






RT1复现(三)
这部分的工作是对language部分进行特征提取,使用rt1文章的Universal Sentence Encoder的模型进行数据预处理
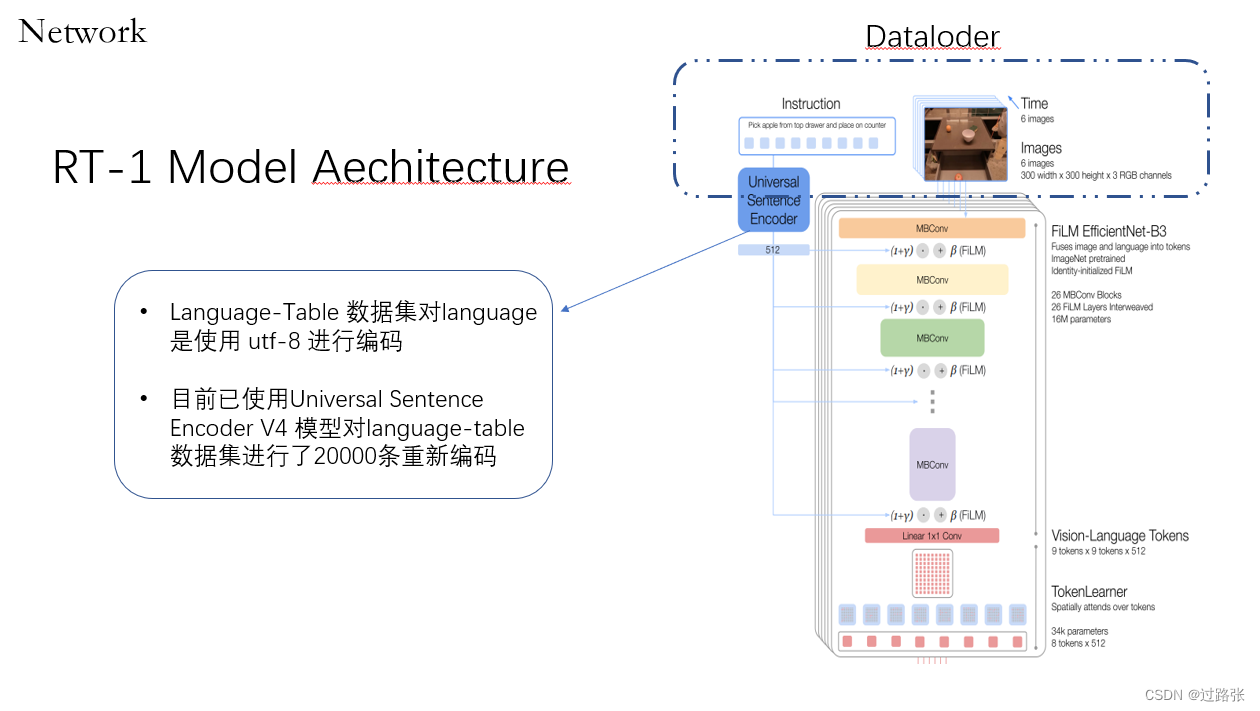 先将language_table_sim-train.tfrecor-0000格式变成episode_0.npy格式,可以不用划分验证集和测试集
先将language_table_sim-train.tfrecor-0000格式变成episode_0.npy格式,可以不用划分验证集和测试集
rlds_np_save.py
dataset_episode_num = 20200
builder = tfds.builder_from_directories(dataset_dirs)
ds = builder.as_dataset(
split=f'train[{0}:{dataset_episode_num}]',
decoders={"steps": {"observation": {"rgb": tfds.decode.SkipDecoding()}}},
shuffle_files=False
)
from tqdm import tqdm
import os
# 将原本的数据存为np文件
def create_episode(path,raw_episode):
episode = []
for step in raw_episode[rlds.STEPS]:
observation = step[rlds.OBSERVATION]
observation_keys = observation.keys()
step_keys = list(step.keys())
step_keys.remove(rlds.OBSERVATION)
step_dict = {}
for k in step_keys:
step_dict[k] = step[k].numpy()
for k in observation_keys:
step_dict[k] = observation[k].numpy()
episode.append(step_dict)
np.save(path, episode)
# 设置数据集中的episode数量
NUM_TRAIN = 20000
NUM_VAL = 100
NUM_TEST = 100
# 分别创建出对应的数据集
print("Generating train examples...")
os.makedirs('/mnt/ve_share2/zy/np_dataset/data/train', exist_ok=True)
cnt = 0
for element in tqdm(ds.take(NUM_TRAIN)):
create_episode(f'/mnt/ve_share2/zy/np_dataset/data/train/episode_{cnt}.npy',element)
cnt = cnt + 1
print("Generating val examples...")
