







DeepSeek 是一款国产的大型语言模型,因其在自然语言处理、代码生成和多轮对话等任务中的出色表现,迅速引起了广泛关注。为了避免因服务器繁忙导致的使用不便,您可以选择将 DeepSeek 部署在本地,这样无需依赖云端服务即可享受 AI 带来的便利。
简介
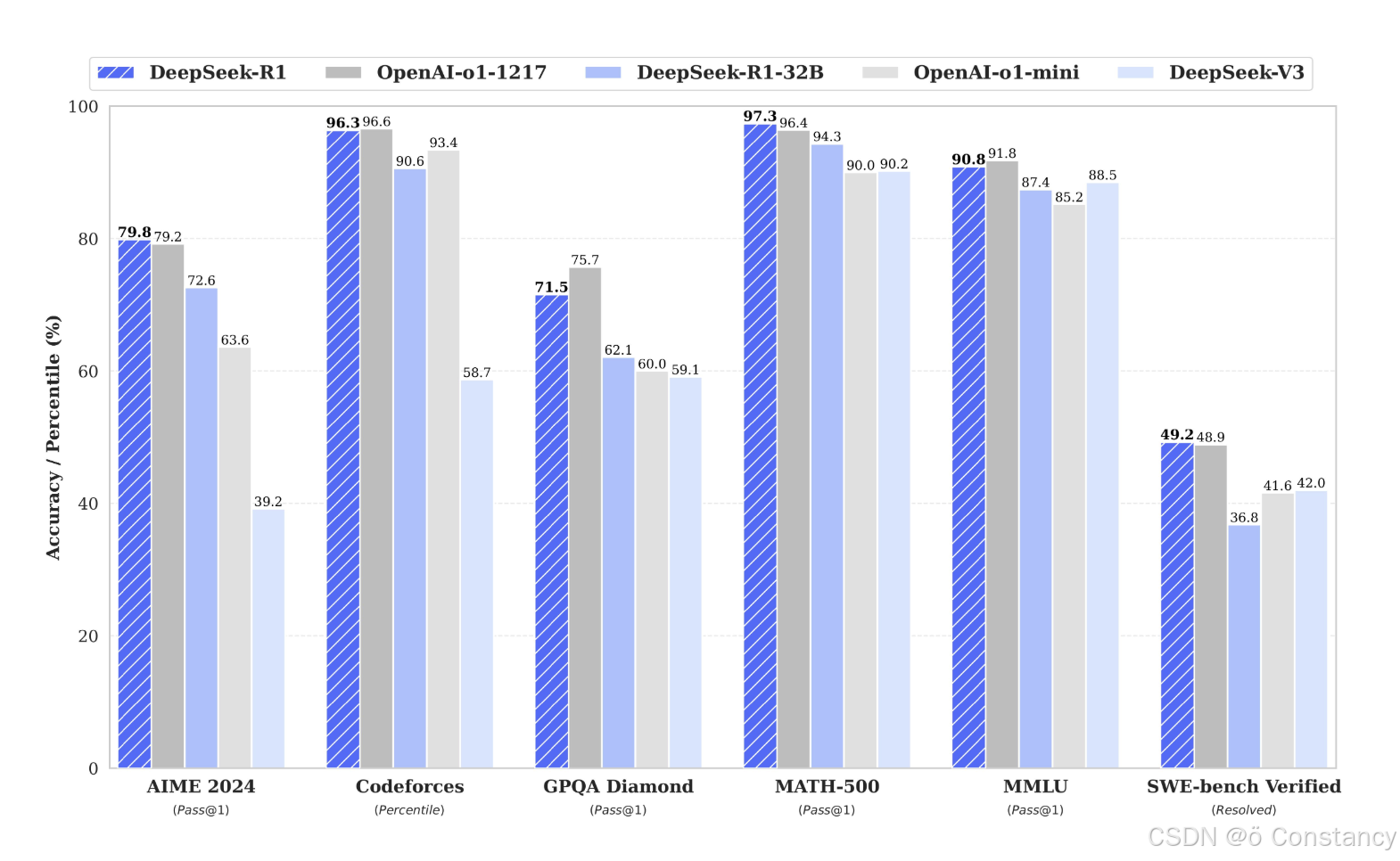
DeepSeek 是一家中国初创企业,因其高性能、低成本的生成式 AI 大规模语言模型而备受关注。其最新发布的模型“R1”在推理能力上进行了强化学习,展现出了与 OpenAI 的 GPT-4 相当的性能。 在代码能力方面,DeepSeek 的 DeepSeek-V3 模型在 Aider 代码能力排行榜中取得了 48.4% 的正确率,仅次于 OpenAI 的 o1,超过了 Claude 3.5 Sonnet。
Deepseek的跑分对比(图片来自官网):
DeepSeek 本地部署指南
如果你希望在本地环境中部署DeepSeek,以下是一些详细的步骤和注意事项:
1. 准备硬件环境
-
处理器/GPU:确保你的服务器或工作站配备至少一个高性能的GPU(如NVIDIA显卡),因为深度学习任务通常需要大量的计算
资源。 -
内存:建议至少有8GB以上的内存,具体需求取决于你要处理的数据量和模型规模。
-
存储空间:提供足够的存储空间来下载或存储训练数据、预训练模型以及其他相关文件。如果你在本地进行数据处理和训练,还需要考虑到存储需求的增长。
2. 安装必要软件
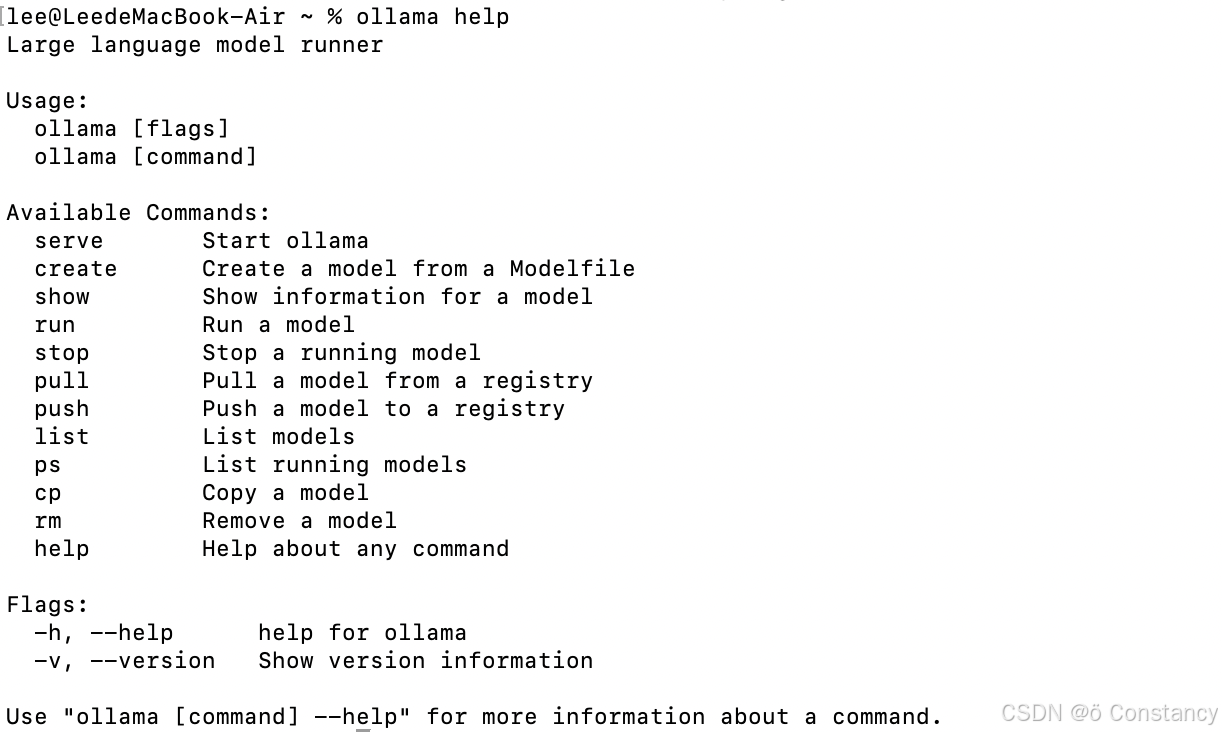
安装 Ollama: Ollama 是一款开源的本地大模型运行工具,支持多种操作系统。您可以访问其官网 ollama.com下载适用于您操作系统的安装包。安装完成后,打开命令提示符(Windows)或终端(macOS、Linux),输入 ollama help 并按回车键,以验证安装是否成功。
