









阅读英文文章时有时会出现不少这篇文章专有的一些单词,这些单词在其他地方不太可能会使用到,但是在阅读这篇文章时使用的频率可能会比较大,于是想能不能做一个工具,当你给定文章的url时,它将这篇文章中出现次数较多的那些单词统计出来。这样当你把这些单词的意义搞明白,再读这篇文章会不会压力小很多?
那么做这个工具的思路如下:
- 首先必须能够根据给定的url获取网页的正文信息或者网页的html文件;
- 如果第一步获取的是网页的html文件,那么需要根据这个html文件获取网页的正文信息;
- 网页的正文信息应该是包含字母,数字,各种标点符号,括号,空格,其他语言中的字符(比如说中文)等信息,但是在这里我要统计的是英文单词的频率,所以在这一步应该从正文信息中提取出单词(单词由26个大写字母和26个小写字母构成);
- 提取出英文单词以后就需要对这些单词进行统计,找出出现次数最多的前N(比如说10)个单词;
- 在第4步寻找过程中,某一些单词应该不参与统计,比如说a ,an ,the ,of ,and ,or ,are这类单词,这些不参加统计的单词可以由一个不参加统计的单词表表示。
根据上面的思路,每一步实现的解决方案为:
根据url获取网页的html文件,可以使用libcurl,这个库可以很方便的根据url下载html文件,然后根据html文件提取正文可以信息可以使用htmlcxx这个库,但是这个库05年就停止更新了,哪个时候的html语法和现在的都有很多区别,所以用htmlcxx提取html中的正文时有些标签识别不了,在提取正文这一步就无法处理,继续查阅了其它一些库,发现都好久没更新了,提取正文时也都会有一些小的问题。可能C++的确不太适合做这方面的工作,于是决定用java编写。
使用java编写每一步的解决方法如下:
- java就犀利多了,根据url通过htmlparse这个库解析就可以获取正文,但是有些url可以解析,有些又无法解析,查了下这个库2006年开始也没更新了,可能是这个原因吧。
- 接着继续查,发现了一个神器jsoup,这个库网上文档也比较丰富,最重要的是它现在还在更新中,并且支持html5标准,所以用这个库提取网页的正文时就没有碰到上面那些库时遇到的问题了。
- 提取正文后需要从正文字符串中获取单词,这里就可以使用java强大的正则表示了,java的正则表达式可以直接从给定的字符串中匹配到符合要求的子字符串。
- 获取单词后就要进行排序,我使用C++ reference中的页面发现一个页面大约的单词数量是一千多个,当然,这也是由于这个页面比较简单,我们需要的是统计出现次数最多的前N个单词。这里面的工作需要分成两步:1.统计每个单词出现的次数;2.找到了出现次数最多的前N个单词,更加人性化的设计是找到这N个单词后再对这N个单词进行降序排列。
这里的第4步是最关键的一步,为了统计每个单词出现的次数,可以使用HashMap和Trie树(Trie树的讲解可以参考这篇
博客),使用Trie树能够在O(L)的时间内执行插入操作(L代表字符串长度),HashMap因为要计算字符串的hashcode,所以应该也需要O(L)的操作。但是Trie没有HashMap需要处理碰撞的问题。所以这里使用Trie树来实现单词的统计。统计完后需要找到出现次数最多的N个单词,这又是一个经典的问题,就是使用一个大小为N的最小堆,遍历完Trie树后的最小堆中的元素就是出现次数最多的N个元素。最后对这N个元素执行排序操作。
在使用深度优先遍历Trie树的过程中,需要判断单词是否在不参加统计的单词表中,如果在那么不做任何处理,否则将它与最小堆(Java中堆中通过PriorityQueue这个类实现的)中的堆顶元素比较,如果它比最小堆的堆顶元素小,不做处理,否则将堆顶元素出队,并将该元素放入堆中。
下面是一些基本的数据结构和算法:
1.Trie树节点类型
//Trie树节点数据结构
public class TrieNode {
public int words;//以该节点结尾的单词数量
public int prefixs;//以该节点作为前缀的单词数量
public String str;//以该节点结尾的单词
public TrieNode[] edges;//该节点的子节点
public TrieNode() {
this.words=0;
this.prefixs=0;
this.str=null;
edges=new TrieNode[26];
for(int i=0;i<edges.length;i++)
{
edges[i]=null;
}
}
}
2.Trie树类型
包括下面这些内容:
- 一个Trie树根节点的TrieNode类型成员变量,为root,用来表示Trie树;
- 一个最小堆(PriorityQueue类型的成员变量),为priorityQueue,用来遍历Trie树时记录出现次数最多的N个节点;
- 一个不需要统计的单词表(Set<String>类型的成员变量),为tables,用来记录那些不需要统计的单词;
- 往Trie树种插入字符串的方法, void insert(String word);
