






一、硬件参数
| H100 SXM5 | H100 PCIe | |
| 核心 | GH100 | GH100 |
| 架构 | Hopper | Hopper |
| SM | 132 | 114 |
| CUDA Cores / SM | 128 | 128 |
| CUDA Cores / GPU | 16896 | 14592 |
| FP32 Cores / SM | 128 | 128 |
| FP32 Cores / GPU | 16896 | 14592 |
| FP64 Cores / SM | 64 | 64 |
| FP64 Cores / GPU | 8448 | 7296 |
| INT32 Cores / SM | 64 | 64 |
| INT32 Cores / GPU | 8448 | 7296 |
| Tensor Core | 4th | 4th |
| Tensor Cores / SM | 4 | 4 |
| Tensor Cores / GPU | 528 | 456 |
| GPU 加速频率 (MHz)* | 1830 / 1980 | 1620 / 1755 |
| 显存 | 80 GB HBM3 | 80 GB HBM2e |
| 显存位宽 (bit) | 5120 | 5120 |
| 显存带宽 (GBps) | 3352 | 2039 |
| 一缓 (KB per SM) | 256 | 256 |
| 二缓 (MB) | 50 | 50 |
| 接口 | SXM5 | PCIe 5.0x16 |
| TDP (W) | 700 | 350 |
| 制程 | TSMC 4N (5nm) | TSMC 4N (5nm) |
* 第一项为 Tensor Core 计算 FP8、FP16、BF16、TF32 时的加速频率,第二项为 Tensor Core 计算 FP64 和 CUDA Core 计算 FP32、FP64 时的加速频率。
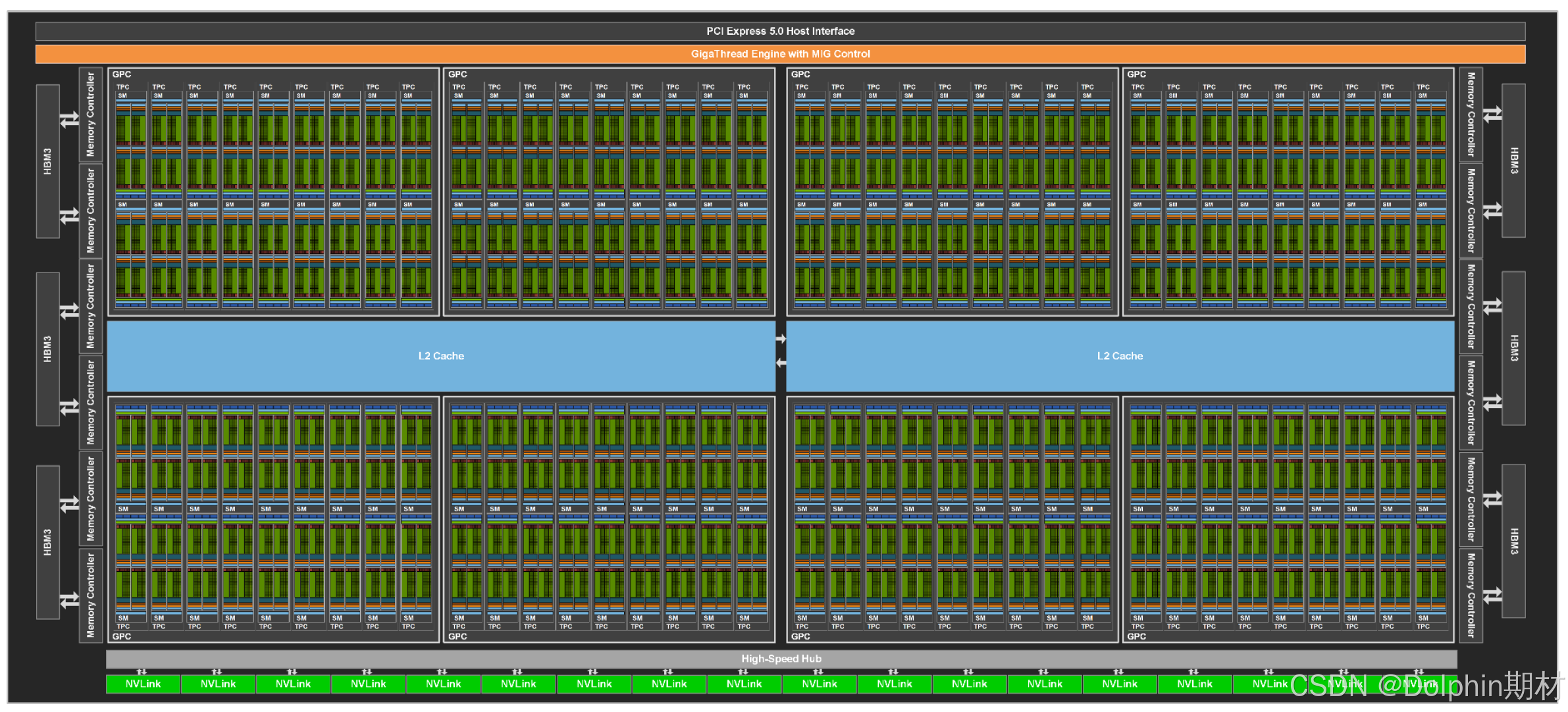
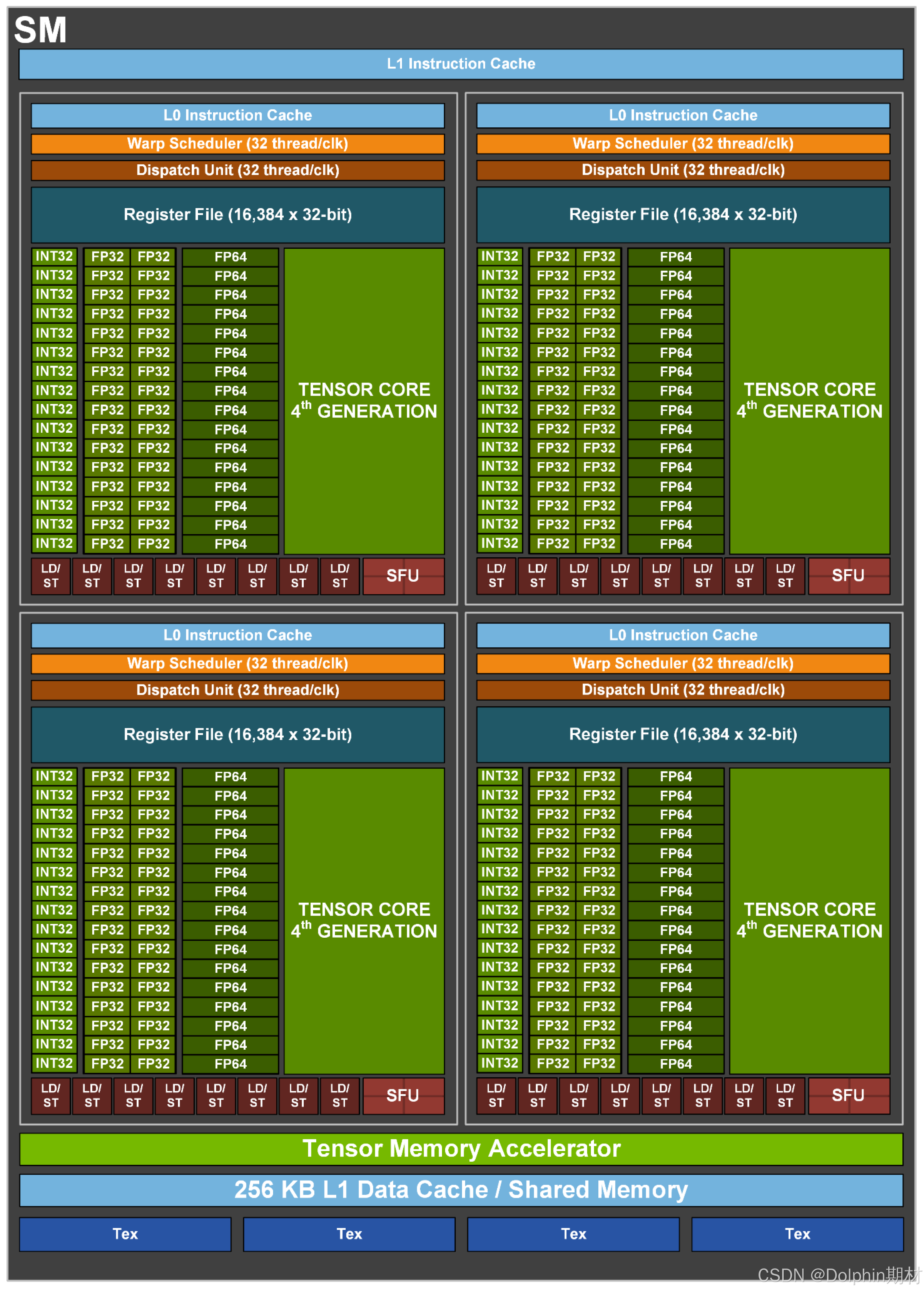
