对文章的理解和延申讨论。
论文题目:Local Ocean Wave Field Estimation Using A Deep Generative Model of Wave Buoys
论文地址:https://ieeexplore.ieee.org/abstract/document/10323089
摘要
从稀疏观测资料中估计海浪场是海洋学中长期存在的挑战,也是海上作业所需要的重要环境指标。局部区域内的波场需要频繁的实时更新,这对数据同化方法提出了新的挑战,因为数据同化方法计算复杂,并且依赖于外部大气强迫 。波场与局部稀疏观测之间的关系嵌入在再分析或后报数据中。我们提出了一种基于数据驱动的深度学习模型,该模型能够利用分布稀疏的浮动波浪浮标来估计局部波场。这一新颖的模型可以同时生成波高、周期和方向,以及它们各自的不确定性。在一个具有复杂波浪模式的峡湾地区进行为期一年的测试期间,所提出的模型展示了在估计波场方面的显著准确性和效率。
这里涉及到一些名词的进一步解释:
海洋波场:这是指海洋中波浪的高度、周期、方向等特征
稀疏观测:这意味着观测数据有限且分布不均,可能来自浮标、卫星等
数据同化:将观测数据与数值模型相结合的技术,用于提高预测精度。
外部大气强迫:指影响海洋波浪的外部因素,如风速、气压等。
再分析数据:通过结合历史观测数据和数值模型,重新构建过去的气象或海洋状态的数据集。
重点关注:本文提出的一个核心思想就是如何在一个稀疏的场中,根据数量稀少的几个观察测数据点,来对整个场的数值做出准确的预测,同时又能避免数据同化的计算代价。
1 引言
为了在局部地区获得精确的海浪信息,浮波浮标已成为主要的方法。虽然这些浮标在它们特定的位置提供了有价值的波浪统计数据,但它们彼此之间相当大的距离导致只能获得整个区域的点信息。获取整个地区当前海浪场的信息比只做点估计有很多好处。例如,船舶可以使用海浪场信息来规划航线和装载作业,或执行最佳停泊作业,养鱼场可以根据海浪场信息安排维护。
在天气预报中,估计天气状况被视为一个状态估计问题,其中观测与数值模式和数据同化技术相结合,以确定当前的天气状态并开始预报。同样,对于海浪,WaveWatch3 和SWAN等广泛使用的数值模型基于风和边界波条件生成海浪预报。数据同化技术通过纳入观测来改进这些预测。这些精确的预报是对海浪状况的估计。数值模型的精度依赖于网格分辨率,这是难以克服的计算瓶颈。
局部海洋波场的实时更新仍然面临挑战。局部区域通常是指大约25公里范围内的相对较小的区域,局部波场是指该区域内的波浪信息。这些区域可能包含复杂的地理特征,例如水深的快速变化和高山对风流的潜在阻挡。因此,为了准确模拟诸如波浪折射等复杂因素,需要高空间分辨率。此外,海洋波浪的演变不仅仅是一个初值问题,还涉及复杂的外部大气强迫和边界波条件,而这些条件通常来自全球或区域模拟,可能无法及时获得。因此,高空间分辨率和外部输入的要求使得使用数据同化方法进行局部波场估计变得困难。
本文提出了一种基于稀疏波浪浮标观测数据,利用深度神经网络构建海浪场的新方法。神经网络模型直接从数据中学习输入观察值和输出变量之间的关系。目的是学习从波浪浮标观测到局部波场的直接映射。在这种情况下,波浪浮标的观测结果作为产生波场的背景信息。经过训练后,该模型提供了一种极快的方式来生成波场,可用于图所示的一系列任务。此外,这个过程可能具有内在的不确定性。深度生成模型为不确定性建模提供了一种自然的方法。这种模型可以提供概率输出,与确定性输出相比,这对于决策目的更有价值。
尽管波浪浮标的可用性有限,但该模型有效地重建了具有挑战性的峡湾环境中的海浪场。波浪由三个重要参数表示,提供了详细的波浪条件,而不是文献中的单一参数。重要的是,它成功地捕捉到了波浪高度和周期之间的复杂关系。此外,该模型证明了其表征和量化与其输出相关的不确定性的能力。我们的发现突出了深层生成模型在重建复杂海洋现象场中的巨大潜力。
总结本文主要有以下三项贡献:
1.根据稀疏浮标的观测数据,建立了一个深度生成模型来估计海浪场。
2.通过重新校准程序,模型很好的表示了估计的不确定性。
3.该模型提供了丰富的波浪信息,并捕获了波高和周期的联合分布。