3.下载并部署 DeepSeek 模型
在 Ollama 官网的搜索栏中输入 deepseek-r1,选择适合您硬件配置的模型版本。不同版本对硬件的要求不同,您可以参考以下配置:
| 模型版本 | 参数量 | 显存需求(FP16) | 推荐 GPU(单卡) | 适用场景 |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 15亿 | 3GB | GTX 1650(4GB 显存) | 低资源设备部署、实时文本生成 |
| DeepSeek-R1-7B | 70亿 | 14GB | RTX 3070/4060(8GB 显存) | 中等复杂度任务、轻量级多轮对话系统 |
| DeepSeek-R1-8B | 80亿 | 16GB | RTX 4070(12GB 显存) | 需更高精度的轻量级任务 |
| DeepSeek-R1-14B | 140亿 | 32GB | RTX 4090/A5000(16GB 显存) | 企业级复杂任务、长文本理解与生成 |
选择合适的模型后,复制相应的命令,在命令提示符或终端中粘贴并运行,以下载并部署模型。下载完成后,您可以通过命令 ollama run deepseek-r1 来运行模型。

4. 使用可视化界面(可选)
为了获得更友好的交互体验,您可以使用 Chatbox 这类可视化图文交互界面。访问 chatboxai.com,选择适合的版本进行安装。安装完成后,在设置中选择使用本地模型,并配置为使用 Ollama 提供的 DeepSeek 模型。这样,您就可以通过图形界面与模型进行交互。


















 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