注意到,完整 GH100 核心有 8 组 GPC,每组 GPC 包含 9 组 TPC,单个 TPC 中含有两个 SM 单元,因此完整 GH100 核心共有 144 个 SM 单元,但 H100 SXM5 的 GH100 核心只开启其中的 132 个,H100 PCIe 的 GH100 核心只开启其中的 114 个。每个 SM 单元中有 128 个 CUDA 计算单元。每个 SM 单元中有 128 个 FP32 计算单元、64 个 INT32 计算单元和 64 个 FP64 计算单元。
每个 SM 单元中有 4 个 Tensor Core,因此 H100 SXM5 的 GH100 总共含有 528 个 Tensor Core,H100 PCIe 的 GH100 总共含有 456 个 Tensor Core。支持的数据类型有FP8、FP16、BF16、TF32、FP64、INT8、INT4。
二、算力
1、CUDA Core 算力
浮点:TFLOPS
整型:TIOPS
| H100 SXM5 | H100 PCIe | |
| FP32 | 66.9 | 51.2 |
| FP16 | 133.8 | 102.4 |
| FP64 | 33.5 | 25.6 |
| BF16 | 133.8 | 102.4 |
| INT32 | 33.5 | 25.6 |
2、Tensor Core 算力
浮点:TFLOPS
整型:TIOPS
稠密/稀疏
| H100 SXM5 | H100 PCIe | |
| FP8 | 1978.9 / 3957.8 | 1513 / 3026 |
| FP16 | 989.4 / 1978.9 | 756 / 1513 |
| BF16 | 989.4 / 1978.9 | 756 / 1513 |
| TF32 | 494.7 / 989.4 | 378 / 756 |
| FP64 | 66.9 | 51.2 |
| INT8 | 1978.9 / 3957.8 | 1513 / 3026 |
| INT4 | 3957.8 / 7915.6 | 3026 / 6052 |

















 2876
2876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