os.makedirs('/mnt/ve_share2/zy/np_dataset/data/val', exist_ok=True)
cnt = 0
for element in tqdm(ds.skip(NUM_TRAIN).take(NUM_VAL)):
create_episode(f'/mnt/ve_share2/zy/np_dataset/data/val/episode_{cnt}.npy', element)
cnt = cnt + 1
print("Generating test examples...")
os.makedirs('/mnt/ve_share2/zy/np_dataset/data/test', exist_ok=True)
cnt = 0
for element in tqdm(ds.skip(NUM_TRAIN + NUM_VAL).take(NUM_TEST)):
create_episode(f'/mnt/ve_share2/zy/np_dataset/data/test/episode_{cnt}.npy', element)
cnt = cnt + 1
得到一下文件:
data
├── train
│ ├── episode_0
│ ├── episode_1
│ ├── …
├── val
│ ├── episode_100
│ ├── episode_101
│ ├── …
├── test
│ ├── episode_201
│ ├── episode_202
│ ├── …
然后将data移动到和language_table_use_dataset_builder.py 同目录下:
language_table_use
├── data
├── language_table_use_dataset_builder.py
├── …
使用一下命令
# create the environment
conda env create -f environment_ubuntu.yml
# activate the conda environment
conda activate rlds_env
# tfds build
tfds build --data_dir 'Fill in the data final storage path here'
language_table_use_dataset_builder.py
from typing import Iterator, Tuple, Any
import glob
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
class LanguageTableUse(tfds.core.GeneratorBasedBuilder):
"""DatasetBuilder for example dataset."""
VERSION = tfds.core.Version('1.0.0')
RELEASE_NOTES = {
'1.0.0': 'Initial release.',
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._embed = hub.load("/mnt/ve_share2/zy/Universal_Sentence_Encoder")
def _info(self) -> tfds.core.DatasetInfo:
"""Dataset metadata (homepage, citation,...)."""
return self.dataset_info_from_configs(
features=tfds.features.FeaturesDict({
'steps': tfds.features.Dataset({
'observation': tfds.features.FeaturesDict({
'rgb': tfds.features.Image(
shape=(360, 640, 3),
dtype=np.uint8,
doc='RGB observation.',
),
'effector_target_translation': tfds.features.Tensor(
shape=(2,),
dtype=np.float32,
doc='robot effector target,like x,y in the 2-D dimension',
),
'effector_translation': tfds.features.Tensor(
shape=(2,),
dtype=np.float32,
doc='robot effector state,like x,y in the 2-D dimension',
),
'instruction': tfds.features.Tensor(
shape=(512,),
dtype=np.float32,
doc='universial sentence embedding instruction',
),
}),
'action': tfds.features.Tensor(
shape=(2,),
dtype=np.float32,
doc='Robot action',
),
'reward': tfds.features.Scalar(
dtype=np.float32,
doc='Reward if provided, 1 on final step for demos.'
),
'is_first': tfds.features.Scalar(
dtype=np.bool_,
doc='True on first step of the episode.'
),
'is_last': tfds.features.Scalar(
dtype=np.bool_,
doc='True on last step of the episode.'
),
'is_terminal': tfds.features.Scalar(
dtype=np.bool_,
doc='True on last step of the episode if it is a terminal step, True for demos.'
),
}),
'episode_metadata': tfds.features.FeaturesDict({
'file_path': tfds.features.Text(
doc='Path to the original data file.'
),
}),
}))
def _split_generators(self, dl_manager: tfds.download.DownloadManager):
"""Define data splits."""
return {
'train': self._generate_examples(path='data/train/episode_*.npy'),
'val': self._generate_examples(path='data/val/episode_*.npy'),
'test': self._generate_examples(path='data/test/episode_*.npy'),
}
def _generate_examples(self, path) -> Iterator[Tuple[str, Any]]:
"""Generator of examples for each split."""
