






摘要
本文主要介绍CNN的架构设计,首先提出为什么使用CNN而不是用fully connected进行影像识别,通过对影像的观察提出三种简化参数的方法,用两种介绍方式(neuron version story和filter version story)来介绍CNN;最后介绍CNN的应用,比如下围棋。
一、CNN
CNN专门被用在影像上
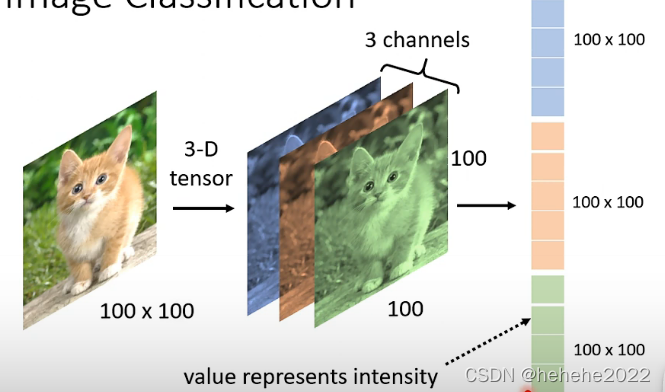
Image Classification
问题:怎么把一张影像当做模型的输入呢?
对于机器来说,一张图片就是一个3-D tensor(维度大于2的矩阵),分别是宽,高和3channels(代表RGB 三个颜色 )。把宽,高和3channels拿出来排成一排当做一个向量,如下图,我们只要能把一张图片变成一个向量就可以当成是network的输入。
fully connected network
如果把上面的向量当做network的输入,长度为100X100X3,我们会发现参数过多,考虑到影像的特性,我们并不需要fully connected;接下来我们对影像辨识问题影像本身特性的观察。
观察1:识别一张图片的类别并不需要将整张图片当做输入,只需要一部分当做输入,就可以侦测某些关键的pattern有无出现。根据这个观察我们来做第一个简化。
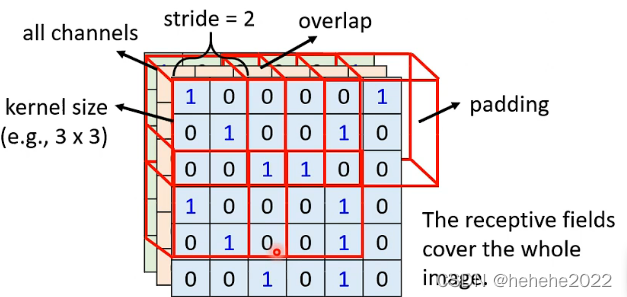
receptive field
在CNN中,会设定一个区域叫receptive field,每个neuron只关心自己的receptive field发生的事情,receptive field可以重叠,多个neuron可以有同一个receptive field。
receptive field可以任意设计, 最经典的设计方式如下:
1.会看所有的channels,所以我们在描述一个receptive field只讲kernel size(宽和高)就好了。receptive field之间移动的量叫做stride,当receptive field超出范围叫padding,可以补值。
共享参数
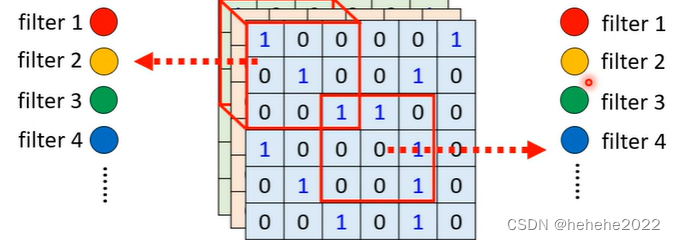
观察2:同样的pattern可能出现在图像的不同区域,一些neuron可以共享参数,即他们的weight完全相同,这是第二个简化。
常见的共享参数的方法:
每个receptive field有一组neurons。
颜色相同表示他们共享一组参数
fully connected layer的弹性最大;因为不需要看整张图片,只需要看一部分即可侦测出图片的pattern所以我们有了receptive field,由于只能看一个小范围,弹性变小;参数共享(parameter sharing)更进一步限制了弹性。receptive field加上parameter sharing就是convolutional layer(它的model bias很大,专门为图像设计的)。
convolution
convolutional layer的另一种讲解方法:
convolution 就是里面有很多的filter(过滤器),filter的大小为33channel tensor(如果是彩色图片channel为3,黑白则为1)。
filter怎么在图片里面抓取pattern的呢?