- 对Trie树进行深度遍历的方法,void traversal(),遍历的过程中会将字符串和不要统计的单词做比较,将符合要求的字符串再和priorityQueue中的元素做比较,遍历完后priorityQueue中保存的元素是出现次数最多的N个单词;
- 获取出现次数最多的N个单词的方法,List<TrieNode> getTrieNodes(),这个方法会将最小堆中的元素放入集合中,并执行排序操作。
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashSet;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Queue;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Trie {
private TrieNode root=new TrieNode();
private int count=10;//要显示的前count个单词
private int init;//这个初始值和count关联,用来向最小堆中插入初始的一些元素
//定义一个最小堆
private Queue<TrieNode> priorityQueue;
//定义不需要统计的单词表
private Set<String> tables;
//因为是要求出现次数最多的那些元素,所以使用最小堆
private Comparator<TrieNode> wordOrder=new Comparator<TrieNode>() {
@Override
public int compare(TrieNode o1, TrieNode o2) {
// TODO Auto-generated method stub
int word1=o1.words;
int word2=o2.words;
if (word1<word2) {
return -1;
}
else if (word1>word2) {
return 1;
}
else
return 0;
}
};
public Trie() {
// TODO Auto-generated constructor stub
init=count;
priorityQueue=new PriorityQueue<TrieNode>(count,wordOrder);
//构建不需要统计的单词表
tables=new HashSet<String>();
String s = "[A-Za-z]+";
//下面列出不需要统计的单词
String words="a is an the h type c to of and or in for at";
Pattern pattern=Pattern.compile(s);
Matcher ma=pattern.matcher(words);
while(ma.find()){
tables.add(ma.group());
}
}
public void setCount(int c) {
count=c;
init=c;
}
//往Trie树种插入单词
public void insert(String word) {
insertHelper(root, word);
}
//真正执行插入操作的函数
private void insertHelper(TrieNode node,String word) {
if (word.length()==0) {
node.words++;
node.prefixs++;
return;
}
node.prefixs++;
char c=word.charAt(0);
c=Character.toLowerCase(c);
int index=c-'a';
if (node.edges[index]==null) {
node.edges[index]=new TrieNode();
}
insertHelper(node.edges[index], word.substring(1));
}
public void traversal() {
TrieNode[] edges=root.edges;
for(int i=0;i<edges.length;i++)
{
if (edges[i]!=null) {
String word=""+(char)('a'+i);
depthTraversal(edges[i], word);
}
}
}
//对某一个节点执行深度优先的遍历
private void depthTraversal(TrieNode node,String wordPrefix) {
if (node.words!=0) {
node.str=wordPrefix;
if (tables.contains(node.str)) {
//如果该词在不需要统计的单词表中,不需要做任何处理
}
else if(init>0)
{
init--;
priorityQueue.add(node);
}
else {
//如果大于最小堆的堆顶元素,那么将堆顶元素出队
