




 YOLOv7通过引入可训练的bag-of-freebies,实现了从5FPS到160FPS速度与精度的显著提升,超越了众多物体检测器,包括Transformer和卷积模型。方法还包括模型重构、扩展效率层聚合网络和复合模型缩放,仅在MS COCO上从头开始训练。
YOLOv7通过引入可训练的bag-of-freebies,实现了从5FPS到160FPS速度与精度的显著提升,超越了众多物体检测器,包括Transformer和卷积模型。方法还包括模型重构、扩展效率层聚合网络和复合模型缩放,仅在MS COCO上从头开始训练。
目录
2.1. Real-time object detectors
2.2. Model re-parameterization
3.1 Extended efficient layer aggregation networks
3.2 Model scaling for concatenation-based models
4.1 Planned re-parameterized convolution
4.2. Coarse for auxiliary and fine for lead loss
4.3. Other trainable bag-of-freebies
5.3. Comparison with state-of-the-arts
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
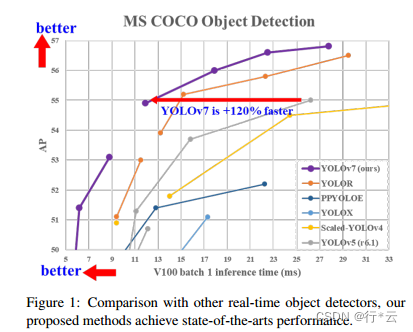
YOLOv7在5FPS到 160 FPS 范围内的速度和准确度都超过了所有已知的物体检测器,YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时目标检测器中具有最高的准确度 56.8% AP。YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于transformer-based的检测器 SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出 509% 和 2%,以及基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高 551%,准确率提高 0.7%,以及 YOLOv7 的表现优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR , DINO-5scale-R50, ViT-Adapter-B 和许多其他物体探测器在速度和准确度上。 此外,我们只在 MS COCO 数据集上从头开始训练 YOLOv7,而不使用任何其他数据集或预训练的权重。 源码发布在: https://github.com/WongKinYiu/yolov7
Introduction
实时对象检测是计算机视觉中非常重要的主题,因为它通常是计算机视觉系统中的必要组件。 例如,多目标跟踪[94, 93],自动驾驶[40, 18],机器人[35, 58],医学图像分析[34, 46]等。执行实时目标检测的计算设备通常是一些移动CPU或GPU,以及各大厂商开发的各种神经处理单元(NPU)。 比如苹果神经引擎(Apple)、神经计算棒(Intel)、Jetson AI边缘设备(Nvidia)、边缘TPU(谷歌)、神经处理引擎(Qualcomm)、AI处理单元(MediaTek)、 和 AI SoC(Kneron)都是 NPU。 上面提到的一些边缘设备专注于加速不同的操作,例如普通卷积、深度卷积或 MLP 操作。 在本文中,我们提出的实时目标检测器主要希望它能够同时支持移动 GPU 和从边缘到云端的 GPU 设备。
近年来,实时目标检测器仍在针对不同的边缘设备进行开发。例如,开发MCUNet [49, 48] 和 NanoDet [54] 的运营专注于生产低功耗单芯片并提高边缘 CPU 的推理速度。 至于 YOLOX [21] 和 YOLOR [81] 等方法,他们专注于提高各种 GPU 的推理速度。 最近,实时目标检测器的发展集中在高效架构的设计上。 至于可以在 CPU [54, 88, 84, 83] 上使用的实时目标检测器,他们的设计主要基于 MobileNet [28, 66, 27]、ShuffleNet [92, 55] 或 GhostNet [25] . 另一个主流的实时目标检测器是为 GPU [81, 21, 97] 开发的,它们大多使用 ResNet [26]、DarkNet [63] 或 DLA [87],然后使用 CSPNet [80] 策略来优化架构。 本文提出的方法的发展方向与当前主流的实时目标检测器不同。 除了架构优化之外,我们提出的方法将专注于训练过程的优化。 我们的重点将放在一些优化的模块和优化方法上,它们可能会增加训练成本以提高目标检测的准确性,但不会增加推理成本。我们将提出的模块和优化方法称为可训练的bag-of-freebies。
最近,模型重新参数化[13,12,29]和动态标签分配[20,17,42]已成为网络训练和目标检测的重要课题。 主要是在上述新概念提出之后,物体检测器的训练演变出了很多新的问题。 在本文中,我们将介绍我们发现的一些新问题,并设计解决这些问题的有效方法。对于模型重参数化,我们用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。 此外,当我们发现使用动态标签分配技术时,具有多个输出层的模型的训练会产生新的问题。即:“如何为不同分支的输出分配动态目标?” 针对这个问题,我们提出了一种新的标签分配方法,称为coarse-to-fine引导式标签分配
本文的贡献总结如下:(1)我们设计了几种可训练的bag-of-freebies方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度;(2) 对于目标检测方法的演进,我们发现了两个新问题,即重新参数化的模块如何替换原始模块,以及动态标签分配策略如何处理分配给不同输出层的问题。 此外,我们还提出了解决这些问题所带来的困难的方法;(3) 我们提出了实时目标检测器的“扩展”和“复合缩放”方法,可以有效地利用参数和计算; (4) 我们提出的方法可以有效减少最先进的实时目标检测器约40%的参数和50%的计算量,并且具有更快的推理速度和更高的检测精度。
2 Related work
2.1. Real-time object detectors
目前最先进的实时目标检测器主要基于 YOLO [61, 62, 63] 和 FCOS [76, 77],分别是 [3, 79, 81, 21, 54, 85, 23] . 能够成为最先进的实时目标检测器通常需要以下特性:(1)更快更强的网络架构; (2) 更有效的特征整合方法[22, 97, 37, 74, 59, 30, 9, 45]; (3) 更准确的检测方法 [76, 77, 69]; (4) 更稳健的损失函数 [96, 64, 6, 56, 95, 57]; (5) 一种更有效的标签分配方法 [99, 20, 17, 82, 42]; (6) 更有效的训练方法。 在本文中,我们不打算探索需要额外数据或大型模型的自我监督学习或知识蒸馏方法。 相反,我们将针对与上述 (4)、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4897
4897


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








