






框架
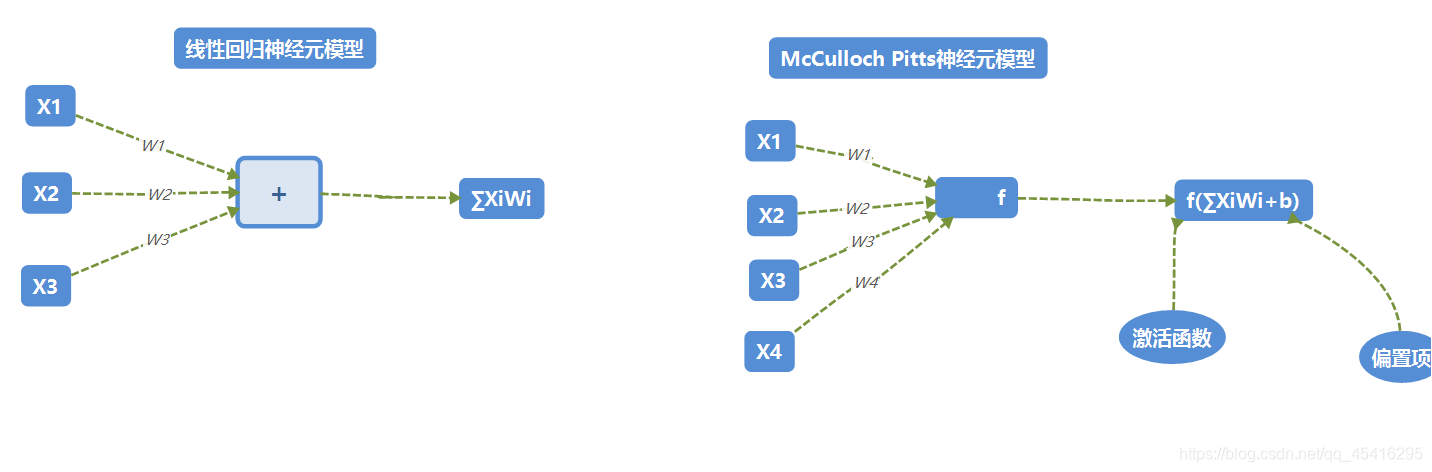
激活函数
目的:加入非线性元素,解决线性模型缺陷
- ReLu
- 函数表达式:
f ( x ) = m a x ( x , 0 ) = { 0 , x < = 0 x , x > = 0 f(x)=max(x,0)=\begin{cases} 0 ,x<=0\\ x,x>=0\\ \end{cases} f(x)=max(x,0)={0,x<=0x,x>=0 - 函数调用:
tf.nn.relu(features,name=None)一般ReLU函数, m a x ( f e a t u r e s , 0 ) max(features,0) max(features,0);tf.nn.relu6(features,name=None)阈值为6的ReLU函数, m i n ( m a x ( f e a t u r e s , 0 ) , 6 ) min(max(features,0),6) min(max(features,0),6);
-舍弃了全部负值,在信号响应上具有一定优势,很容易使得模型输出全为0无法训练。
- Sigmoid
- 函数表达式:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1 - 函数调用:
tf.nn.sigmoid(x,name=None)

