







深层神经网络
描述深层神经网络的符号
本网络层数为4,隐藏层数为3
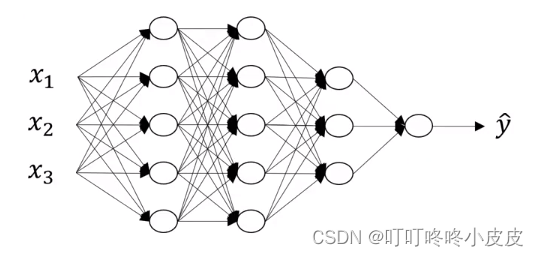
- 本网络是一个4层神经网络:L = 4 (输入层不计入)
- 第L层的神经元个数:n[L],例如:n[1]=5,n[3]=3 ,n[0]=3 (输入层为0层)
- 第L层的激活值:a[L] ( =g[L](z[L]) ),例如:X = a[0], y ^ \widehat{y} y = a[L]
- 第L层的权重值:z[L]
深层网络的前向传播
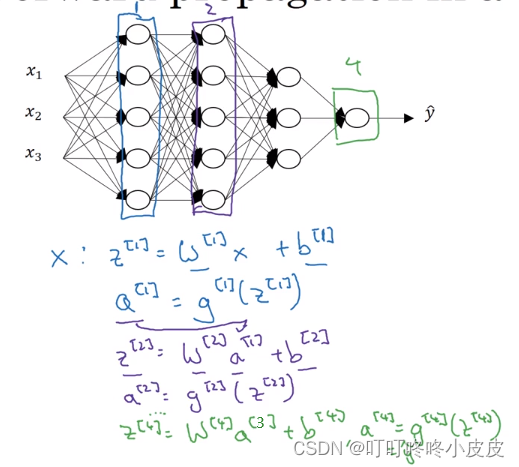
每层前向传播找到的规律如下(已矩阵化):
Z[L] = W[L]A[L-1] + b[L]
A[L] = g[L]( Z[L] )
在层间计算的时候,不可避免使用for循环,并且在运算时一定要注意矩阵维数的变化,大佬也是用笔 画一画写一写。
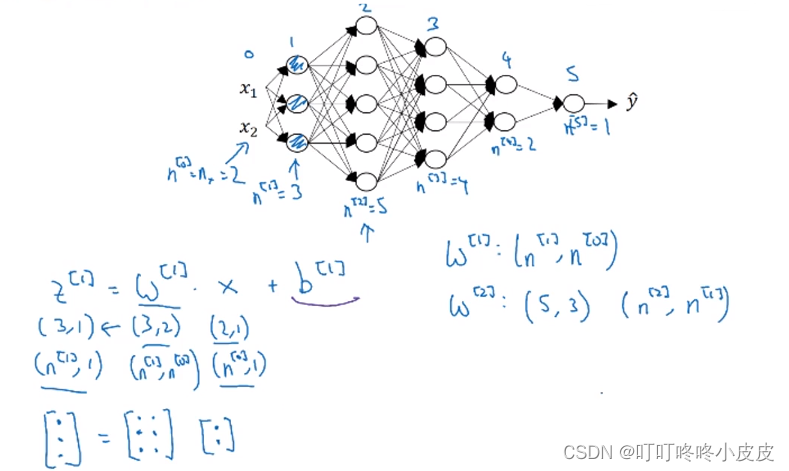
核对矩阵的维数
参数矩阵 W[ i ]
前情提要:z矩阵每一列是一个样本,Z[2] (1),Z[2] (2)…Z[2] (m) 分别是第1个样本,第2个样本…第m个样本在第2隐藏层的运算值。
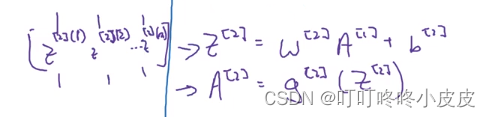
本质是将输入的2个特征点,经过w矩阵,转换为3个特征点,以一个sample为例:
- 先考虑Z[1]矩阵,期望维度是(3,1) 即 (n[1],1);再看X矩阵,已知维度是(2,1) 即 (n[0],1)。
- 需要W[1]矩阵完成X维度=>Z维度的转换。所以W[1]的维度是 (3,2) 即 (n[1],n[0])。
- m个样本时,上面两步骤中维度"1"换为"m"即可:Z[1]期望维度是(3,m),X已知维度是(2,m)
直接记忆公式:
W[L] 维度:(n[L] , n[L-1])
Z[L] 维度:(n[L] , m)
X 维度:(n[0] , m)
A[L] 维度应该与 Z[L] 维度一致
参数矩阵 b[ i ]