if (node.words>priorityQueue.peek().words) {
priorityQueue.poll();
priorityQueue.add(node);
}
}
}
TrieNode[] edges=node.edges;
for(int i=0;i<edges.length;i++)
{
if (edges[i]!=null) {
String newWord=wordPrefix+(char)('a'+i);
depthTraversal(edges[i], newWord);
}
}
}
public List<TrieNode> getTrieNodes() {
List<TrieNode> list=new ArrayList<TrieNode>();
//先将优先队列中的元素取出,然后进行排序
while (!priorityQueue.isEmpty()) {
list.add(priorityQueue.poll());
}
//执行降序排列
Collections.sort(list,new Comparator<TrieNode>() {
@Override
public int compare(TrieNode o1, TrieNode o2) {
// TODO Auto-generated method stub
if (o1.words<o2.words) {
return 1;
}
else if(o1.words>o2.words){
return -1;
}
else {
return 0;
}
}
});
return list;
}
}
3.根据url获取网页正文的方法:
//根据网页的url将从网页抓取的单词插入tire树中
public static void getText3(String url,Trie trie) {
Document doc;
try {
doc=Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.64 Safari/537.31").get();
String html=doc.text();
// System.out.println(html);
String s = "[A-Za-z]+";//匹配单词,但是由英文大小写字母组成
// String s="\\w+";
Pattern pattern=Pattern.compile(s);
Matcher ma=pattern.matcher(html);
while(ma.find()){
// System.out.println(ma.group());
trie.insert(ma.group());//每次匹配一个单词,就将它插入Trie树中
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} public static void main(String[] args) {
// GUIFrame frame=new GUIFrame();
String url="http://www.cplusplus.com/reference/deque/deque/";
Trie trie=new Trie();
getText3(url, trie);
trie.traversal();
List<TrieNode> list=trie.getTrieNodes();
//打印输出出现次数最多的那些字符串
for(TrieNode t:list)
{
System.out.println(t.str+" "+t.words);
}
}上面会统计http://www.cplusplus.com/reference/deque/deque/这个网页上出现频率最高的10个单词:
在这里我定义的不需要参与统计的单词是:String words="a is an the h type c to of and or in for at";可以发现这些都是一些比较常用的,类似中文中“的”,“地”,“吗”,“把”,“一”之类的这种单词
输出:统计的结果应该还算比较准吧,这个页面是讲解deque的用法的,deque排第一位,出现了56次。
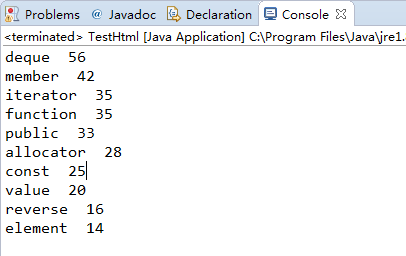
上面就是基本的算法了,但是这样的话就只能在Eclipse中运行,并且要改变统计的网页或者显示最多多少个单词时时还需要更改源代码,所以我给它做了一个简单的界面。
界面类的源码就不列出来了,整个工程的源码可以
参考附件。
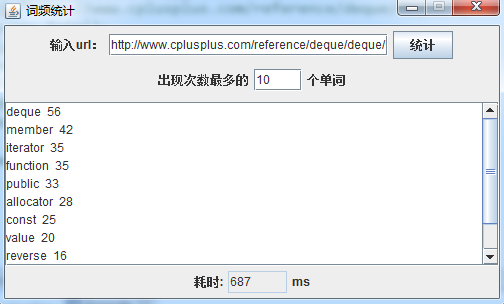
在url栏中输入要统计网页的url,在出现次数最多后面的文本框中输入要显示出现次数最多的多少个单词,点击统计按钮,下面的文本框中就会显示出现次数最多的那些单词和它的出现次数,最下面显示的这次查询和统计花费了多少时间。可执行jar文件的下载可以
参考附件。
参考的一些文章:















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









