






论文翻译-Faster reinforcement learning after pretraining deep networks to predict state dynamics
这里写自定义目录标题
Abstract
深度学习算法最近出现了,它以无监督的方式对神经网络的隐藏层进行预训练,从而在大型分类问题上获得了最先进的性能。这些方法也可以对用于强化学习的网络进行预训练。然而,这忽略了通过正在进行的状态、动作、新的状态元组序列,在强化学习范式中存在的额外信息。本文证明了学习一个状态动态的预测模型可以得到一个预先训练的隐藏层结构,从而减少解决强化学习问题所需的时间。
INTRODUCTION
多层人工神经网络作为新标记的“深度学习”研究领域的关键组成部分,近年来受到广泛关注。当应用于大型数据集时,如图像、视频和语音,训练深度网络的直接算法通常会产生最先进的分类性能。正如Mnih等人[1],[2]所指出的,强化学习不同于通常用于精细时间深度网络的监督学习方法。强化学习问题需要从对学习主体的行为的评估中学习,而不是从来自训练数据集的正确的、已知的输出中学习。
Mnih等人继续确定必须解决的关键问题,以发展强化学习方法(RL)。这些问题源于这样一个事实:当RL代理学习时,它的行为改变,迫使RL代理执行的世界进入新的状态。RL代理和它的世界之间的相互作用导致了一系列不断发展的新体验,这种情况与具有一组固定的训练数据的监督学习框架有很大的不同。其他的问题是由于强化值经常被延迟和稀疏的时间。所有这些问题都导致人们认为解决RL问题的算法是低效的,需要大量的交互来找到近似最优的策略——将感知到的世界状态映射到行动中的函数。
解决RL问题的一种常见方法是学习一个值函数,该函数从感知到的世界状态和所采取的行动中预测未来强化的预期总和。一系列的研究都致力于减少解决RL问题所需的交互数量。对于许多RL问题,只有将值函数设计为连续值状态和动作,才能得到最好的结果,而对于这些状态和动作的收敛证明才刚刚开始出现在文献[3],[4]中。在实际方面,目前使用连续函数逼近器求解RL问题的算法仍然非常缓慢,需要大量的状态和动作样本来学习成功的策略。
减少所需样本数量的一个明显的方法是使用一个世界模型来生成额外的样本,以近似于那些可以从现实世界中获得的样本。这是萨顿在他的DYNA算法[5]中所采用的方法。模型也可以用于评估多个未来的行动序列,通过将它们应用于模型,如代森罗斯和拉斯穆森的PILCO算法[6]。
本文描述的方法介绍了学习模型的另一个用途。它可以很容易地与刚才提到的基于模型的方法相结合,但我们在这里不这样做。相反,我们的重点是将从学习模型发展而来的状态-动作表征转移到学习Q函数来预测强化的过程中。模型的表示用于初始化Q函数的表示,假设模型的表示包含与预测强化所需的特征相似。如果这对于给定的RL问题是正确的,则将减少所需样本的数量。这种表示的转移也可以被认为是一种预训练Q函数的方法,使用任何策略观察到的状态,甚至是随机策略。这种预训练发生在与RL问题目标相关的任何信息被提出之前,即强化信号。
人们普遍认为,预测允许动物预测它们的行为的有利和灾难性的结果。这种预测在动物学习文献中得到了充分的研究,其特征是工具和经典条件反射范式,这是强化学习领域的基础。在这里,我们研究了一个预测模型的一个更微妙的效用——一个对世界的详细表示,它提供了一个框架来估计未来的强化。
本文使用神经网络作为Q函数逼近器,或Q网络。神经网络的隐藏层包括从状态动态预测问题转移到强化学习问题的表示。在第二节中,我们回顾了作为Q函数的近似值的神经网络。并总结了深度学习对强化学习的最新贡献。在第三节中,我们描述了我们对Q网络进行预训练的方法。第四节总结了该方法应用于几种动态控制任务的实验和结果。
Q NETWORKS
自20世纪80年代的[7],[8],[9],[10]以来,神经网络一直被用作连续Q函数逼近器。这些工作和随后的许多工作使用随机梯度下降来优化Q网络的近似到未来增强的期望和,因此在所需的样本数量方面相当低效。更有效的方法训练神经网络的监督学习问题发展在近似的二阶梯度。在RL框架中利用这种方法的一种方法是将样本序列组合成批次,从中可以获得二阶和共轭梯度信息。例如里德米勒[11]的神经拟合-q方法。