2 相关工作
2.1 数据同化
数据同化在地球科学中通常被称为状态估计理论 ,它与估计理论和最优控制密切相关。数据同化通过将观测数据应用于数值演化模型的预测结果,对其进行修正,从而获得系统状态的最佳估计。常用的数据同化方法可以分为变分方法和顺序方法。变分方法 用于估计在规定观测窗口内最符合所有观测值的状态。它被表述为一个优化问题,旨在最小化一个标量误差。因此,任意时间点的状态估计会受到规定窗口内所有观测值的影响。该方法还被用于同化海洋学数据,如温度、盐度和海流 。对于海洋波浪,尽管已有尝试,但开发伴随模型非常复杂,因为频谱空间中的运算符非常复杂 。此外,变分技术需要迭代过程来优化损失函数,这可能会带来巨大的计算成本。因此,海洋波浪的同化通常使用顺序方法 。顺序方法在每个时间步交替进行预测步骤和更新观测。
这里简单介绍一下变分方法和顺序方法各自优缺点。
变分方法(Variational Methods):
变分方法是一种通过优化问题来估计系统状态的方法。它假设我们有一个数值模型(通常是基于物理定律的数学模型),并且我们有一系列观测数据。变分方法的目标是找到一个最优的状态估计,使得模型预测与观测数据之间的差异最小化。
优点:
全局优化:变分方法可以在整个观测窗口内同时考虑所有观测数据,因此能够提供更全局的优化结果。
高精度:由于它是一个优化问题,变分方法可以利用大量的观测数据来提高状态估计的精度。
适用于大规模系统:变分方法特别适合处理大气和海洋等大规模系统的同化问题。
缺点:
计算复杂:变分方法通常需要多次迭代才能收敛,尤其是在高维系统中,计算成本非常高。
依赖于伴随模型:为了计算代价函数的梯度,变分方法通常需要开发伴随模型(adjoint model),这在复杂的物理系统中非常困难,尤其是对于海洋波浪模型,因为频谱空间中的运算符非常复杂。
假设限制:变分方法通常假设背景误差和观测误差服从高斯分布,并且模型是完美的。这些假设在实际应用中可能不成立,导致结果偏差。
顺序方法(Sequential Methods):
顺序方法是一种递归更新的方法,它在每个时间步上交替进行预测和观测更新。与变分方法不同,顺序方法不需要在整个观测窗口内同时考虑所有观测数据,而是逐个时间步地处理观测信息。最常见的顺序方法是卡尔曼滤波及其扩展版本。
优点:
实时性:顺序方法能够在每个时间步上实时更新系统状态,特别适合需要频繁更新的应用场景,如海洋波浪的实时预报。
计算效率高:相比于变分方法,顺序方法的计算成本较低,因为它不需要在整个观测窗口内进行全局优化。
无需伴随模型:顺序方法不需要开发伴随模型,因此更容易实现,尤其是在复杂的物理系统中。
缺点:
局部优化:顺序方法只考虑当前时间步的观测数据,因此它提供的优化结果是局部的,可能会忽略历史观测的影响。
线性假设:经典的卡尔曼滤波器假设模型是线性的,并且观测噪声和模型误差服从高斯分布。对于非线性系统,这种假设可能不成立,导致结果偏差。为此,发展了扩展卡尔曼滤波(EKF)和无迹卡尔曼滤波(UKF)等改进版本。
初始条件敏感:顺序方法对初始条件较为敏感,如果初始状态估计不准确,后续的预测和更新可能会受到影响。
这里其实大致了解一下变分方法和顺序方法都是怎么做的就行,他们都是以往在深度学习出现之前对海浪波高进行预测的方法,都存在诸如计算量庞大、不适用于非线性复杂系统、对稀疏数据的预测效果很差等缺点,而这正是深度学习能够发挥优势的地方。
2.2 地球科学中的深度神经网络应用
近年来,地球科学经历了一场重大革命,从一个数据贫乏的领域到一个数据丰富的领域,现代深度神经网络(DNN)得到了广泛的研究。深度神经网络能够从大型数据集中自动学习复杂的模式和关系,这可以提高地球科学模型和预测的准确性。Shoji et al.使用卷积神经网络根据形状对火山灰颗粒进行分类。利用网络返回的类别概率来确定具有复杂形状的灰颗粒的混合比例。Lv等人开发了一种基于分布式声传感技术的卷积神经网络地震检测方法。它可以在有限的阳性样本数量下达到很高的准确性。Yao等人扩展了用于多模式学习的视觉转换器,并在两个遥感数据集上显示了性能改进。深度神经网络模型也被广泛应用于高光谱图像分类中,不同层次的特征可以很容易地被神经网络模型融合。Fablet et al,通过学习DNN模式重建了卫星观测的海表温度和海表高度等海浪场。实验结果表明,该模型比最优插值框架更有效。同样,我们的目标也是重建海浪场,但我们依赖于波浮标的稀疏观测。