def _parse_example(episode_path):
# load raw data --> this should change for your dataset
with open(episode_path,'rb') as file:
data = np.load(file, allow_pickle=True) # this is a list of dicts in our case
def decode_inst(inst):
return bytes(inst[np.where(inst != 0)].tolist()).decode("utf-8")
# assemble episode --> here we're assuming demos so we set reward to 1 at the end
episode = []
for i, step in enumerate(data):
# compute Kona language embedding
language_embedding = self._embed([decode_inst(np.array(step['instruction']))])[0].numpy()
episode.append({
'observation': {
'rgb': step['rgb'],
'effector_target_translation': step['effector_target_translation'],
'effector_translation': step['effector_translation'],
'instruction': language_embedding,
},
'action': step['action'],
'reward': step['reward'],
'is_first': step['is_first'],
'is_last': step['is_last'],
'is_terminal': step['is_terminal'],
})
# create output data sample
sample = {
'steps': episode,
'episode_metadata': {
'file_path': episode_path
}
}
# if you want to skip an example for whatever reason, simply return None
return episode_path, sample
# create list of all examples
episode_paths = glob.glob(path)
# for smallish datasets, use single-thread parsing
for sample in episode_paths:
yield _parse_example(sample)
# for large datasets use beam to parallelize data parsing (this will have initialization overhead)
# beam = tfds.core.lazy_imports.apache_beam
# return (
# beam.Create(episode_paths)
# | beam.Map(_parse_example)
# )
environment_ubuntu.yml
name: rlds_env
channels:
- conda-forge
dependencies:
- _libgcc_mutex=0.1=conda_forge
- _openmp_mutex=4.5=2_gnu
- ca-certificates=2023.7.22=hbcca054_0
- ld_impl_linux-64=2.40=h41732ed_0
- libffi=3.3=h58526e2_2
- libgcc-ng=13.1.0=he5830b7_0
- libgomp=13.1.0=he5830b7_0
- libsqlite=3.42.0=h2797004_0
- libstdcxx-ng=13.1.0=hfd8a6a1_0
- libzlib=1.2.13=hd590300_5
- ncurses=6.4=hcb278e6_0
- openssl=1.1.1u=hd590300_0
- pip=23.2.1=pyhd8ed1ab_0
- python=3.9.0=hffdb5ce_5_cpython
- readline=8.2=h8228510_1
- setuptools=68.0.0=pyhd8ed1ab_0
- sqlite=3.42.0=h2c6b66d_0
- tk=8.6.12=h27826a3_0
- tzdata=2023c=h71feb2d_0
- wheel=0.41.0=pyhd8ed1ab_0
- xz=5.2.6=h166bdaf_0
- zlib=1.2.13=hd590300_5
- pip:
- absl-py==1.4.0
- anyio==3.7.1
- apache-beam==2.49.0
- appdirs==1.4.4
- array-record==0.4.0
- astunparse==1.6.3
- cachetools==5.3.1
- certifi==2023.7.22
- charset-normalizer==3.2.0
- click==8.1.6
- cloudpickle==2.2.1
- contourpy==1.1.0
- crcmod==1.7
- cycler==0.11.0
- dill==0.3.1.1
- dm-tree==0.1.8
- dnspython==2.4.0
- docker-pycreds==0.4.0
- docopt==0.6.2
- etils==1.3.0
- exceptiongroup==1.1.2
- fastavro==1.8.2
- fasteners==0.18
- flatbuffers==23.5.26
- fonttools==4.41.1
- gast==0.4.0
- gitdb==4.0.10
- gitpython==3.1.32
- google-auth==2.22.0
- google-auth-oauthlib==1.0.0
- google-pasta==0.2.0
- googleapis-common-protos==1.59.1
- grpcio==1.56.2
- h11==0.14.0
- h5py==3.9.0
- hdfs==2.7.0
- httpcore==0.17.3
- httplib2==0.22.0
- idna==3.4
- importlib-metadata==6.8.0
- importlib-resources==6.0.0
- keras==2.13.1
- kiwisolver==1.4.4
- libclang==16.0.6
- markdown==3.4.3
- markupsafe==2.1.3
- matplotlib==3.7.2
- numpy==1.24.3
- oauthlib==3.2.2
- objsize==0.6.1
- opt-einsum==3.3.0
- orjson==3.9.2
- packaging==23.1
- pathtools==0.1.2
- pillow==10.0.0
- plotly==5.15.0
- promise==2.3
- proto-plus==1.22.3
- protobuf==4.23.4
- psutil==5.9.5
- pyarrow==11.0.0
- pyasn1==0.5.0
- pyasn1-modules==0.3.0
- pydot==1.4.2
- pymongo==4.4.1
- pyparsing==3.0.9
- python-dateutil==2.8.2
- pytz==2023.3
- pyyaml==6.0.1
- regex==2023.6.3
- requests==2.31.0
- requests-oauthlib==1.3.1
- rsa==4.9
- sentry-sdk==1.28.1
- setproctitle==1.3.2
- six==1.16.0
- smmap==5.0.0
- sniffio==1.3.0
- tenacity==8.2.2
- tensorboard==2.13.0
- tensorboard-data-server==0.7.1
- tensorflow==2.13.0
- tensorflow-datasets==4.9.2
- tensorflow-estimator==2.13.0
- tensorflow-hub==0.14.0
- tensorflow-io-gcs-filesystem==0.32.0
- tensorflow-metadata==1.13.1
- termcolor==2.3.0
- toml==0.10.2
- tqdm==4.65.0
- typing-extensions==4.5.0
- urllib3==1.26.16
- wandb==0.15.6
- werkzeug==2.3.6
- wrapt==1.15.0
- zipp==3.16.2
- zstandard==0.21.0
















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











