






-
网页图片获取
代码如下:
import requests
import os
url='https://xxxx/xx.jpg'
root='E://下载//'
path=root+split('/')[-1]
print(path)
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('success')
else:
print('exists')
except:
print('fail')
-
词频统计与词云生成
英文词云词频代码如下:
# Prince.py
import wordcloud
def getText():
txt = open("princess.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ")
return txt
princess = getText()
words = princess.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
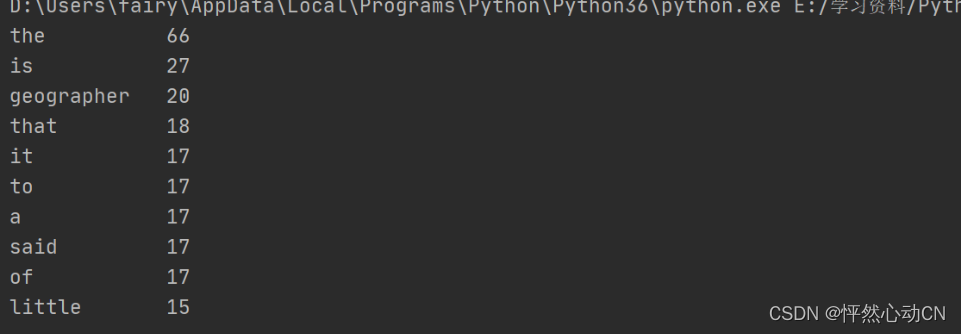
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
w = wordcloud.WordCloud(width=1000, height=700,
background_color="pink")
w.generate(getText())
w.to_file("x.png")
效果如下:
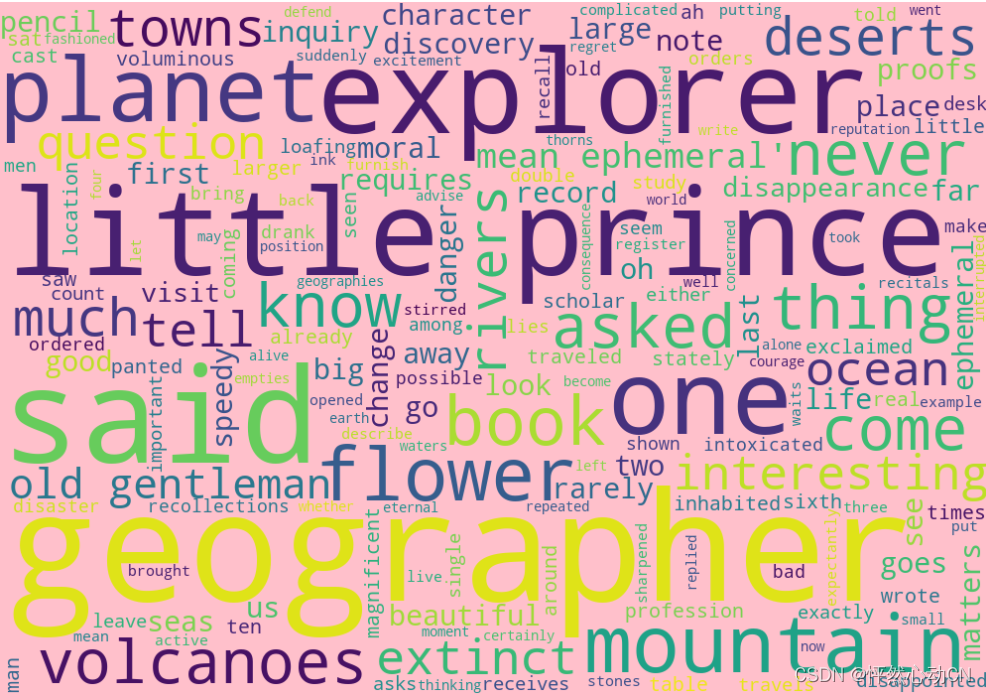
中文词云词频代码如下:
import jieba
import wordcloud
txt = open("CN_prince.txt", "r", encoding="utf-8").read()
excludes = {"这种", "非常", "可是", "如果", "了解", "这是",
"因此", "为什么", "它们", "这个", "一棵", "一个", "他们"}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
w = wordcloud.WordCloud(width=1000, height=700, font_path='msyh.ttc',
background_color="pink")
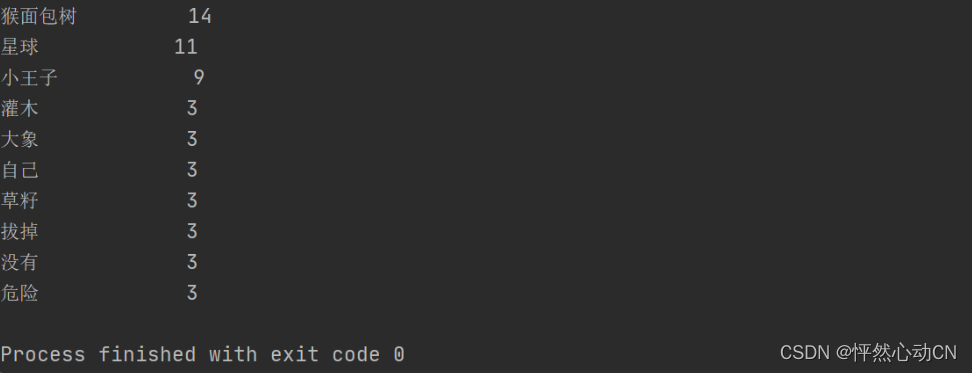
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
def getText():
s = str(words)
for ch in "'n我的是就有它们这种":
s = s.replace(ch, " ")
return s
w.generate(getText())
w.to_file("y.png")
效果如下:
















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