这是论文里几乎必出现的一个环节,写一写深度神经网络的应用,尤其是与本论文有关的领域应用,然后总结一下其中的优点与缺点,再慢慢扯回到自己的模型上,说一下本模型的优点。
2.3 深度生成模型
深度生成模型是一种类似于数据分布的模型,可用于生成概率输出。这些模型学习潜在表示来表示数据分布。通过从潜在表示中采样,可以生成概率输出。有几种类型的深度生成模型,包括变分自编码器(VAEs),生成对抗网络(GANs)和自回归模型。这些模式已用于产生概率降水预报。与确定性预测相比,概率预测有望提供更大的经济和决策价值。这同样适用于波场估计。此外,从非常稀疏的浮标观测中重建波场是一个可能涉及很大不确定性的过程,进行概率估计是必要的。
概率预测是模型发展的一个大方向,从一开始的二分类到后来的多分类,模型预测一个概率比预测一个确定值在可解释性与可靠性方面是更具有优越性的。
自从chatGPT横空出世之后,深度生成模型就成了各行各业的一个热点话题,也成了研究里的香饽饽,毕竟相较于让人工智能去帮我们完成既定的事情,我们更想看看模型能给我们“生成”什么。当然,这里做海浪预测,那生成模型自然是最佳的选择。
3 基于波浪浮标数据的深度生成模型
3.1 问题描述
所提出的模型是一个条件生成模型,可以预测给定过去或上下文的波浪浮标观测的波场。模型包含潜在随机向量z,可以用:
(这里偷个懒直接用论文里的公式图片,手打公式很麻烦。)
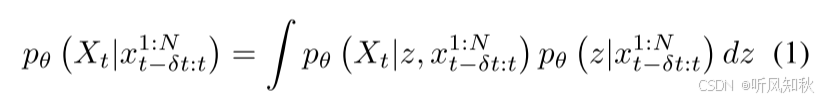
x t−δt:t1:N表示从 t−δt:t到t时刻的观测值,为了方便表示,将其记为 c,θ为神经网络参数,Z是潜在变量。Xt为t时刻的区域波场。参数θ的学习是在具有对抗学习的条件变分自编码器的框架内进行的。三个连续的波浪浮标观测(过去20分钟,波浪浮标间隔10分钟)被用作解码器的背景,允许对多个波场进行采样。
开头先说一下这个模型要做的事情是什么,一句话总结,就是在一个波浪场中用有限的几个点的浮标数据来预测整个场的波浪数据。
3.2 海浪场表示
海洋波浪通过一个二维波谱(2D wave spectrum)来表示,该波谱在方向和频率上进行了离散化 。通常从二维波谱中计算出集成波参数,以表示波浪的统计特性。在这里,使用三个参数来表示单个点的波浪条件:有效波高hs、平均波周期tm和平均波方向dirm。 下展示了二维波谱与集成波参数之间的关系。
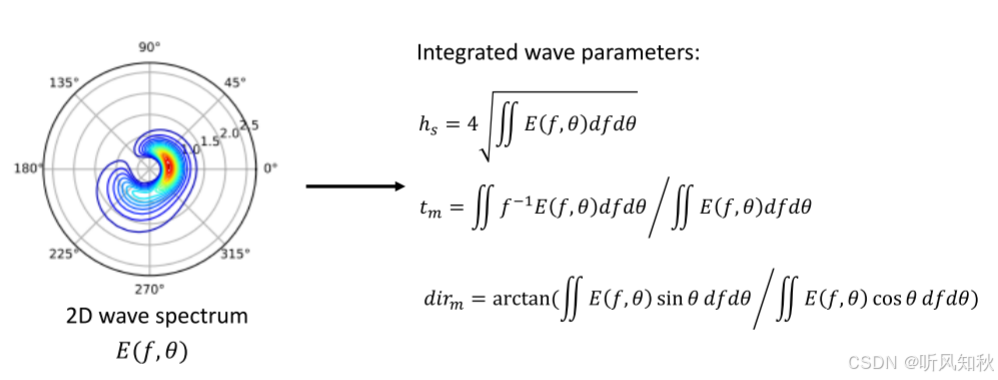
这里重点说一下文章这里对波方向的处理方式,很巧妙,大家可以在自己的工作中作为参考:
平均波方向dirm是一个角度值,所以取值范围在0°到360°范围内,这就给数据处理带来了挑战。如果直接使用角度值作为输入,那模型会对0和360对应的是同一个数值这个问题感到困惑(模型很有可能无法正确理解0和360角度是相等的这个含义。)
所以这里给出解决办法,很简单,就是将平均波方向编码成两个分量:cos(dirm)与sin(dirm),这样做有三个好处:
- 周期性依然得到了保持,0°和360°的余弦和正弦值是相同的,编码后的数据依然能正确表示方向的周期性,而模型也不会在这里产生歧义了(因为数值表示变一致了)
- 易于重建,这点也很好理解,使用反正切函数就可以把原来的数据反求出来。
- 数值范围变为[-1, 1],这也使得数据变得更适合深度学习模型来学习推理(数据的波动范围降低了,模型变得更稳定)。
这部分算是数据处理的一个小环节,作者很巧妙的把波的方向性数据转换为更适合神经网络学习的数据表示形式。
3.3 具有对抗学习的条件变分自编码器
条件变分自编码器是变分自编码器的扩展,它提供了对VAE数据生成过程的控制。这里直接给出公式:
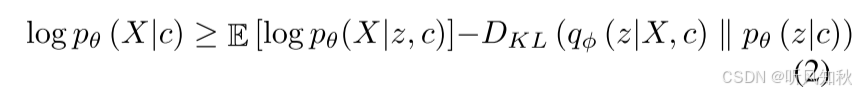
