







图1对提出的语义图卷积的说明。(a) 3 × 3 3\times 3 3×3 的CNNs卷积核(用绿色高亮) 为核中的每个点学习了一个不同的转换矩阵 w i w_i wi。我们通过学习每个位置的加权向量 a i a_i ai 和共享的变换矩阵 W W W来对其进行近似。(b)传统的GCNs只学习所有节点的共享转换矩阵 w 0 w_0 w0。(c)近似公式(a) 可以直接推广到(b):我们为图中的每个节点增加一个额外的可学习权值。(d)我们进一步扩展(c),以了解每个节点的通道加权向量 a i a_i ai。将它们与传统GCNs中的香草变换矩阵 W W W 组合后,我们可以获得图的新内核运算,该运算具有与CNN相当的学习能力。 学习的权重向量显示了图中隐含的相邻节点的局部语义关系。

1 普通semgcn
1.1公式描述
在论文中对于semgcn的介绍作者画了上面这张图,然后使用了公式进一步说明:
- 对于图(c)
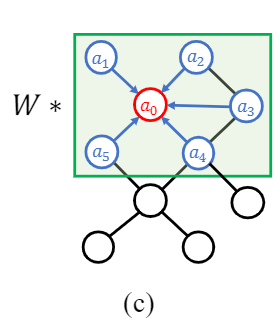
为此,我们提出了语义图卷积(SemGConv),其中我们在传统图卷积中添加了一个可学习的权重矩阵 M ∈ R K × K M∈\R^{K×K} M∈RK×K。 然后Eq.1转换为:
X l + 1 = σ ( W X ( l ) ρ i ( M ⊙ A ) ) , (2) X^{l+1} = \sigma{(WX^{(l)} \rho_i(M\odot A))},\tag{2} Xl+1=σ(WX(l)ρi(M⊙A)),(2)
其中 ρ i ρ_i ρi 是Softmax非线性,它对节点 i i i 的所有选择上的输入矩阵进行归一化 ; ⊙ \odot ⊙ 是一个元素运算,如果 a i j = 1 a_{ij} = 1 aij=1 则返回 m i j m_{ij} mij,或是一个大负数在 ρ i ρ_i ρi的指数运算之后趋近于0; A A A用作掩码,强制对图中的节点 i i i进行计算,我们仅计算其相邻节点 j ∈ N ( i ) j∈N(i) j∈N(i)的权重。
通过阅读代码,我们可以知道每个符号的维度数来进一步理解公式:
- X ( l ) X^{(l)} X(l)是第 l l l层网络的输入数据input,根据论文中画网络层时候的图标或者根据代码可以知道它是一个 B ∗ 16 ∗ 2 B*16*2 B∗16∗2的矩阵, B B B表示批处理大小batchsize。(不过经过第一个semgcn层后,输出变成了128,所以再往后以此作为输入的semgcn的输入就变成了 B ∗ 16 ∗ 128 B*16*128 B∗16∗128)
- W W W是一个转换矩阵,可以先把 W W W看成一个 2 ∗ 128 2*128 2∗128的矩阵
- M ∈ R K × K M∈\R^{K×K} M∈RK×K : M M M 是一个 16 × 16 16\times 16 16×16的矩阵
- A A A 是图的经过处理后的邻接矩阵(拉普拉斯矩阵),节点 i i i, j j j 有边则 a i j = 1 a_{ij}=1 aij=1。且对角线为1,也就是 a i i = 1 a_{ii} =1 aii=1,因为自己节点的数据也是一个可以利用的训练数据。
- ⊙ \odot ⊙ 是一个元素运算:也就是如果 A A A矩阵中元素为1的位置被 m i j m_{ij} mij替换,不为1的位置被一个大负数替换(代码中的大负数为-9e15)
- σ \sigma σ 和 ρ i ρ_i ρi,作者已经解释了为Relu激活函数和softmax非线性变换归一化
所以对于第一个Semgcn层(不同的层维数有差异,但原理相同),公式中的维度变化(不考虑batchsize维度),在代码中的实现顺序和公式有所不同,进行调整后可以写成下面这样:
X
l
+
1
⏟
16*128
=
σ
(
ρ
i
(
M
⏟
16*16
⊙
A
⏟
16*16
)
X
l
⏟
16*2
W
⏟
2*128
)
\underbrace{X^{l+1}}_{\text{16*128}} = \sigma{(\rho_i(\underbrace{M}_{\text{16*16}}\odot \underbrace{A}_{\text{16*16}})\underbrace{X^{l}}_{\text{16*{2}}}\underbrace{W}_{\text{2*128}})}
16*128
Xl+1=σ(ρi(16*16
M⊙16*16
A)16*2
Xl2*128
W)
花括号下的数字表示矩阵的大小。首先是输入的16个关节点的2维坐标
X
X
X,然后和转换矩阵
W
W
W相乘变成
16
∗
128
16*128
16∗128的矩阵假设这个矩阵是
H
H
H。然后是权重矩阵
M
M
M和处理后的邻接矩阵
A
A
A进行元素运算,运算后仍然是一个
16
∗
16
16*16
16∗16的矩阵,这个矩阵再和
16
∗
128
16*128
16∗128的矩阵
H
H
H进行运算,得到输出
16
∗
128
16*128
16∗128的矩阵
X
X
X。
在实际实现中,W并不是一个整体,它被拆成两部分:一部分W[0]用于对节点本身进行变换,另一部分用于对邻接节点进行变换。在论文的附录中是这样描述的:
一些先前的方法[64,67]提出利用图卷积中的两个不同的转换矩阵。 具体来说,当将图卷积滤波器应用于图中的结点时,使用一个矩阵 W 0 W_0 W0来变换结点的表示,而为其所有邻居学习另一个矩阵 W 1 W_1 W1。 我们重写Eq.1为:
X ( l + 1 ) = σ ( I ⊗ W 0 X ( l ) A ~ + ( 1 − I ) ⊗ W 1 X ( l ) A ~ ) , (9) X^{(l+1)} = \sigma{(I\otimes W_0X^{(l)} \tilde{A} + (1 - I) \otimes W_1 X ^{(l)} \tilde{A})}, \tag{9} X(l+1)=σ(I⊗W0X(l)A~+(1−I)⊗W1X(l)A~),(9)
