






文章链接:vis-www.cs.umass.edu/bcnn/docs/bcnn_iccv15.pdf
这是细粒度识别领域的一篇比较经典的论文。作者提出了一种针对细粒度识别任务的CNN架构,如下图所示。该网络结合了两个CNN的输出作为最终的特征向量,并进行分类。作者认为,由一个网络确定具有细粒度差异的部件位置,另一个网络确定该部件的样子(高层语义特征)。现在看来,当时的理由是站不住脚的。该网络实际上是一个提取图像高阶语义特征并用于分类的端到端网络,而非定位-分类网络。该网络架构在当时取得了sota的结果。作者对网络使用ImageNet数据集预训练后,在CUB-200-2011数据集微调,得到了80.9%的top1准确率。
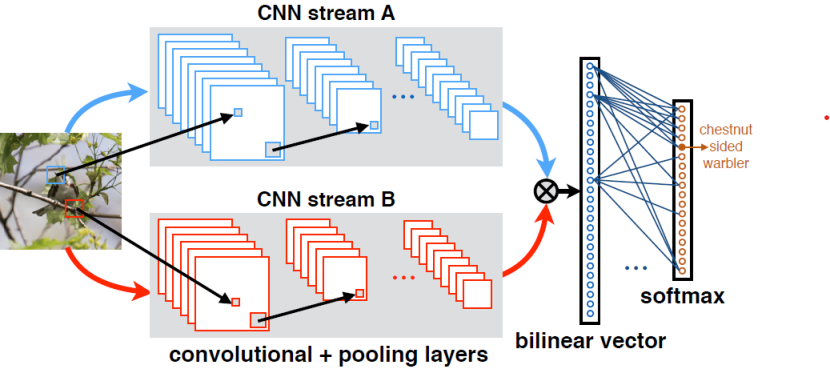
具体的网络架构中,作者将两组不同的CNN分别称为M-Net和D-Net。D-Net是比M-Net更深的网络。输入图像的大小为448x448。在网络的前向传播过程中,输入图像在经过卷积网络,sum-pooling,square-root和l2归一化后,D-Net的输出大小为28x28,M-Net的输出大小为27x27。为了方便之后的合并,作者舍去了D-Net的一行和一列。作者仅在使用细粒度数据集进行网络微调前,将最后一个softmax分类层加入网络中。
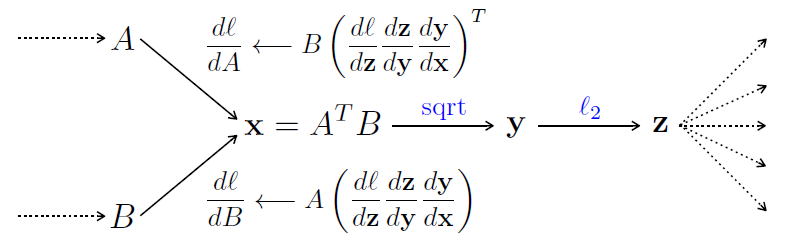
作者尝试使用两组M-Net的对称网络和M-Net+D-Net的不对称网络。在CUB-200-2011数据集上,两组M-Net得到72.5%的准确率,M-Net+D-Net的不对称网络则得到80.9%的准确率。此外,作者对比了不同的归一化方法的性能结果,具有很大的差异。在不使用边框信息的CUB-200-2011的训练结果上,加入平方根+l2归一化的准确率为75.1%,仅使用l2归一化时为71.7%,不进行归一化时为69.3%,具有巨大的性能差异,值得之后思考和实验尝试。
总而言之,Bilinear CNN第一次将双流卷积网络引入了图像分类领域,并在细粒度识别任务中取得了很好的效果。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