Dkl是KL散度,这里通常以负的ELBO作为优化目标,而非直接最大化ELBO,训练目标是最小化。负ELBO可以看作是重构损失和KL散度之和。
使用均方误差MSE来对负对数似然进行重建损失。公式如下:
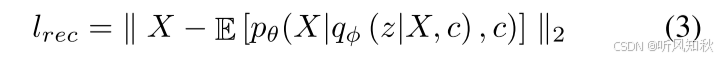
尽管均方误差(MSE)通常被用作变分自编码器(VAE)的重构损失,但在最大似然估计中,它可能会在训练过程中过度正则化 。然而,我们期望生成多样化的样本,并通过向KL散度损失添加一个超参数来平衡正则化和重构。因此,在本文中仍然使用MSE作为重构损失。
尽管MSE在很多任务中常作为重构损失,但是其在最大似然估计框架下,可能会使模型过度关注于减少重构误差,而忽略了潜在空间的多样性,为了在保持重构质量的同时增加样本的多样性,作者在这项工作中引入了一个超参数来调整 KL 散度损失的权重,从而平衡正则化和重构之间的关系。
后面是变分自编码器的老一套阐述内容,先验分布从标准高斯分布中建模、编码器输出分布的平均值和标准差等等。下面给出KL损失公式:
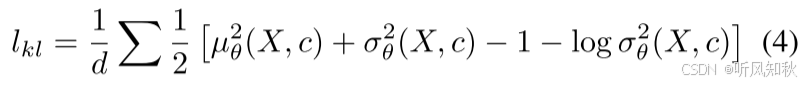
这里简单说一下,重建损失作用于解码器,目标是让模型尽可能的忠于重构输入数据,也就是尽可能生成与原始数据高度相似的生成数据。而KL损失作用于编码器,目的是确保生成的潜在空间是平滑且多样的,也就是保证模型能够生成更多样化的数据形式。这两者是互相掣肘的,需要根据需要来调整损失占比,使模型达到多样性和真实性的平衡点。
关于变分自编码器,这里放个学习链接,大家直接点进去详细学习就好了,本文重点在于论文解析。
3.4 对抗性学习
这不是论文里单独的一个小节,但是我把它单独拿出来说一下,算是比较有意思的一个组成部分。
为了在学习框架中采用对抗性训练,增加了一个鉴别器来区分解码器产生的输出和真实值波场。训练生成器和鉴别器时的对抗损失为:
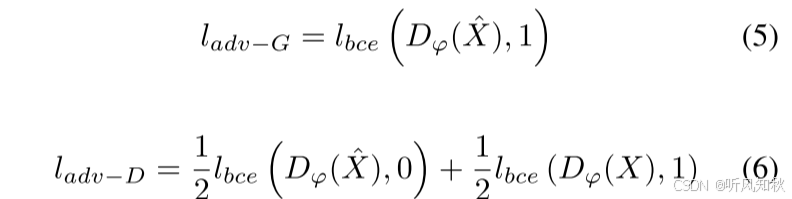
这个损失函数相信看过对抗学习(GAN系列)的同学都不会陌生,(5) 是作用于生成器的生成器的目标是“欺骗”判别器,使其无法区分生成的波场和真实波场。因此,生成器会不断调整其参数,使得 D(X) 尽量接近1,φ是模型参数。而(6)是作用于判别器的,目的是尽可能地区分开生成器生成的数据和真实数据。
3.5 损失函数
生成器(包括上下文编码器、编码器和解码器)和判别器的训练分别涉及以下损失函数的最小化:
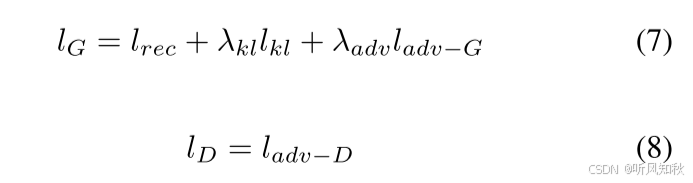
λkl和λadv分别是平衡KL损失和对抗损失的两个超参数。训练过程中,轮流在Lg上进行一次梯度下降,然后在Ld上进行一次梯度下降。
模型训练完成后,在推理阶段只使用上下文编码器和解码器。将波浪浮标的观测数据输入上下文编码器,生成上下文c。然后从标准多元高斯分布N(0,I).解码器基于上下文c和潜在向量z的组合输出波场,现在我们可以通过对潜在向量z采样来对不同的波场进行采样。
解释一下,(7)就是一整个生成器,把整个模型包进来了,(8)就是单独的一个判别器,只负责区分开生成数据和真实数据就行。
3.6 模型框架
该部分介绍了模型的网络架构。模型遵循变分自编码器(VAE)的结构,因此包含一个编码器(Encoder)和一个解码器(Decoder),用于将波场数据编码到潜在空间中并进行重构。为了处理时间序列的波浪浮标测量数据,设计了一个上下文编码器(Contextual Encoder),用于生成条件向量 c,以指导编码和解码过程。此外,引入了一个判别器(Discriminator),通过对抗训练来惩罚高层次的统计特征,避免生成模糊的输出。
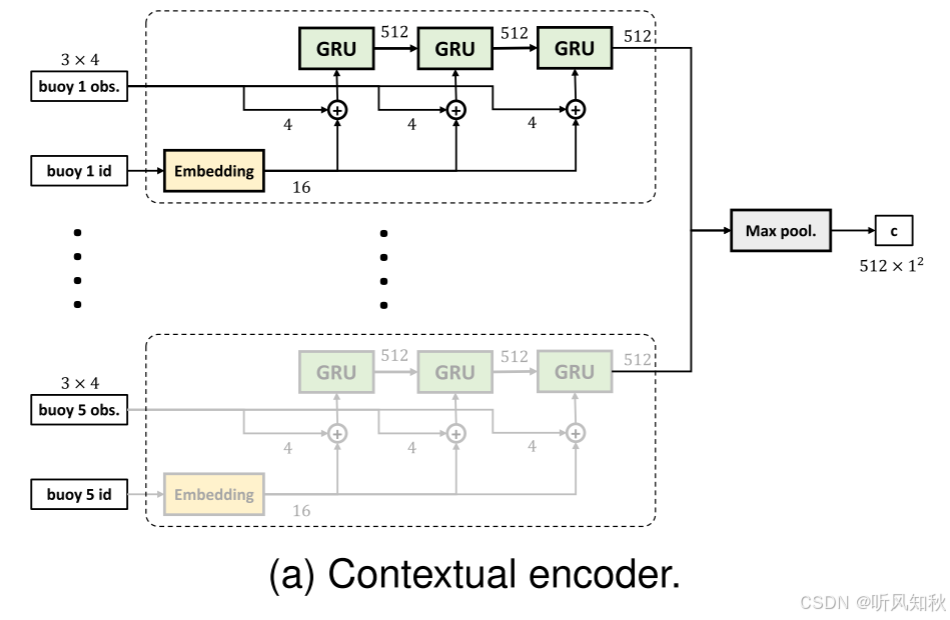
a) 上下文编码器(Contextual Encoder)