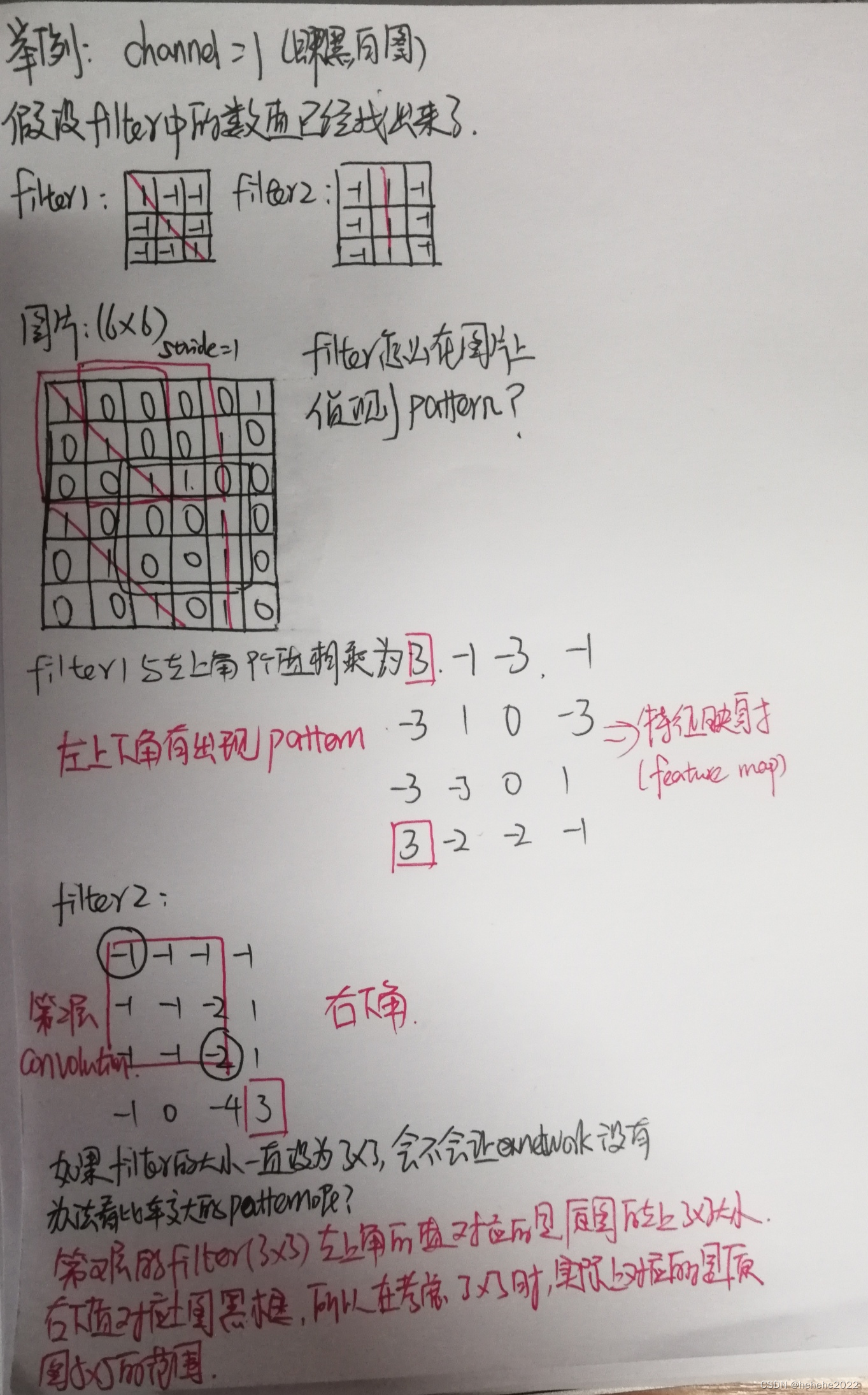
过滤器 得到的 卷积(convolution)的结果,称为特征映射(feature map)
Multiple convolutional layers
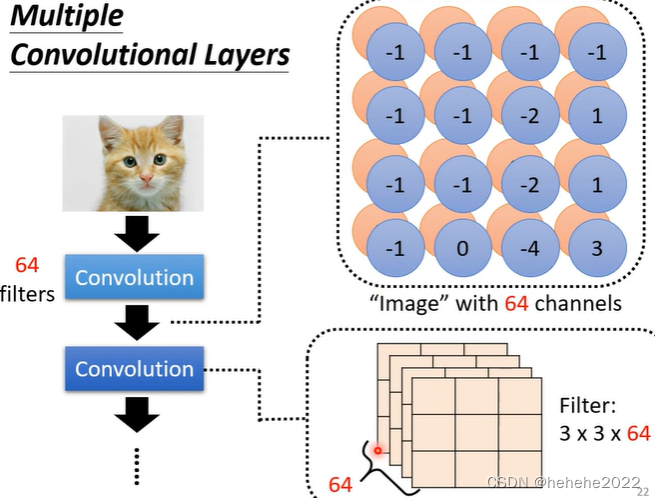
一张图本来有3个channel,通过第一层的convolution(有64个filter)变成新图片有64张channel;第二层的convolution的每个filter大小为3364。
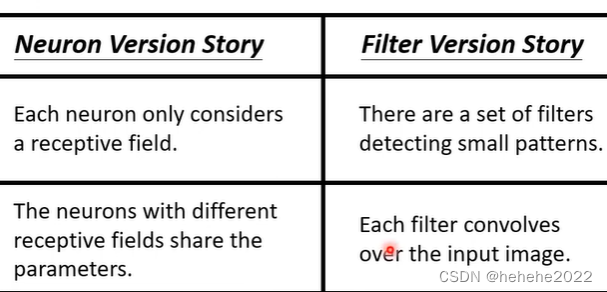
两种讲解方法的对比
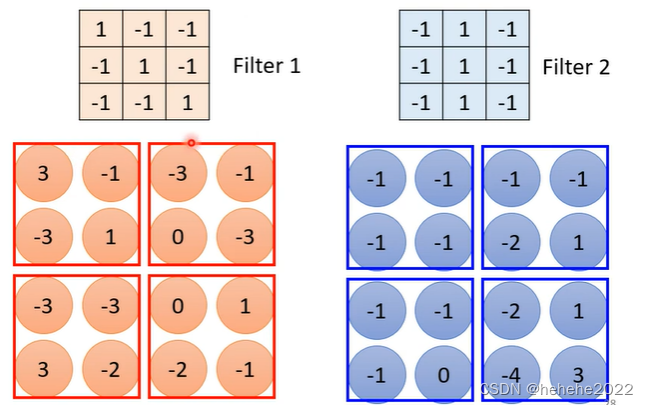
在第一个版本中讲到的共享参数就是用每个filter扫过一张图。
pooling
观察3:
pooling(池化)–max pooling(最大池化) 把一张大的图片缩小,进行信息收缩
比如上述的例子,把filter产生的数字划分为2*2的组,每组中选一个代表,在max pooling选最大的那个值作为代表。输出层将上一层(池化 层)的信息组合起来,并根据这些信息得出整个网络的判断结论。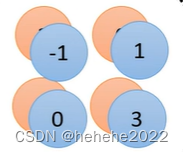
CNN过程:图像–>convolution–>pooling–>convolution—>pooling–>flatten–>fully connected layers–>得出值
二、Application:Playing Go
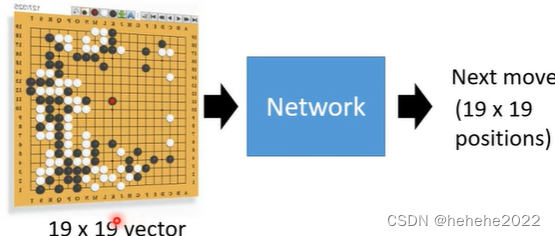
输入19X19的向量,黑子为1,白子为-1,无子为0来描述棋盘,48 channels in alpha go,让network来选择下一步落在19X19的棋盘上那个位置最好;
问题一:为什么可以使用CNN在下围棋上呢:
1.很多重要的pattern只需要看小范围就知道了。
2.同样的pattern可能会出现在不同的位置。
在这两点上影像和下围棋有共同之处,但是没有用到pooling。
总结
了解了CNN主要用于影像处理以及的架构设计(convolution和pooling),CNN解决了图像处理数据量大的问题;CNN不能处理影像放大缩小和旋转的问题,Spatial transformer layer架构可以处理该问题。















 6223
6223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