Lange和里德米勒·[12]将这种方法与来自深度学习社区的新想法相结合,以预先训练神经网络的隐藏层。首先对神经网络的隐藏层进行训练,形成自动编码器。然后使用这些层作为Q网络的初始化。
兰格和里德米勒的方法,以及本文提出的方法,证明了对于多层神经网络,传输表示可以像替换输出层一样简单。兰格和里德米勒通过强迫信息流通过比输入组件更少单元的隐藏层来优化输入的再现,这是一种非线性降维形式,类似于Kramer [13]的早期工作。由此产生的低维表示很可能会减少解决后续RL问题所需的样本数量。如果没有这样的预训练,在解决RL问题时,就必须学习低维表示,这需要更多的样本。
如果网络结构包含比输入维数更少单元的隐层,我们的方法还将发展一个非线性降维。然而,兰格和里德米勒的方法和我们的方法在预训练过程中进行的优化方面有一个根本的区别。我们的方法不是以自动编码器的方式重建输入,而是建模世界的动态和代理的行为对它的影响。预计,捕捉世界动态各个方面的特性将对预测未来的强化非常有用,导致所需的样本减少,超过通过自动编码器预训练获得的样本。
PRETRAINING OF HIDDEN UNITS(隐藏单元预训练)
这里使用的神经网络结构如图1所示。神经网络的隐藏单元形成自适应表示,输出单元结合起来近似于期望的函数。图中显示了通常的Q函数输出,但它也显示了表示状态𝑠的变化的附加输出。可以训练一个单个神经网络来预测状态变化和预测未来增强的总和,即Q函数,如图1所示。本图中隐含的计算细节将在后面介绍。本文所探索的假设是,隐藏单元中的表示对预测状态变化很有用,也将有助于预测未来增强的总和。
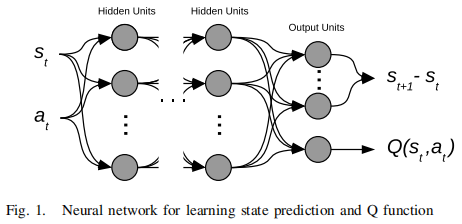
量的动力学在本质上是随机的。这里用于状态动力学建模和未来强化的算法使期望值最小化,因此可以处理可观察变量和强化的一定程度的随机性。
为了对神经网络进行预训练,我们收集了状态、 𝑠 𝑡 𝑠_𝑡 st、动作、 𝑎 𝑡 𝑎_𝑡 at和下一个状态 𝑠 𝑡 + 1 𝑠_{𝑡+1} st+1的样本。 𝑠 𝑡 𝑠_𝑡 st和 𝑎 𝑡 𝑎_𝑡 at的每个样本构成了网络的一个输入向量。这个输入向量的正确输出,或目标值,是 𝑠 𝑡 + 1 − 𝑠 𝑡 𝑠_{𝑡+1}−𝑠_𝑡 st+1−st。只是下一个状态, 𝑠 𝑡 + 1 𝑠_{𝑡+1} st+1,也可以用作目标值,但状态从一个时间步到下一个通常非常相似,所以神经网络驱动学习一个身份地图和更多的训练需要学习所需的小变化来准确预测下一个状态。将输入和目标输出值组合成矩阵,利用Møller的尺度共轭梯度(SCG)算法[14]来最小化神经网络输出的均方误差。SCG是一种共轭梯度方法,它用近似的二阶最小化取代了典型的线搜索步骤。在这个预训练阶段,没有使用关于强化学习问题的目标的知识,并且忽略了神经网络的Q值输出。
经过预训练后,采取了类似于里德米勒的神经拟合Q算法的步骤。收集少量 𝑠 𝑡 𝑠_𝑡 st、 𝑎 𝑡 𝑎_𝑡 at、 𝑟 𝑡 + 1 𝑟_{𝑡+1} rt+1、 𝑠 𝑡 + 1 𝑠_{𝑡+1} st+1和 a 𝑡 + 1 a_{𝑡+1} at+1。使用𝜖-贪婪算法选择动作𝑎。再次应用Møller的SCG算法来训练输出的Q值,以近似未来强化的和。在此阶段中,状态更改输出将被忽略。遵循SARSA算法[15],形成误差最小化,总结如下。
网络输出的Q输出值
𝑄
(
𝑠
𝑡
,
𝑎
𝑡
)
𝑄(𝑠_𝑡,𝑎_𝑡)
Q(st,at)由输入𝑠𝑡和𝑎𝑡决定。我们希望这个函数能形成近似值
Q
(
s
t
,
a
t
)
≈
E
[
∑
k
=
0
∞
γ
k
r
t
+
k
+
1
]
Q(s_t,a_t)\approx E[\sum_{k=0}^\infty \gamma^k r_{t+k+1}]
Q(st,at)≈E[∑k=0∞γkrt+k+1]
其中,0<𝛾≤1为折扣系数。使用𝜖贪婪策略𝜋(𝑠𝑡)选择动作,
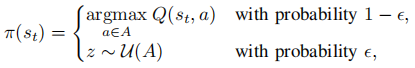
其中,𝑧是从有效动作集合𝐴中抽取的均匀分布的随机变量。如果每个小批由从时间𝑡1到时间𝑡𝑛收集的𝑛样本组成,那么每个小批的SARSA误差最小化为
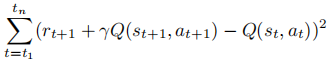
对于
𝑡
=
𝑡
1
,
.