上下文编码器的主要目标是将来自波浪浮标的观测数据编码为一个紧凑的向量 c。上下文编码器的设计目的是能够处理任意数量的波浪浮标。如图4a所示,我们使用共享的门控循环单元(GRU, Gated Recurrent Unit)对每个波浪浮标的观测数据进行编码,生成一个浮标嵌入(buoy embedding)。为了确保每个浮标的独特性,我们将每个波浪浮标的唯一ID编码为位置嵌入(positional embedding),并与相应时间步的观测数据拼接在一起。所有浮标嵌入通过最大池化层(max pooling layer)集体处理,生成最终的上下文向量 c。
这种方法的一个重要优势是,它使用了共享的GRU来处理所有波浪浮标,并通过对称的最大池化层聚合信息,从而使得上下文编码器能够有效地处理任意数量的波浪浮标。
b) 编码器(Encoder)
编码器采用了一种深度卷积神经网络架构,结合了卷积-批量归一化-ReLU (Convolution-BatchNorm-ReLU) 模块,并包含了一个最大池化层(max pooling layer)。使用 4×4 卷积核来进行波场的下采样。如图4b所示,编码器接收四维波场和上下文作为输入,并输出潜在向量的均值和方差。
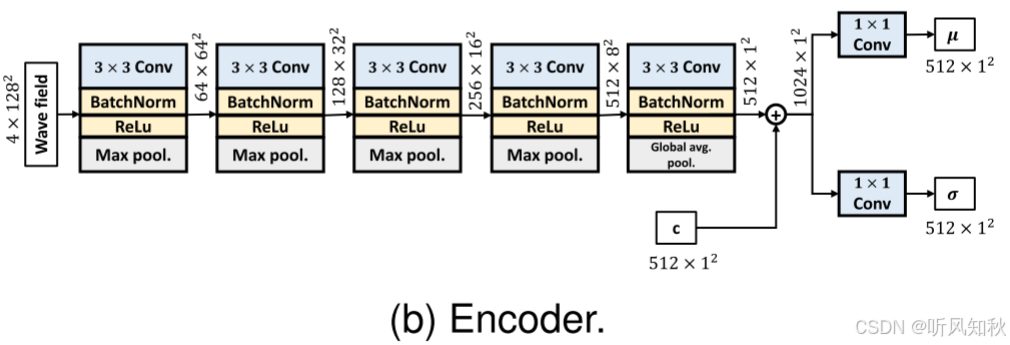
编码器接收四维波场数据和上下文信息作为输入。具体来说,输入的形状为 (N,C,H,W)。其中N为批次大小,C是通道数,表示上文提到的不同类型波长数据,H和W分别是波长的高度和宽度
c) 解码器(Decoder)
解码器利用上下文向量 c 和潜在向量 z 来生成波场。它的架构与深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network, DCGAN)。具体来说,解码器使用 4×4 的转置卷积算子(transposed convolution operator)来进行上采样操作。关于解码器架构的详细视图,请参见图c。
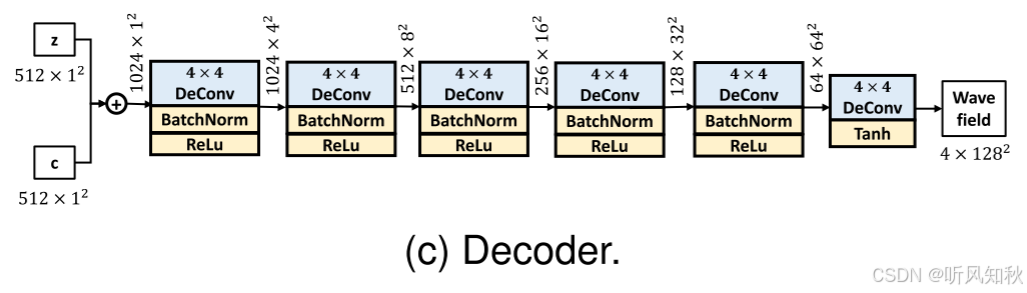
这里的输入z就是包含着编码器输出的平均值和方差了,再把浮标测得波浪场点数据放进去,让编码器上采样重构整个波浪场的数据,标准的变分VAE架构。
d) 判别器(Discriminator)
判别器同样采用了深度卷积神经网络架构,但使用了 LeakyReLU 作为激活函数,而不是 ReLU。它的输入是波场数据,任务是区分真实的波场和解码器生成的波场。关于判别器架构的详细视图,请参见图d。

判别器很简单,把生成的波浪场数据拿过来判断下是真的还是假的。倒逼前面生成器生成更真实的波浪场数据,GAN的思想。
4 实验
4.1 数据集
提供的数据集由挪威气象研究所(Norwegian Meteorological Institute)在挪威苏拉菲尤尔德(Sulafjorden)地区收集。苏拉菲尤尔德以其动态的水深而闻名,导致该地区的波浪模式非常复杂。数据集涵盖了从2017年1月1日至2020年2月29日共三年的综合数据。其中,前两年的数据用于训练集,而最后一年的数据用作测试集。
该区域使用了五个波浪浮标进行观测。每个浮标的位置如图所示,并列出了部署日期。所选区域是一个典型的峡湾地区,特征为众多岛屿、高耸的山脉和深水区。因此,风浪和涌浪在此区域同时存在,形成了多样且不断变化的波浪模式,表现出显著的空间和时间变化。需要注意的是,浮标 C 和 F 的部署时间晚于数据集的起始日期,因此这些浮标的早期数据中包含 NaN 值。上下文编码器设计为能够处理不同数量的波浪浮标,以应对这种情况。
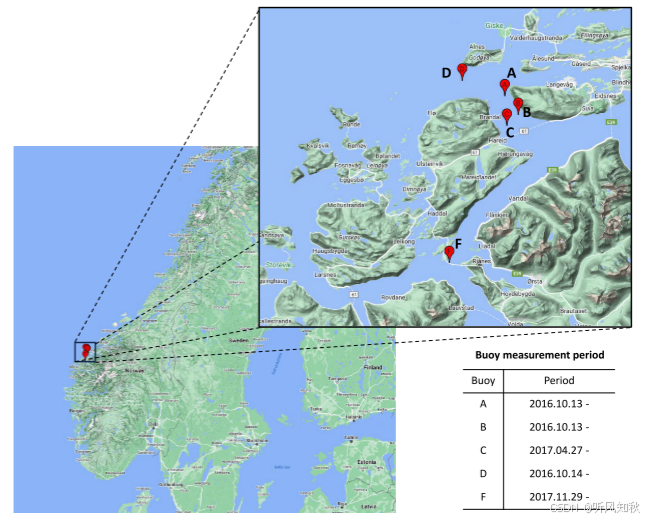
波浪浮标的原始测量数据不可避免地会受到各种退化、噪声或变异性的影响。这种影响已在文献中针对许多不同的数据源进行了讨论 。为了确保数据质量,收集到的数据已经过质量控制。此外,手动过滤掉了异常观测值,例如极值等错误数据。
波场数据来自SWAN波浪模型的后报模拟,网格分辨率为250米,时间分辨率为1小时。尽管这是后报数据而非再分析数据,但它与实际观测数据具有良好的相关性。原始后报数据覆盖的地理区域为纬度62.0°至62.6°和经度5.3°至6.8°。我们从中提取了感兴趣的一个 128×128 大小的区域。
为了表示波浪状况,选择了三个参数:有效波高 、平均波周期 和平均波方向 。因此,仅从波浪浮标和后报数据中提取了这三个参数。