⊗ \otimes ⊗ 表示逐元素相乘, I I I是单位矩阵。 我们还实现了由Eq.2和3定义的SemGConv以类似的方式。
- I I I是对角线全为1的单位矩阵, ( 1 − I ) (1-I) (1−I)就得到了除了对角线其余全为1的矩阵
- W[0]和W[1]都是一个 D ( l ) ∗ 128 D^{(l)}*128 D(l)∗128的矩阵,和上面那个简单公式的 W W W含义一样,根据网络层的不同可以是 16 ∗ 128 16*128 16∗128或者 128 ∗ 128 128*128 128∗128的矩阵
1.2代码
# 语义图卷积层
class SemGraphConv(nn.Module):
"""
Semantic graph convolution layer
"""
# 构造函数,输入特征数=2,输出特征数=128,邻接矩阵adj=16*16
def __init__(self, in_features, out_features, adj, bias=True):
super(SemGraphConv, self).__init__()
self.in_features = in_features # 输入特征数=2
self.out_features = out_features # 输出特征数=128
# 转换矩阵W = 2 * in * out = 2 * 2 * 128 / 2*128*128
self.W = nn.Parameter(torch.zeros(size=(2, in_features, out_features), dtype=torch.float))
nn.init.xavier_uniform_(self.W.data, gain=1.414) # W 矩阵初始化,使用均匀分布
self.adj = adj
self.m = (self.adj > 0) # 权重矩阵M = 16 * 16,邻边设置为true
# e 矩阵,另一种形式的mij
# m.nonzero(): 返回m矩阵中非零元素的索引 = 非零元素的个数z*维度(2)
# e = 1 * z
self.e = nn.Parameter(torch.zeros(1, len(self.m.nonzero()), dtype=torch.float))
nn.init.constant_(self.e.data, 1) # e矩阵全部填充为1
if bias:
self.bias = nn.Parameter(torch.zeros(out_features, dtype=torch.float))
stdv = 1. / math.sqrt(self.W.size(2))
self.bias.data.uniform_(-stdv, stdv)
else:
self.register_parameter('bias', None)
def forward(self, input):
# input = 16*2 / 16*128
h0 = torch.matmul(input, self.W[0]) # W[0]表示节点的变换 = (16 *2) * (2 * 128) = 16*128
h1 = torch.matmul(input, self.W[1]) # W[1]表示节点所有邻居的变换 = (16*2) * (2 * 128) = 16*128
# 生成一个与adj形状相同的全1张量,然后与-9e15相乘
adj = -9e15 * torch.ones_like(self.adj).to(input.device)
# 邻接矩阵中与节点邻接的点 = eij, 那么不与节点相邻的点就=-9e15
adj[self.m] = self.e # 元素运算 ⊙
adj = F.softmax(adj, dim=1) # 按行使用softmax进行归一化
# 生成一个有邻接矩阵行数(adj.size(0))的方阵,矩阵对角线全1,其余部分全0的二维矩阵
# 即公式中的I矩阵
M = torch.eye(adj.size(0), dtype=torch.float).to(input.device)
# 邻接矩阵adj*单位矩阵M * W[0] + A*(1-M)*W[1]
output = torch.matmul(adj * M, h0) + torch.matmul(adj * (1 - M), h1)
if self.bias is not None:
return output + self.bias.view(1, 1, -1)
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
带有通道级联的semgcn
对于图(d):
如图1(d)所示,我们可以进一步扩展Eq. 2,通过学习一组 M d ∈ R K × K M_d\in \R^{K\times K} Md∈RK×K,从而对输出节点特征的每个通道d应用不同的加权矩阵:
X ( l + 1 ) = ∣ ∣ d = 1 D l + 1 σ ( w ⃗ d X ( l ) ρ i ( M d ⊙ A ) ) , (3) X^{(l+1)} = \mathop{||}\limits_{d=1}^{D_{l+1}}\sigma{(\vec{w}_dX^{(l)} \rho_i(M_d\odot A))},\tag{3} X(l+1)=d=1∣∣Dl+1σ(wdX(l)ρi(Md⊙A)),(3)
其中 ∣ ∣ || ∣∣表示通道级联, w ⃗ d \vec{w}_d wd是变换矩阵 W W W的第d行。
通过阅读代码,对每个符号进行解释。