.
.
,
𝑡
𝑛
𝑡=𝑡_1,...,𝑡_𝑛
t=t1,...,tn,的一小批𝑛样本,
(
𝑠
𝑡
,
𝑎
𝑡
,
𝑟
𝑡
+
1
,
𝑠
𝑡
+
1
,
𝑎
𝑡
+
1
)
(𝑠_𝑡,𝑎_𝑡,𝑟_{𝑡+1},𝑠_{𝑡+1},𝑎_{𝑡+1})
(st,at,rt+1,st+1,at+1)的误差梯度相对于神经网络的权重,驱动了由Møller的SCG算法执行的误差最小化。
重要的是不要将𝑄函数过拟合到每个小批样本中。每个小批都是一个样本,仅限于所经历的世界状态的特定序列。因此,应用SCG算法对每个小批量进行少量的迭代。对于这里报告的实验,它只应用了20次迭代。经验重放可以减少所报告实验的样本总数。这是通过计算小批样本的新的𝑄值和使用SCG进行20次再训练来实现的。每个小批量重复经验重复10次。
在下一节中,我们总结了涉及模拟动态系统控制的两个RL问题的实验结果。比较了不同数量的预训练样本的性能,包括零。
EXPERIMENTS
采用两个简单的动态系统来研究预训练的优势。第一个系统是一维轨道上的简单质量或推车。第二个是一个基准车和杆系统,杆是平衡的。我们使用了一个独特的模拟,其中包括手推车与轨道末端的碰撞。
Cart
考虑一个质量,或推车,它可以沿着位置1和10的水平轨道移动时向左或向右推,并且从位置2到4有一个增加的摩擦区域,如图2所示。
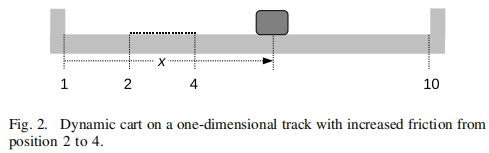
强化学习问题的定义是要求一系列推,使车保持接近给定的位置。让时间𝑡的购物车状态为
𝑠
𝑡
=
(
𝑥
𝑡
,
x
˙
𝑡
)
𝑇
𝑠_𝑡=(𝑥_𝑡,\dot x_𝑡)^𝑇
st=(xt,x˙t)T,时间𝑡的推为
𝑎
𝑡
𝑎_𝑡
at∈{−1,0,1},这将被称为动作。用欧拉的方法可以模拟状态的演化
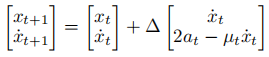
其中,Δ=为0.1,Font metrics not found for font: .为摩擦系数,由下计算
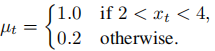
通过边界𝑥为1和10并设置
x
˙
\dot x
x˙=0来模拟与壁的非弹性碰撞。设𝑔𝑡为目标位置,从1到10。时刻𝑡时的reinforcement值为
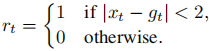
为了使这个任务更具挑战性,我们使用了5个额外的状态变量,它们只是简单地从从0到1的均匀分布中抽取出来的。在训练前,这些变量的变化被包括在状态变化模型的优化中。使这项简单任务更具挑战性的其他方法是在赛道上添加丘陵,并改变某些州[16]的行动效果。
本实验的Q网络结构为8个输入,20个隐藏层中的单个隐藏单元,8个输出,即8-20-8。这八个输入包括两个状态变量,位置和速度,五个随机变量,和动作。这8个输出分别是两个状态变量的预测变化、5个随机变量的预测变化以及𝑄值。所有单元也接收一个恒定的1偏置输入。隐单元使用对称的tanh激活函数,输出单元是线性的。由于SCG算法决定了步长,因此不需要学习率。
为了生成用于预训练的样本,推车初始化为零速度随机位置和随机目标位置。操作随机选择。每取100个样本,目标就会被更改为一个新的随机值。
