







 YOLOv7是一个突破性的实时目标检测模型,它在速度和精度上超越了现有检测器,尤其在GPU V100上达到56.8%的AP,同时提出可训练的免费包优化策略,包括规划的模型重参数化和粗到细引导标签分配。YOLOv7不仅在速度上优于基于Transformer和卷积的检测器,而且在训练过程中无需额外数据或预训练权重,仅用MSCOCO数据集从头开始训练。
YOLOv7是一个突破性的实时目标检测模型,它在速度和精度上超越了现有检测器,尤其在GPU V100上达到56.8%的AP,同时提出可训练的免费包优化策略,包括规划的模型重参数化和粗到细引导标签分配。YOLOv7不仅在速度上优于基于Transformer和卷积的检测器,而且在训练过程中无需额外数据或预训练权重,仅用MSCOCO数据集从头开始训练。
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLOv7全文翻译
原文链接https://arxiv.org/abs/2207.02696
Github地址:https://github.com/WongKinYiu/yolov7

Abstract
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100. YOLOv7-E6 object detector (56 FPS V100, 55.9%AP) outperforms both transformer-based detector SWINL Cascade-Mask R-CNN (9.2 FPS A100, 53.9% AP) by509% in speed and 2% in accuracy, and convolutionalbased detector ConvNeXt-XL Cascade-Mask R-CNN (8.6FPS A100, 55.2% AP) by 551% in speed and 0.7% AP in accuracy, as well as YOLOv7 outperforms: YOLOR,YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B and many other object detectors in speed and accuracy. Moreover, we train YOLOv7 only on MS COCO dataset from scratch without using any other datasets or pre-trained weights. Source code is released in https://github.com/WongKinYiu/yolov7.
YOLOv7在5帧/秒到160帧/秒范围内的速度和精度都超过了所有已知的目标检测器,在GPU V100所有已知的30帧/秒以上的实时目标检测器中,YOLOv7的准确率最高,达到56.8%AP。YOLOv e6对象检测器(56 FPS V100,55.9%AP)比基于变压器的检测器SWINL级联掩模R-CNN(9.2 FPSA100,53.9%AP)速度509%,精度2%,和基于卷积的检测器convext-xl级联掩模R-CNN(86 FPA100,55.2%AP)速度551%,精度0.7%AP,以及YOLOv7在速度和精度方面优于:YOLOR,YOLO scale-yolov4,YOLOv5,DETR,变形DETR,DINO-5scale-R50,vita-adapter-b和许多其他对象测器。此外,我们只在MS COCO数据集上从无开始训练YOLOv7,而不使用任何其他数据集或先训练的权重。源代码发布在https://github.com/WongKinYiu/yolov7.
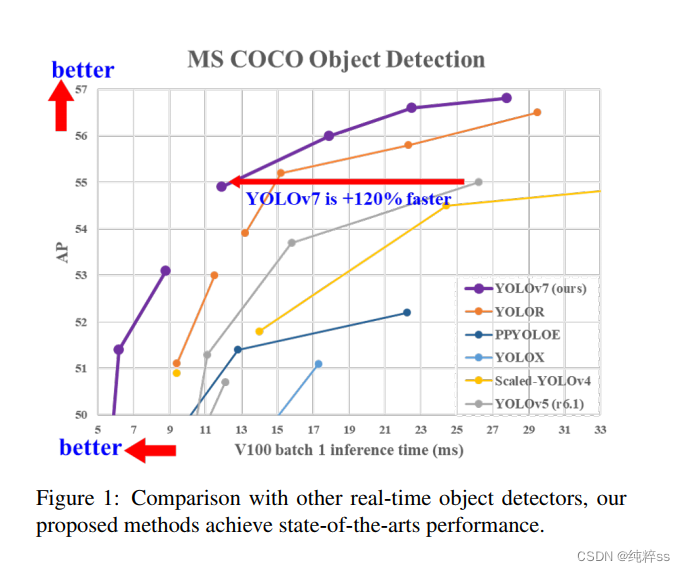
- Introduction
实时目标检测是计算机视觉中一个非常重要的课题,它往往是计算机视觉系统中必不可少的组成部分。例如,多目标跟踪[94,93],自动驾驶[40,18],机器人[35,58],医学图像分析[34,46]等。执行实时对象检测的计算设备通常是一些移动CPU或GPU,以及由主要制造商开发的各种神经处理单元(NPU)。例如,苹果的神经引擎(Apple),神经计算(Intel),Jetson的AI边缘设备(Nvidia),边缘TPU(谷歌),神经处理引擎(高通),AI处理单元(联发科),以及AI soc(Kneron),都是npu。上面提到的一些边缘设备主要用于加速不同的操作,如普通卷积、深度卷积或MLP操作。在本文中,我们提出的实时目标检测器主要是希望它能够同时支持移动GPU和GPU设备,从边缘到云端。近年来,针对不同的边缘设备,仍在开发实时目标检测器。例如,发展图1:与其他实时物体探测器的比较,我们提出的方法达到了最先进的性能。MCUNet[49,48]和NanoDet[54]的改进主要集中在产生低功耗的单片机和提高边缘CPU的推理速度。而YOLOX[21]和YOLOR[81]等方法则专注于提高各种gpu的推理速度。近年来,实时目标检测器的发展主要集中在高效体系结构的设计上。至于可以在CPU上使用的实时目标检测器[54,88,84,83],它们的设计大多基于MobileNet[28,66,27],ShuffleNet[92,55],或GhostNet[25]。另一种主流的实时目标检测器是针对GPU开发的[81,21,97],它们大多使用ResNet[26]、DarkNet[63]或DLA[87],然后使用CSPNet[80]策略来优化架构。本文提出的方法的发展方向不同于目前主流的实时目标检测器。除了架构优化之外,我们提出的方法将重点放在培训过程的优化上。我们将重点讨论一些优化的模块和优化方法,这些模块和优化方法可以在不增加推理成本的情况下,加强训练成本以提高目标检测的准确性。我们把提出的模块和优化方法称为可训练的免费包。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4791
4791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