- x x x趋近于无穷大, y y y值接近于1/-1,即为饱和。如果激活函数处于饱和态,意味着将数据的某些特性丢失。特别是当数据x>=6或x<=-6之后,数据变化不明显。较好效果是-3~3之间取值。
- Tanh
- 函数表达式:
-
t
a
n
h
(
x
)
=
2
s
i
g
m
o
i
d
(
2
x
)
−
1
tanh(x)=2sigmoid(2x)-1
tanh(x)=2sigmoid(2x)−1
f ( x ) = 1 − e − 2 x 1 + e − 2 x f(x)=\frac{1-e^{-2x}}{1+e^{-2x}} f(x)=1+e−2x1−e−2x - 函数调用:
tf.nn.tanh(x,name=None)
- 和 s i g m o i d sigmoid sigmoid函数一样,饱和问题较突出。
- SoftPlus函数
- 该函数更加平滑,计算量较大,会保留小于0的少量值。
- f ( x ) = l n ( 1 + e x ) f(x)=ln(1+e^x) f(x)=ln(1+ex)
- 函数调用
tf.nn.softplus(features,name=None)
5.从ReLu函数而来的变种函数- Noisy relus:为max的 x x x增加了一个高斯分布的噪声
- f ( x ) = m a x ( 0 , x + Y ) , Y ∈ N ( 0 , σ ( x ) ) f(x)=max(0,x+Y),Y\in N(0,\sigma(x)) f(x)=max(0,x+Y),Y∈N(0,σ(x))
- Leaky relus:在ReLU基础之上,保留部分负值, x x x为负之时,乘a(a<=1),它是一定比例的缩小数据。
- f ( x ) = m a x ( x , a x ) = { x , x > 0 a x , ( o t h e r w i s e ) (1) f(x)=max(x,ax)= \begin{cases} x,\quad x> 0\\ ax, \quad (otherwise) \end{cases} \tag{1} f(x)=max(x,ax)={x,x>0ax,(otherwise)(1)
- 组合函数调用:
tf.maximum(x,leak*x,name=name) - Elus: x x x小于0,复杂变换
- f ( x ) = { x , x > = 0 a ( e x − 1 ) , ( o t h e r w i s e ) (1) f(x)= \begin{cases} x,\quad x>= 0\\ a(e^x-1), \quad (otherwise) \end{cases} \tag{1} f(x)={x,x>=0a(ex−1),(otherwise)(1)
- 函数调用:
tf.nn.elu(features,name=None)
- Swish函数
- f ( x ) = x ∗ s i g m o i d ( β x ) f(x)=x*sigmoid(\beta x) f(x)=x∗sigmoid(βx)
- β \beta β是 x x x的缩放参数,在使用BN算法的情况下,对 x x x的缩放值进行调整。
- 手动封装:
def Swish(x,beta=1): return x*tf.nn.sigmoid(x*beta)
NN复杂度
- 多用NN层数和NN参数的个数表示
- 层数:隐藏层层数+1个输出层
- 总参数:总W+总b
神经网络优化
- 损失函数(loss):预测值(y)与已知值(y_)的差距
- NN优化目标:loss最小
- 均方误差mse:
M
S
E
(
y
_
,
y
)
=
∑
i
=
1
n
(
y
−
y
_
)
2
n
MSE(y\_,y)=\frac{\sum_{i=1}^{n}(y-y\_)^2}{n}
MSE(y_,y)=n∑i=1n(y−y_)2
函数调用:loss_mse=tf.reduce_mean(tf.square(y_-y)) - 自定义(商品预测)
l o s s ( y _ , y ) = ∑ n f ( y _ , y ) loss(y\_,y)=\sum_nf(y\_,y) loss(y_,y)=n∑f(y_,y)
即: f ( y _ , y ) = { P R O F I T ∗ ( y _ − y ) , y < y _ , 损 失 利 润 C O S T ∗ ( y − y _ ) , y > y _ , 损 失 成 本 f(y\_,y)=\begin{cases} PROFIT*(y\_-y),y<y\_,损失利润\\ COST*(y-y\_),y>y\_,损失成本\\ \end{cases} f(y_,y)={PROFIT∗(y_−y),y<y_,损失利润COST∗(y−y_),y>y_,损失成本
函数调用:
# tf.where询问y,y_大小
loss=tf.reduce_sum(tf.where(tf.greater(y,y_),COST(y-y_),PROFIT(y_-y)))
- ce(交叉熵)
- 表征两个概率分布之间 的距离
H ( y _ , y ) = − ∑ y _ ∗ log y H(y\_,y)=-\sum{y\_*\log y} H(y_,y)=−∑y_∗logy - 函数调用:
ce=tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-12,1.0)))
引入:softmax()函数
- 当n分类的n个输出(y1,y2,…yn)通过softmax()函数,满足概率分布要求:
- ∀ x , P ( X = x ) ∈ [ 0 , 1 ] a n d ∑ x p ( X = x ) = 1 \forall x,P(X=x)\in[0,1]and \sum_xp(X=x)=1 ∀x,P(X=x)∈[0,1]andx∑p(X=x)=1
- s o f t m m a x ( y i ) = e y i ∑ j = 1 n e y i softmmax(y_i)=\frac{e^{y^i}}{\sum_{j=1}^{n}e^{y^i}} softmmax(yi)=∑j=1neyieyi
- 函数调用:
ce=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem=tf.reduce_mean(ce)
















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