作者这里对数据集的选取、处理还是比较到位的,可以看到区域大小是128*128,跟模型输入的维度刚好对应上。这个数据集在后面的论文复现中我会单独整理出来提供给大家。
4.2 评价指标
每个网格单元度量是在测试数据集中所有示例中的所有目标网格单元上计算的。这些目标网格单元以i为索引。下面,模型对目标网格单元i的预测值记为Pi,对应的真实值记为Oi。N表示单次预测中目标网格单元的个数。
均方根误差(RMSE):
这个指标给出了确定性预测准确性的连续度量。
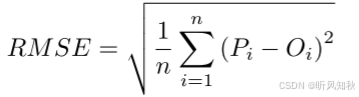
连续排序概率评分(CRPS):
CRPS是衡量预测与观测结果匹配程度的一种标准,在预报组中广泛用于评估整体天气预报。每个网格单元的CRPS定义为:
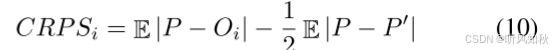
P 和 P 撇是从预测分布 Pi 中独立抽取的样本。Oi是第i个网格单元的实际观测值。第一项E|P-Oi|表示预测分布与实际观测值之间的平均绝对误差。第二项1/2E|P-P撇|表示预测分布的内部不确定性,即两个独立样本之间的平均绝对差异
为了估计每个网格单元的 CRPS,我们使用 N=10 个集合成员作为样本。这些样本用于计算第一项和第二项的期望值。
这里两项E分别算的是预测值和真实值的误差、以及单元区域内数值分布的平均性,避免出现区域内数值分布的过大或过小数值,也就是一个单元内数据分布应当是平滑的。
所有网格单元的 CRPS 值被平均,以得到整个区域的总体 CRPS:
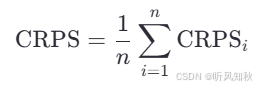
其中n是网格单元的总数。
对于不同的波浪参数,CRPS 的计算方式略有不同:有效波高和平均波周期直接使用上述公式进行计算。这两个参数是数值型的,因此可以直接计算绝对误差。平均波方向是周期性的,0° 和 360° 实际上是相同的。因此,在计算 CRPS 时,需要对波方向的误差进行特殊处理。具体来说,将|Pi-Oi|替换成:

这样可以确保波方向的误差在 [0°, 180°] 范围内,避免了由于周期性导致的不合理的误差值。
这里需要注意,度数还是存在0和360数值不同但是含义指向却相同的问题,所以加一步转换,范围变成0-180就可以消除这个歧义。
4.3 实验结果1:模型在测试期间的预测准确性
这里原文每一段写的比较乱,我梳理了一下给大家详细说明每个实验和相关的图像。
下图展示了 DGWBNet 模型预测的波浪参数与后报波浪参数之间的对比。结果显示,预测值与后报值在大多数情况下吻合良好,尤其是在低波高和低波周期区域。然而,当波高和波周期较大时,模型的预测趋于保守,即预测值可能低估了实际波浪的强度或周期。
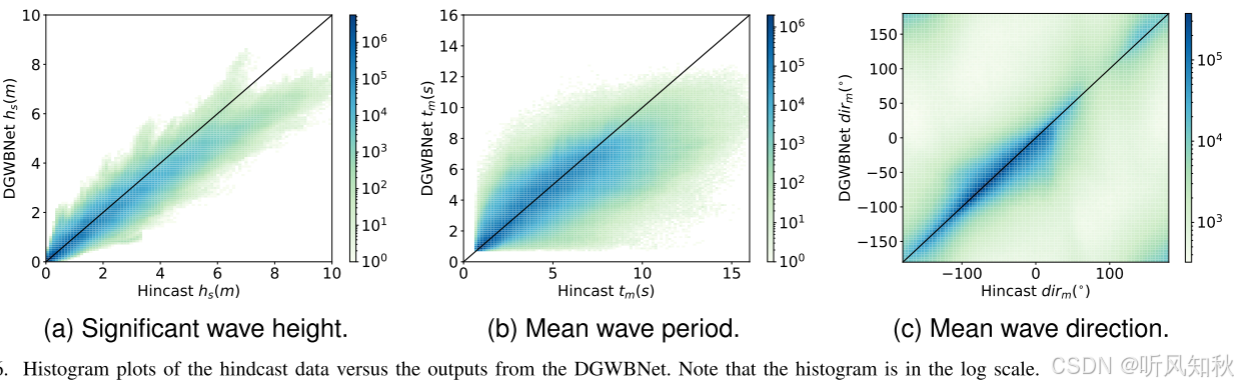
这个图很好看懂,颜色越深、且越接近图中黑线的部分,模型预测的就越接近真实值,可以看到,随着波高、周期数值越大,也就是风高浪急的时候,模型预测效果就要差一点,也可以理解,那个时候数值变化太剧烈,模型拟合效果肯定会下降。
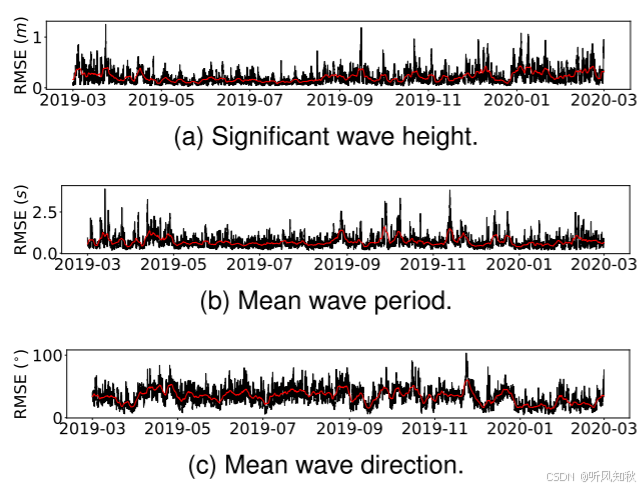
下面三张图分别展示了显著波高、波周期和平均波方向的 RMSE 随时间的变化。分析发现:
显著波高: 冬季的 RMSE 略高于夏季,这可能是因为冬季海况更为恶劣,波浪的变化更为剧烈,导致预测难度增加。
平均波方向: 相反,夏季的 RMSE 略有升高,这可能是由于在平静的海况下,波浪方向的变化较小,观测波浪方向的准确性较低,导致预测误差增大。
下图展示了 RMSE 在不同区域的空间分布。分析结果如下:
显著波高: 在开阔海域,RMSE 明显高于其他区域。这可能是由于开阔海域的波浪变化较大,且波浪浮标与该区域的距离较远,导致预测的不确定性增加。
平均波周期: 在近岸区域,RMSE 显著较高。这可能是由于近岸区域的复杂动力学特性,如浅水效应、地形影响等,增加了预测的难度。
平均波方向: 在峡湾区域,RMSE 较高,主要是因为该区域的风场对波浪方向有显著影响,导致波浪方向的变化更加复杂和难以预测。