在预训练期间,Q的输出值将被忽略。经过预训练后,忽略状态变化输出,并对Q输出进行训练。同样,购物车被初始化为一个零速度的随机位置和一个随机的目标位置。采用𝜖贪婪算法选择一个动作,并将其应用于购物车,观察下一个状态和强化。这是重复了1000步,目标每100步改变为一个新的随机值。1000步的小批处理用于更新Q网络,同时忽略状态变化输出。
这将对100个这样的小批次进行重复操作。𝜖的值设置为常量0.1,𝛾的值设置为0.9。为了评估预训练神经网络以最小化预测状态变化的效果,我们对不同数量的预训练样本运行上述程序。对每个训练前样本重复30次。
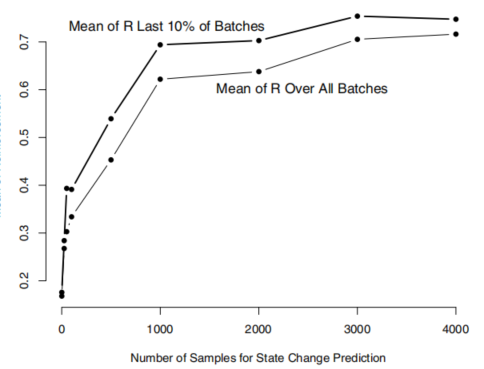
图3。预训练对预测状态变化的优势,显示为对越来越多的预训练样本所实现的强化的平均值。所有训练样本和最后10个小批次样本的强化平均值显示。
在每次运行中,性能是通过所有钢筋的平均值和在最后10个小批次中接收到的钢筋的平均值来衡量的。图3显示了两种性能度量与训练前样本的数量。回想一下,强化为零,直到目标在2以内,此时强化为1。所以,平均值为0.7意味着目标区域会很快到达。这个图显示,没有预先训练,目标很少达到。随着预训练样本的增加,性能稳步提高,增长最快的是从0到1000个预训练样本。所有钢筋的平均值和最后10%的相似性表明,在每次运行的早期都取得了良好的性能。在多个初始状态下启动系统,利用𝜖=0的𝜖贪婪策略观察训练后的神经网络控制下状态的演化情况,验证了系统良好的性能。如图4所示,目标设置在位置8。
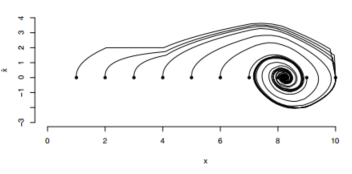
图4。通过训练好的神经网络成功控制,显示了多个初始值的状态演化,用填充圆标记。目标是在第8位。
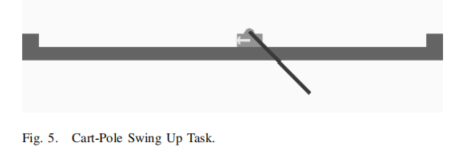
Cart-Pole Swing Up
在推车中添加一个二维摆动的极点会导致基准极点平衡问题,Barto等人[17]首先在强化学习领域进行了研究。这个基准测试问题在这里以两种方式进行了修改。首先,使用基于pybox2d库的pybox2d包对动态系统进行模拟。这允许与轨道的末端发生真实的碰撞。第二个区别是,杆子可以摆动通过整个360∘,而不是被限制在在原始基准问题中使用的直立位置附近的一个小角度。其他发表的极平衡问题的结果允许全角度范围,但许多包含了一个这里没有使用的动力学模型。图5显示了轨道上的手推车和杆子。
这个系统的状态是四维的:推车位置,
𝑥
𝑡
𝑥_𝑡
xt,它的速度,
x
˙
𝑡
\dot x_𝑡
x˙t,极角,𝜃𝑡,和它的角速度,
θ
˙
𝑡
\dot \theta𝑡
θ˙t。当杆点直线向上时,Font metrics not found for font: .,当它向下摆动时,它接近负或正180∘。这个问题的强化函数根据角度定义的:
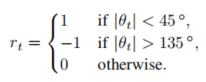
在30 Hz的采样率下模拟系统的动力学,RL代理在15Hz的采样率下应用一个新的动作。
在这个实验中,Q网络有5个输入,1到5个隐藏层,每层20个单元,和5个输出。输入是四个状态变量和动作。输出是对四个状态变量和𝑄值的变化的预测。
为了收集训练前的样本,车杆系统在轨道中心启动,杆垂下来。应用随机操作,并收集结果状态。SCG算法运行了1000次迭代,以最小化预测状态变化中的平方误差,同时忽略输出的𝑄值。训练后,车杆再次从中心开始,杆垂下来。采用𝜖贪婪策略选择动作,𝜖常量值为0.1。收集100个小批,共1000个样本,每个小批应用SCG,迭代20次,重复10次经验重放,同时忽略状态变化输出值。𝛾的值为0.9。
