









 本文介绍了如何使用自定义函数实现线性回归模型,并结合5折交叉验证评估其在预测房价方面的性能,通过生成随机数据集和计算R2评分来检验模型稳定性。
本文介绍了如何使用自定义函数实现线性回归模型,并结合5折交叉验证评估其在预测房价方面的性能,通过生成随机数据集和计算R2评分来检验模型稳定性。
交叉验证法作业
交叉验证法是一种用于评估机器学习模型在未知数据上表现的统计分析技术,通过对数据进行分组,然后在这些组上反复进行训练和验证过程,以确保模型评估的稳定性和准确性。最常见的交叉验证方法是k折交叉验证。
在k折交叉验证中,原始数据被分成k个子集。每个子集轮流作为验证数据集,其余的k-1个子集组合起来作为训练数据集,这个过程重复进行k次,每次都会产生一个模型评估分数,最终的模型性能是这k次评估分数的平均值。
编程题目
假设你有一组关于房价的数据,其中包含两个特征:房间数和面积,以及房价作为目标变量。你的任务是使用线性回归模型和5折交叉验证来评估模型的性能。(不使用python现有库和模块,自定义函数实现)
你需要完成以下步骤:
-
生成一个包含100个样本的数据集,其中房间数和面积是随机生成的,房间数范围为1到5,面积范围为20到100平方米。房价(目标变量)可以使用任意简单公式计算得出,例如房价
= 房间数 * 20 + 面积 * 2 + 随机噪声,其中随机噪声可以使用正态分布生成。 -
使用线性回归模型对数据进行拟合。
-
应用5折交叉验证来评估模型性能,并打印出每一轮的评分以及平均评分。
import numpy as np
# 生成数据集
rooms = np.random.randint(1, 6, 100) # 房间数
area = np.random.randint(20, 101, 100) # 面积
noise = np.random.randn(100) # 随机噪声
price = rooms * 20 + area * 2 + noise # 房价
# 将特征和目标变量组合成适合模型训练的格式
x = np.column_stack((rooms, area))
y = price
# 定义线性回归模型的训练函数
def linear_regression(x_train, y_train, lr, num_iters, batch_size):
n = len(x_train)
b = 0
w = np.zeros(2)
batch_num = int(np.ceil((n / batch_size)))
b_record = [b]
w_record = [w.copy()]
for iter in range(num_iters):
total_loss = 0
for i in range(batch_num):
batch_start = i * batch_size
batch_end = min((i + 1) * batch_size, n)
pred = np.dot(x_train[batch_start:batch_end], w) + b
loss = np.sum((pred - y_train[batch_start:batch_end]) ** 2) / 2 / batch_size
delta = pred - y_train[batch_start:batch_end] #计算梯度
w = w - lr * np.dot(x_train[batch_start:batch_end].T, delta) / batch_size #更新w
b = b - lr * np.sum(delta) / batch_size #更新b
b_record.append(b)
w_record.append(w.copy())
return w_record,b_record
# 定义评估函数
def evaluate(x, y, lr=0.01, num_iters=100, batch_size=20, n_splits=5):
scaled_x = (x - np.mean(x, axis=0, keepdims=True))/np.std(x, axis=0, keepdims=True) # 自变量标准化
centered_y = y - np.mean(y) # 因变量中心化处理
indices = np.arange(len(scaled_x))
np.random.shuffle(indices) # 随机打乱数据顺序
fold_size = len(scaled_x) // n_splits
scores = []
for i in range(n_splits):
# 划分训练集和验证集
val_indices = indices[i * fold_size: (i + 1) * fold_size]
train_indices = np.concatenate([indices[:i * fold_size], indices[(i + 1) * fold_size:]])
x_train, x_val = scaled_x[train_indices], scaled_x[val_indices]
y_train, y_val = centered_y[train_indices], centered_y[val_indices]
# 训练模型
w,b = linear_regression(x_train, y_train, lr, num_iters, batch_size)
# 在验证集上进行预测
y_pred = np.dot(x_val, w[-1]) + b[-1]
# 计算评分(拟合优度R2)
score = 1 - np.sum((y_pred - y_val) ** 2) / np.sum((y_val - np.mean(y_val)) ** 2)
scores.append(score)
# 输出每一轮的评分
print("5轮的评分(拟合优度R2):", scores)
# 输出平均评分
print("平均评分(拟合优度R2):", np.mean(scores))
# 评估函数
evaluate(x, y)
输出结果如下:
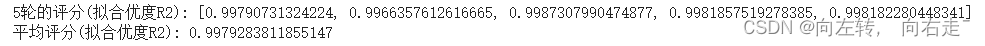

















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