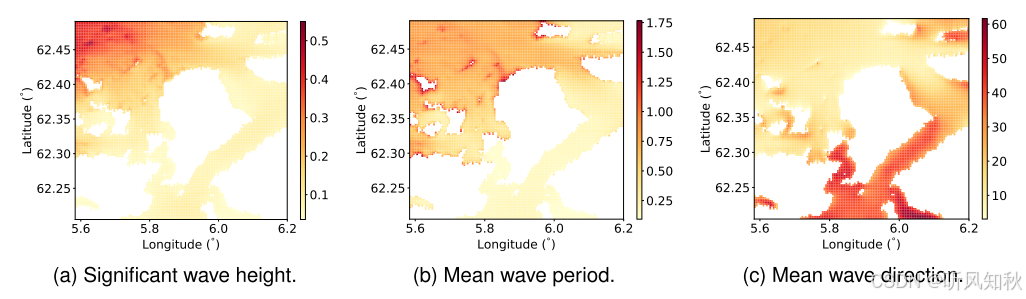
这个图可以结合我放在前面的峡湾浮标分布地形图来看,空白的地方就是陆地,其余的地方颜色越深说明RMSE数值越大,也就是模型预测的效果越差,结合作者给出的解释可以对照理解一下。
总的来说,这三部分实验展现出,模型受季节性影响、区域差异的影响比较大,这也是以后研究改进的一个重点方向,即如何提升模型对小区域差异、季节变化影响的鲁棒性。
4.4 实验结果2:波高与周期的联合分布
为了评估模型捕捉波型的能力,在测试期间,为该区域内精心选择的六个点绘制了有效波高与平均波向之间关系的散点图,如下图所示。具体而言,选取了外海地区的3个点和峡湾地区的3个点进行分析。如图b所示,该模型成功地重建了有效波高与平均波周期之间的相关性。然而,值得注意的是,模型的分布似乎比观测数据的分布稍微紧一些,这表明模型可能没有完全捕捉到极端情况。此外,位于开阔海域的点和位于峡湾区域的点之间可以观察到明显的区别。当比较第1点和第2点与第5点和第6点时,这种区别变得特别明显。这种差异可归因于涨潮和风浪的存在,开阔海域主要受到来自边界的波浪的影响,而峡湾地区主要受到当地风型的影响。
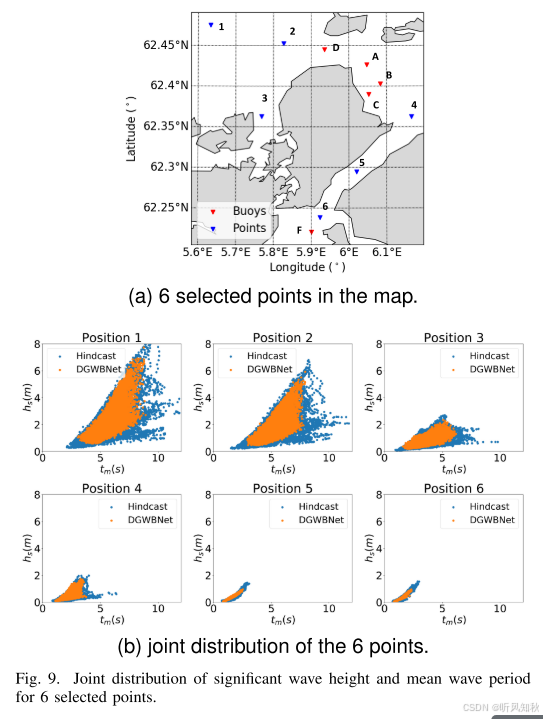
这里主要涉及两点,一是不同海域的波高与波向的分布是差别很大的,这也体现出专门针对某一特定海域的海浪预测的重要性,因为大模型对全局预测可能就会降低这些小区域的预测精度。第二,模型的预测与实际观察值依然存在一定偏差,这个还是很正常的,作者也给出了自己的见解。
4.5 实验结果3:不确定度校准
使用深度生成模型的一个关键优点是它能够捕获和表示波浪估计中固有的不确定性。为了评估我们提出的模型的预测不确定性,我们采用了一个程序,涉及为给定情景生成10个预测。然后使用这些估计值来近似每个网格点的平均值和标准差。维护了一个保留验证集,并对验证集中的所有场景重复此过程。随后,我们构建了一个α-预测,旨在包含α%的观测值。通过迭代不同的α值,我们评估了落在预测区间内的验证数据的比例。下图所示的校准图在x轴上表示预期在区间内的验证数据的预测比例,在y轴上表示在区间内的验证数据的观测比例。然而,值得注意的是,我们提出的模型在其预测中表现出轻微的过度自信倾向。为了提高模型准确表示不确定性的能力,受其他作者的启发,我们进行了一次重新校准过程。这涉及到在推理阶段缩放潜在向量的方差,特别是通过从N(0,2.5 I)而不是标准的多变量高斯分布N(0,i)中采样。这种修改导致了不确定性的更好表示,如图b所示,产生了更可靠的结果。
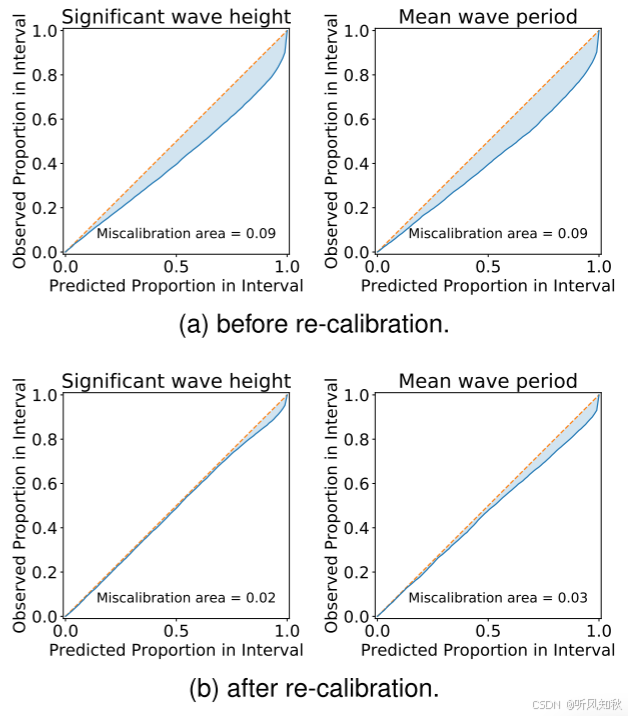
这个实验看着洋洋洒洒说了这么多这么复杂,其实就一句话:“我们的模型原来不太好,预测有点过于自信了,所以我们调整了模型潜在变量分布的方差,调整之后模型预测变得更好了!(炼丹ing)”。
4.6 实验结果4:与其他基准方法比较
为了评估模型的性能,我们计算每个网格单元的指标用于点预测,然后汇总它们以获得全网格指标。
基线模型:本文使用了四条基线:
1.MyWaveWAM 800m是挪威气象研究所的挪威海岸海浪预报系统。实用的数值波模型是WAM,在800米网格上运行。该模式在ECMWF和AROME大气强迫下运行。请注意,这个模型有一个800米的网格,因此我们执行线性插值将结果缩小到我们想要的200米网格。
2.k近邻(kNN):第二个基线是最近邻方法。我们将波浪场和相应的波浪浮标的观测数据保存在数据库中。然后在推理阶段,计算输入浮标观测值与数据库观测值之间的距离。上面的k个对应的波场是估计的波场。我们使用k=10进行集合估计,k=1进行确定性估计。
3.GRU- conv:该模型采用编码器-解码器结构实现,GRU作为编码器对时间序列浮标观测数据进行压缩,采用转置卷积运算的卷积神经网络作为解码器输出波场。为了产生概率估计,假设网络在每个网格上的输出遵循高斯混合模型。该模型通过最小化负对数似然来训练。