在对100个小批次的Q网络进行训练结束时,进行了最后的测试阶段。车杆被初始化为15个不同的起始状态,在沿轨道的三个不同位置,从-2到2米,和5个不同的角度,从−180∘到180∘,Q网络被允许使用𝜖=0控制系统2000步。在这15×2000 = 30000步,或约33.3模拟分钟的强化值的平均值,以测试训练的Q网络的最终性能。
对于每个网络的大小和预训练步数,实验重复100次。图6所示的结果是在这100次测试中平均收到的强化的平均值,有90%的置信区间。在最终的评估中,极点初始化为零点,指向15个初始状态中只有3个,因此不能得到1的平均强化。
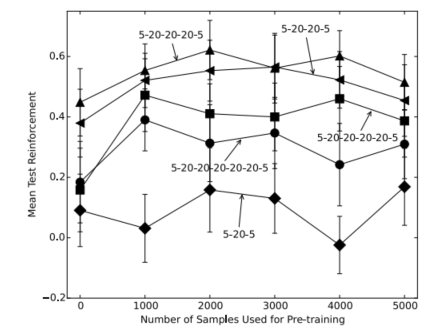
图6。用不同数量的预训练样本进行预训练的Q网络在测试阶段接收到的平均强化值。
对于预先训练2000个样本的5-20-20-20-5网络,最佳结果约为0.6,相当于约2.2分钟。比较没有预训练(0个样本)和预训练1000个样本的改进最大。对于有两层或三个隐藏层的网络,由于预训练的改善从平均强化约为0.4到0.6。对于有4层或5层隐藏层的网络,平均强化程度从约0.2提高到0.4。对于最小的网络,5- 20-5,与预训练之间的性能差异尚不清楚。5-20-5网络可以通过额外的训练获得更好的性能。
注意,即使是最大的网络5-20202020205,这里也没有采用无监督的方式对初始隐藏层进行预训练的典型深度学习方法。SCG算法似乎在将状态预测误差和Q值误差传播到早期层方面足够有效,因此不需要这种预训练。
图7显示了在预先训练了1000个样本的5-20-20-20-5网络的一个测试阶段中,推车极系统的行为和选择的贪婪行为。在此阶段,推车靠近左侧启动,杆处于向上位置(0∘)。选择的动作是将推车推向轨道的中心,在杆通过底部摆动几次后,杆被摆动到它保持的平衡位置。
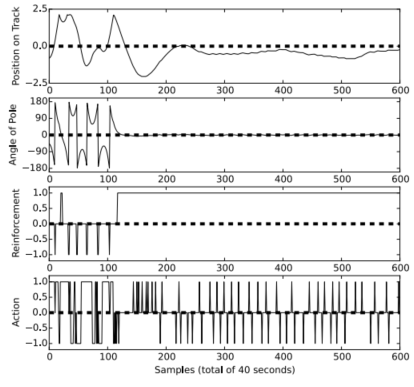
图7。其中一个测试运行,从𝑥=−2和𝜃=0开始,使用𝜖=0。积极动作,首先向右推(第四张图),将小车导向轨道中心(第一个图),但推杆通过底部摆动(第二张图)。然后,选择一些动作,将杆子在底部来回摆动五次,直到它成功地摆动到0度,在剩下的测试过程中保持平衡。马车被带回轨道的中心,它仍然保留。当极点穿过底部时,接收到的钢筋值(第四张图)为负值,当极点接近顶部时为正值。
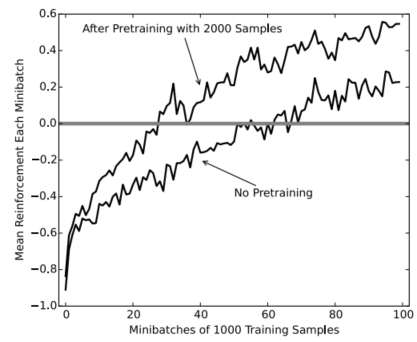
图8。在Q训练时的平均强化值。
图8显示了5- 20-20-20-5 Q网络在训练期间接收到的强化值,平均超过1000个样本的小批次,平均超过50次运行。对2000个样本进行预训练后,最终的平均强化值接近0.6,而未进行预训练时,最终的平均强化值达到0.3左右。当钢筋超过零时,极杆接近平衡位置的频率比它接近底部位置的频率更高。通过预训练,这发生在大约24.4个模拟分钟后(24.4≈22个小批×1000个样品/小批÷15个样品/秒÷60秒/分钟)。在没有预先训练的情况下,零强化直到大约67分钟(67≈60小批次×1000样本/小批÷15样本/秒÷60秒/分钟)。
DISCUSSION