在代码中其实对矩阵相乘的顺序进行了变换,以及为了提高效率,有些操作合并到一个矩阵进行运算。
- 论文中所说的通道 d d d,其实是作者所说的输出通道也就是输出的128维数通道中的一条数据
- 变换矩阵 W W W 经过变换后可以看作是一个 128 ∗ 2 128*2 128∗2 的矩阵,它的一行可以看作一个长度为2的向量 w ⃗ d \vec{w}_d wd,也就是一个 1 ∗ 2 1*2 1∗2 的矩阵
- X ( l ) X^{(l)} X(l) 经过变换后其实是一个 2 ∗ 16 2*16 2∗16的矩阵
-
M
d
∈
R
K
×
K
M_d\in \R^{K\times K}
Md∈RK×K 可以看作一个
16
∗
16
16*16
16∗16 的矩阵,然后对于每一个通道都有一个
M
d
M_d
Md,所以
M
M
M是一个
128
∗
16
∗
16
128*16*16
128∗16∗16的矩阵

所以公式的含义是:
一个
1
∗
2
1*2
1∗2的矩阵
w
⃗
d
\vec{w}_d
wd和
2
∗
16
2*16
2∗16的矩阵
X
X
X相乘得到一个
1
∗
16
1*16
1∗16的矩阵,一个通道的
M
d
M_d
Md和
A
A
A进行元素运算后得到一个
16
∗
16
16*16
16∗16的矩阵,这个矩阵和之前的
1
∗
16
1*16
1∗16的矩阵相乘得到一个
1
∗
16
1*16
1∗16的矩阵。然后上述过程重复
D
(
l
)
D^{(l)}
D(l)次,也就是128次后将它们连接起来就是一个
128
∗
16
128*16
128∗16的矩阵,代码中进行了一些转换后输出一个
16
∗
128
16*128
16∗128的矩阵。
在实际的代码中,并没有重复 D ( l ) D^{(l)} D(l)次这个操作,通过扩充维数和通道维数的变换在一次计算中进行了通道的级联。
代码
class SemCHGraphConv(nn.Module):
"""
Semantic channel-wise graph convolution layer
"""
def __init__(self, in_features, out_features, adj, bias=True):
super(SemCHGraphConv, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.W = nn.Parameter(torch.zeros(size=(2, in_features, out_features), dtype=torch.float))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
# adj在第0维增加一个维度 16*16 --> 1*16*16,然后在0维重复out_features次,2维1次,3维1次-->out_features*16*16
self.adj = adj.unsqueeze(0).repeat(out_features, 1, 1)
self.m = (self.adj > 0)
self.e = nn.Parameter(torch.zeros(out_features, len(self.m[0].nonzero()), dtype=torch.float))
nn.init.constant_(self.e.data, 1)
if bias:
self.bias = nn.Parameter(torch.zeros(out_features, dtype=torch.float))
stdv = 1. / math.sqrt(self.W.size(1))
self.bias.data.uniform_(-stdv, stdv)
else:
self.register_parameter('bias', None)
def forward(self, input):
# (B*16*2)*(2*128) -->(B*16*128) -->B*1*16*128-->B*128*16*1
h0 = torch.matmul(input, self.W[0]).unsqueeze(1).transpose(1, 3) # B * C * J * 1
h1 = torch.matmul(input, self.W[1]).unsqueeze(1).transpose(1, 3) # B * C * J * 1
adj = -9e15 * torch.ones_like(self.adj).to(input.device) # C * J * J = 128*16*16
adj[self.m] = self.e.view(-1)
adj = F.softmax(adj, dim=2)
E = torch.eye(adj.size(1), dtype=torch.float).to(input.device)
E = E.unsqueeze(0).repeat(self.out_features, 1, 1) # C * J * J
output = torch.matmul(adj * E, h0) + torch.matmul(adj * (1 - E), h1)
output = output.transpose(1, 3).squeeze(1)
if self.bias is not None:
return output + self.bias.view(1, 1, -1)
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
注意unsqueeze和transpose操作















 992
992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