4.Transformer-Conv:模型类似于gru 转换。变压器被用来代替GRU作为编码器来总结浮标观测中的所有信息。类似地,为了产生概率估计,对每个网格上的网络输出使用高斯混合模型。
表格是各个模型的预测评估指标对比,下图是模型预测结果的偏差对比
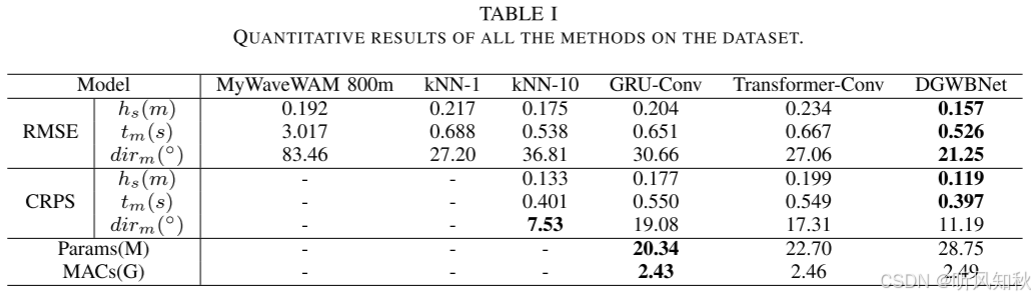
下图分别显示了不同方法测试集中3个随机场景的估计有效波高、平均波周期和平均波向。可以发现,MyWaveWAM 800m可以再现波高的整体分布,但由于分辨率较低,缺乏细节。相比之下,所有基于学习的方法都能够重建详细的波场。对于平均波周期和平均波向,这一结论是相同的。其中DGWBNet能够提供准确和详细的海况信息。
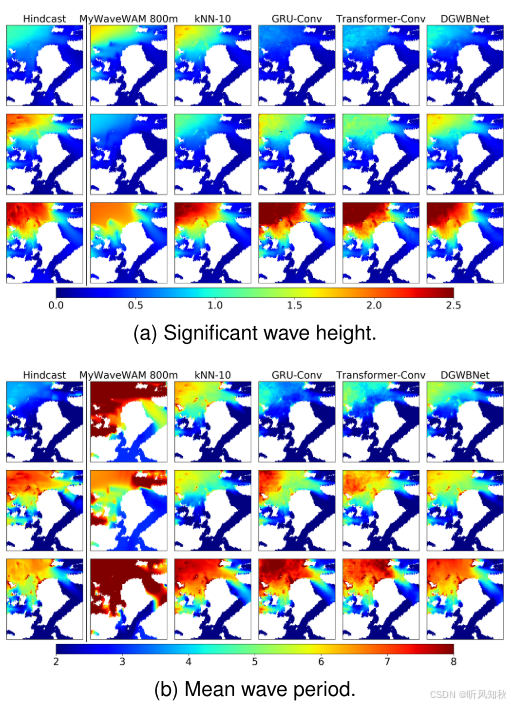
必备的实验环节了,横向对比各个模型的方法,不用说,肯定是本文模型效果好了,所以也没啥好说的,大家看看结果图,再看看作者给出的分析原因就行了”。
4.7 实验结果5:消融实验
为了验证所提出模型的设计选择,进行了烧蚀研究。特别地,我们通过消融鉴别器进行了实验。表2显示,包括鉴别器模块提高了除平均波方向的CRPS以外的所有性能。
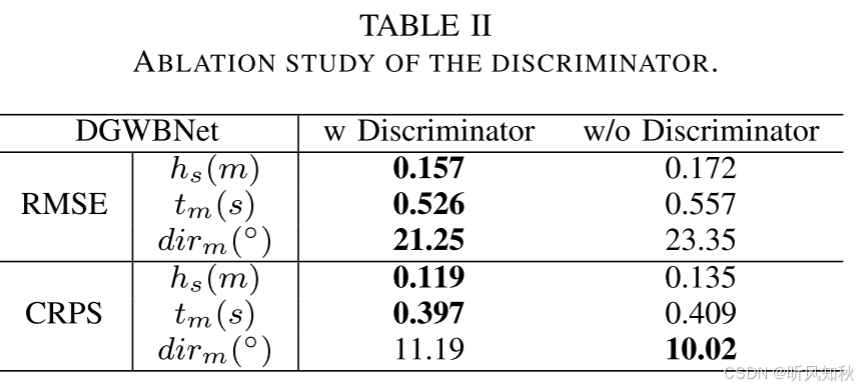
同样的,消融实验也必定会说明模型每一个结构都是必要的,也都对模型做出了贡献,这里作者特地做了鉴别器的消融实验,说明作者还是很看重模型对GAN思想的运用的,也算是本文的一个小闪光点”。
5 总结
海浪现象在影响海洋环境中的各种活动方面起着至关重要的作用。数字化的快速发展凸显了对局部区域内快速准确的波场估计的需求。局部地区复杂的地理特征,如水深的快速变化和频繁的陆水相互作用,需要高分辨率网格来准确表征波场。此外,缺乏外部大气强迫数据也增加了挑战。作为回应,我们提出了DGWGNet,一种新的方法来估计这些复杂区域的波场。即使在中等和恶劣的海况下,DGWBNet在利用稀疏波浪浮标数据重建波场方面的卓越表现,其估计不确定性和捕获变化的能力,以及其独立于物理模拟的能力,都强调了其可行性、有效性。深度学习技术在海洋现象领域的准确估计方面具有强大的潜力。我们的研究中,只需要几秒钟就可以生成局部区域的波场,这突出了模型的计算效率。通过快速提供准确的波场,一系列海上应用可以受益,例如前面提到的养鱼场、船舶作业和垃圾收集,这些应用都可以从了解波场中受益。未来的工作将考虑使用完整的波谱作为表征,而不是3个综合波参数。将研究模型在不同数据集中的验证及其与标准数据同化方法的集成,例如使用模型输出作为初始条件。
最后梳理一下全文内容,注意,模型预测时间只需要几秒钟,确实是相较于传统数值预测方法是一个很大的进步,而且计算量上也有很大提升,不需要那么多的算力”。
个人总结:
最近一直在思考一个问题:“在拥有海量参数的大模型横行的今天,预测精度、预测范围已经被这些大模型牢牢地掌控着,是否意味着低算力,小参数的小模型就没有生存空间呢?”
在与很多大模型的开发人员进行交谈之后,我发现,恰如这篇文章所做的内容,在很多局部区域,尤其是海洋数值变化剧烈的局部地区,就迫切的需要类似本文这种小巧而强悍的小模型来做针对性的预测。因为大模型做小区域预测是一件得不偿失的事情,大模型负责全局预测,突破深度学习对地球科学预测的精度上限,而小模型则专注于局部、细节上的优化和问题解决,这也算是某种互相协作,和谐共生的研究局面了。同样,这也给了很多没有那么多算力的研究人员一个有希望的探究道路。
6 作者结语
作为这个系列的第一篇文章,本人在阅读文章与精读撰写中投入了相当大的时间与精力,希望这个系列能够帮助一名刚进入学术圈的科研小白,或者帮助一位没时间详读一篇论文的科研工作者,亦或者是对这一领域的前沿技术抱有好奇之心的每一个人。
如果这篇文章对你有所帮助,请点赞与收藏!不胜感谢!
本文仅根据个人理解写作。难免有诸多不足之处,请大家不吝赐教!
ps.本文复现会很快在论文复现系列与大家见面,复现中我们可以更好的理解这篇文章的细节。我们下一篇文章再见!

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