在现实的环境中,应该考虑在总训练时间中进行预训练所需的额外样本。下面的简单实验研究了一个简单的马尔可夫决策问题(MDP),该问题有两个状态,状态0和状态1,以及两个动作,动作0和动作1。操作1会导致状态的更改,而操作0不会。因此,下一个状态函数是状态和动作输入的排他性或函数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vK8iRWyt-1678080358070)(../AppData/Roaming/Typora/typora-user-images/image-20230306093204835.png)]](https://img-blog.csdnimg.cn/4ce783c4fb8d4dad996fda1ac18d385c.png)
状态、行动和强化的样本总数是固定的。只有用于预训练的部分不同;使用0.2个样本进行预训练,只剩下0.8个样本进行强化学习来解决强化优化问题。图9显示了在训练中收到的平均强化和在最后几次试验中收到的平均强化的结果。这个实验重复了100次。在图的左端,对于用于预训练的0个样本,所有样本都用于强化学习,平均强化量约为0.5。回想一下,强化值分别是0和1,所以最大值是1。用于训练前的样本峰值约为0.3,用于强化学习的样本约为0.7。随着更多的样本用于预训练,而用于强化学习,性能会下降。结果表明,对于该问题,在样本交互数量固定的情况下,神经网络RL代理在使用剩余样本解决RL问题之前,通过使用部分样本进行预训练来预测状态动态,从而获得更好的性能。
CONCLUSION
最近,深度学习在一些分类问题上取得的成功表明,深度学习可能会提高强化学习算法的效率。一些出版物已经展示了如何以深度学习社区中典型的无监督的方式对神经网络的早期层进行预训练,可以为强化学习[1],[2]带来好处。
本文演示了一种不同的强化学习的预训练方法。首先训练一个神经网络,根据当前的状态和动作来预测状态变量的变化。然后进一步训练具有预先训练的隐层权值的同一神经网络,以逼近Q值来预测未来强化的总和,而忽略状态变化的输出变量。简单动态系统的实验,包括车杆系统的摆动问题表明,以这种方式预训练确实减少了强化学习所需的样本数量。由于预训练阶段产生了一个要控制系统的预测模型,使用它来生成假设样本是一件简单的事情,就像Sutton的DYNA框架[5]一样。由于两次使用学习模型来生成假设样本和提供初始隐藏层,所需的真实样本数量的减少可能是相加的。
随着状态和动作空间的动态和大小的复杂性的增加,预训练对预测状态变化的优势应该会增加。为了验证这一点,我们目前正在测试我们的方法来控制一个模拟的,多节段的章鱼手臂的问题。困难在于存在大量的连续值状态变量和动作变量。这是RL基准问题之一[18],但基准问题是一种简化的形式,其中允许的操作来自一个小的离散集。我们假设,通过预训练,可以实现全章鱼手臂问题的实际解决方案。
第二个需要研究的范式是同时学习对状态变化和未来强化的预测。对于强化值很少的任务,许多步骤都没有任何关于如何调整网络权值的信息。然而,每个步骤都提供了新的状态信息,通过可以据此对网络进行调整。如果发现共同或相似的特征对学习状态动态和Q值有用,那么同时学习两者的优势将是明显的。















 2045
2045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









