







 自编码器是一种无监督学习方法,包含编码器和解码器两部分,用于学习数据的隐层特征并重构原始输入。通过编码器将输入数据映射到低维隐层空间,然后用解码器从隐层空间重构数据。模型通过非线性函数如Sigmoid、ReLU或Tanh进行变换,并使用随机梯度下降优化参数,以最小化重构误差。然而,AE不能生成新数据,仅能重构已有数据。
自编码器是一种无监督学习方法,包含编码器和解码器两部分,用于学习数据的隐层特征并重构原始输入。通过编码器将输入数据映射到低维隐层空间,然后用解码器从隐层空间重构数据。模型通过非线性函数如Sigmoid、ReLU或Tanh进行变换,并使用随机梯度下降优化参数,以最小化重构误差。然而,AE不能生成新数据,仅能重构已有数据。
自编码器(AutoEncoder,AE)
结构图
原理
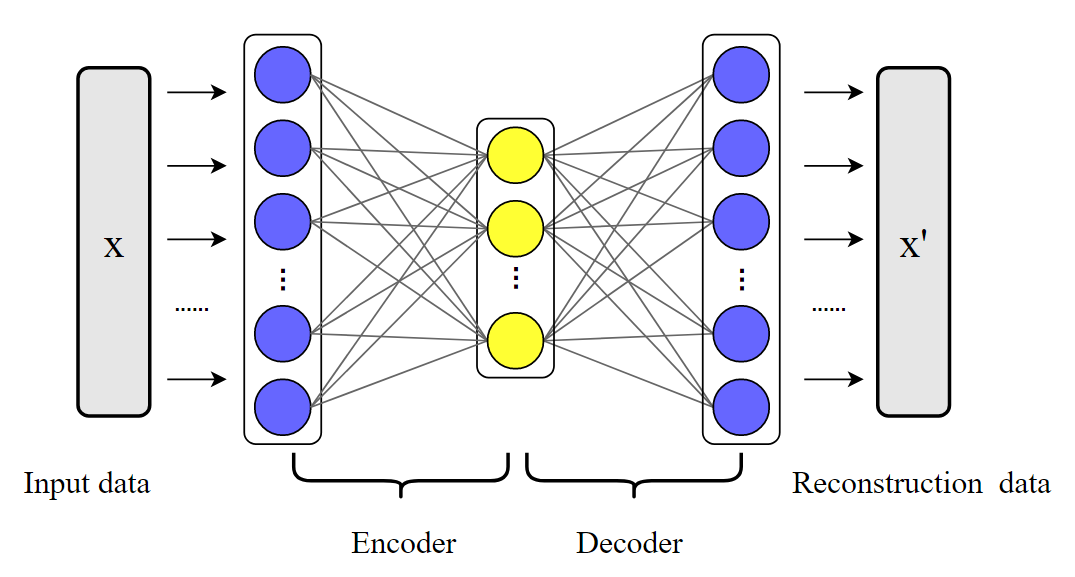
- AE结构包含两部分:编码器Encoder和解码器Decoder
- 原始数据X通过编码器,得到隐层变量Z,Z包含了原始数据X的一些特征
- 编码部分将原始数据X从数据空间Rn映射到隐层变量Z所在的隐层空间Rd
- 隐层变量Z,通过解码器,得到输出变量X’,即原始数据X的重构
- 解码部分将隐层变量Z从隐层空间Rd映射到输出变量X’所在的空间,即原始数据X所在的数据空间Rn
功能
- AE可以学习得到原始数据的隐层特征
- 如人脸可由如下特征表示:眼睛大小,鼻子高低,嘴唇厚度,胡子长度…
- 编码部分任务
- AE可以通过学习到的隐层特征,重构原始数据
- 如通过人脸的特征,重构得到该张人脸
- 解码部分任务
算法实现
- 原始数据到隐层特征
h = E n c o d e ( x ) = f e ( W e ⋅ x + b e ) h=Encode\left( x \right) =f_e\left( W_e\cdot x+b_e \right) h=Encode(x)=fe(We⋅x+be)
- 隐层特征到重构输出
x ~ = D e c o d e ( x ) = f d ( W d ⋅ h + b d ) \tilde{x}=Decode\left( x \right) =f_d\left( W_d\cdot h+b_d \right) x~=Decode(x)=fd(Wd⋅h+bd)
公式中的 f_e 和 f_d 函数是常用的非线性函数,如Sigmoid函数、ReLU函数、Tanh函数
- 整个模型需要得到最优参数组:
θ ( W e , b e , W d , b d ) \theta \left( W_e, b_e, W_d, b_d \right) θ(We,be,Wd,bd)
- 随机梯度下降算法寻找最优参数组
θ k + 1 ( W e , b e , W d , b d ) = θ k ( W e , b e , W d , b d ) − ∂ J ∂ θ J = 1 2 N ∑ i = 1 N ∥ x ~ i − x i ∥ 2 \theta _{k+1}\left( W_e, b_e, W_d, b_d \right) =\theta _k\left( W_e, b_e, W_d, b_d \right) -\frac{\partial J}{\partial \theta} \\ J=\frac{1}{2N}\sum_{i=1}^N{\left\| \tilde{x}_i-x_i \right\| ^2} θk+1(We,be,Wd,bd)=θk(We,be,Wd,bd)−∂θ∂JJ=2N1i=1∑N∥x~i−xi∥2
代码实现
待补充。。。
模型不足
- AE模型只能重构已有数据,不能生成数据
- 若通过人为给定隐层特征Z,则大概率不能重构目标输出,因为人为给定的Z不满足原始数据学习到的隐层变量Z所遵从的分布

















 9877
9877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