因为要进行矩阵加法,所以形状应该和W[1]X 一致,其实也和Z[1]的期望维度一致,所以也是 (3,1) 。
直接记忆公式:
b[L] 维度:(n[L] ,1 )
反向传播中
dw维度 和 w维度一致
db维度 和 b维度一致
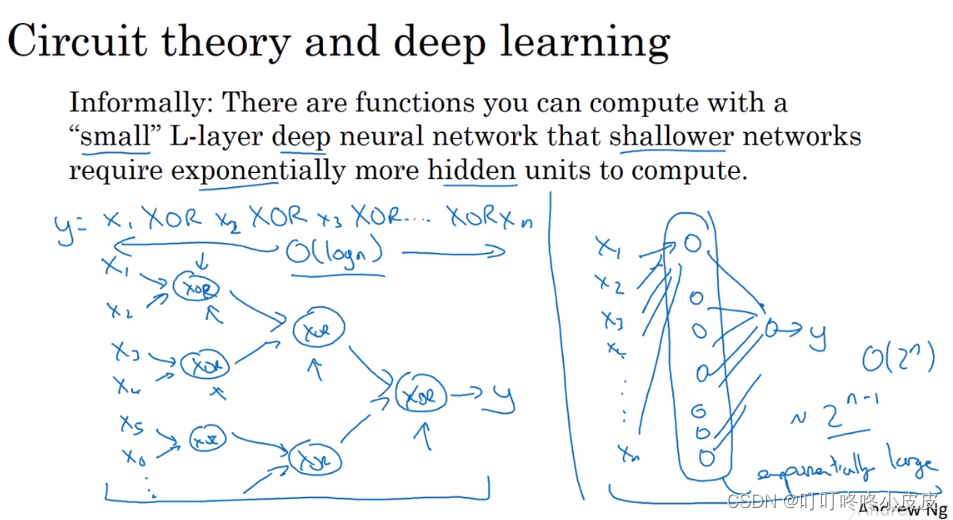
深层网络的优势
例如下面这个电路原理计算:
左侧是深层网络,每层神经元较少且逐步递减。
右侧是单层网络,隐含层需要达到指数级的极多个神经元
搭建深层网络块
某一层网络的正向传播和反向传播
上面方块是该层自左向右是正向传播,下面方块是该层自右向左是反向传播
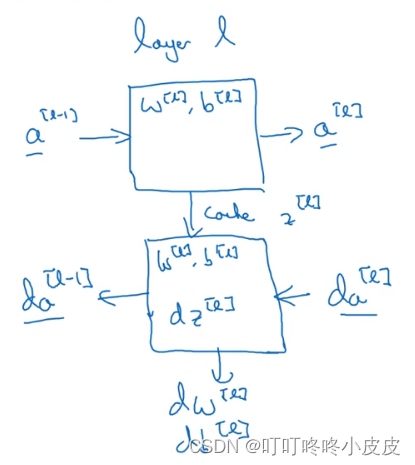
- 正向传播:输入为a[L-1],使用本层w[L] 和b[L] 进行计算,算出z[L] 并在cache中存储,输出a[L]。
- 反向传播:输入da[L],使用本层w[L]和b[L],算出dz[L],算出dw[L] 和db[L] 并在grads中存储,输出da[L-1]
深层网络的正向传播和反向传播
每一组上下两个方块 代表网络的一层。
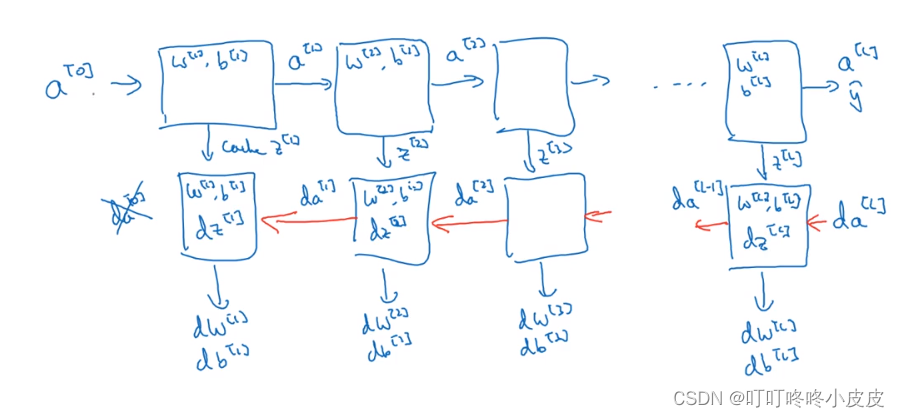
正向传播和反向传播与上面单层网络的传播类似,只需要考虑多层网络的输入输出 前后相继的问题。
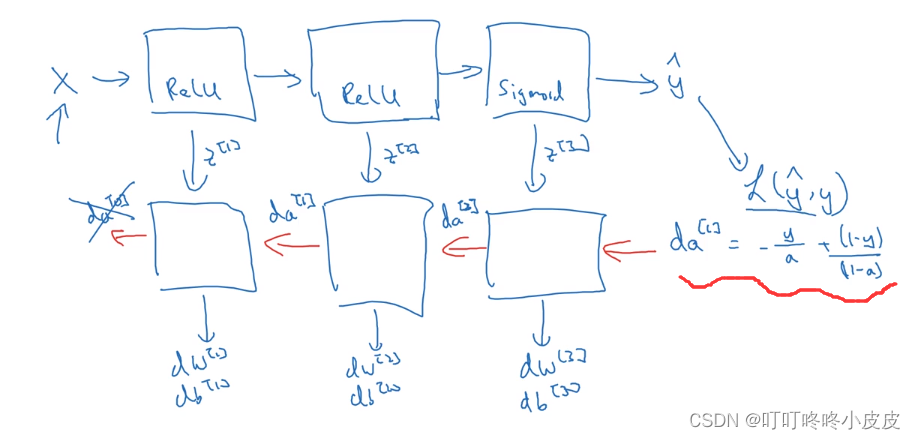
前向和反向传播实现
前向传播
正常的公式:

反向传播
左侧公式大多数和上一周的单层网络类似
其中da[L-1] = w[L].T · dz[L] 的推导原因尚未清楚。

反向传播的初始化
因为反向传播时,最初的输入相当于da[L],而da相当于L对a[L]求导,因此
在矩阵中,由于A[L]的维度也是(n[L],m) , 所以向量化之后,也是横着拼在一个(n[L],m)的向量中

参数和超参数
超参数:控制实际参数: 参数W 和 参数b 的参数。
例如:学习率,迭代次数,隐藏层数量,隐藏层神经元数量,激活函数的选择。
















 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









