







哈哈哈哈,昨天还没有想好怎样循序渐进,所以先丢一个jieba库上去,反正没偏题。然后写完01后呢,就去读论文了,于是有了今天的02
论文0
《基于生成对抗网络的文本生成的研究》
作者:胡懋晗
链接:https://www.doc88.com/p-39359414420190.html?r=1
摘要概括:用GAN无监督生成文本,再在此基础上做情感风格转换,最终生成目标文本。
目标文本的语种:英文(可惜啦!!!中文就好了!!!)
精读内容:
- 研究现状——自编码器、文本生成现状、最优传输理论在DL应用、存在问题和挑战部分
- 经典模型——本章小结部分
- 文本生成模型
- 情感风格转换——实验设计、模型细节部分
-
研究现状
背景信息,读小说一样轻松愉悦又有收获。 -
经典模型
读完本章小结
- 对RNN的原理是知道的,但是还没有项目来耍一耍,马上安排【03】
- 对WGAN(改进版本)有了兴趣,所以学习了一下。 搜索结果:https://blog.csdn.net/qq_41422774/article/details/103588458
读后感:读后感到头很痛。马上安排WGAN的项目【04】- 对LSTM有了兴趣,之前搜索资料的时候有看过生成古诗【05】、生成歌曲【06】,但古诗、音乐跟文章的距离还是很远的,所以就边玩边学吧。
第二章总结:看不出其中奥秘。
- 文本生成模型
- 最优传输?搜索一下。哇塞!这么多篇论文还附带代码!回头通读整理,转化为练手级别的小项目【07~0n】https://blog.csdn.net/qq_41076797/category_11032985.html
- GAN还是得研究透,不然很多概念不能理解透。【0n~0n+1】 第三章总结:发现一个CSDN很强的人,坚持看论文写笔记都是很牛的,可惜电脑坏了,我曾经也是有巨作的!!!!关注了!关注了!https://blog.csdn.net/qq_41076797
感谢这位博主的阅读和分享,为我这种每天学习时间有限的人有了机会能接触多一点东西。😜

- 文本情感风格转换
- 哈哈哈哈哈,那个“蛋糕很难吃”的例子让我觉得很怪异。疑惑:为什么主语会改变,改变文本情感的话,应该是形容词和动词改变吧,名词也变吗?词性辨析的难度应该还是很大的吧?做个词性相关的小项目吧。【看下面】
- 看了实验内容,尝试实现本文的代码吧【0n+1~0n+2】 **第四章总结:本文的文本生成主要还是“生成一个句子感情风格变化了的文本”**而不是自己想象的一篇文章,有点可惜但对于我这个较为年轻的小伙子来说,还是学到了很多的。感谢作者的这篇论文,虽然素未谋面,仍然心怀感激。
关于词性:jieba库又可以拿出来露一手了,哈哈哈哈,这次明说了,是缓兵之计。
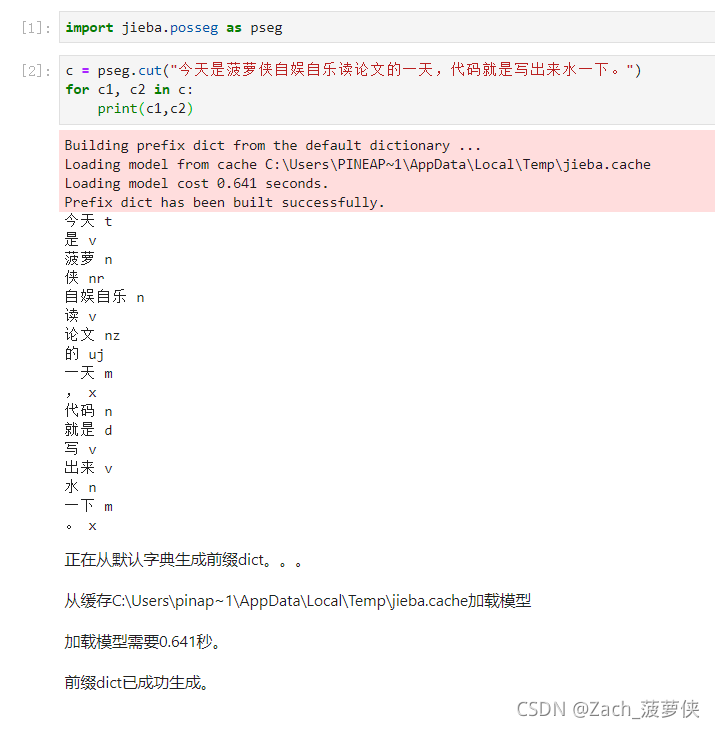
t v n 分别表示啥意思呢?下面这篇博客中有对应表格。
https://blog.csdn.net/fkyyly/article/details/79790873
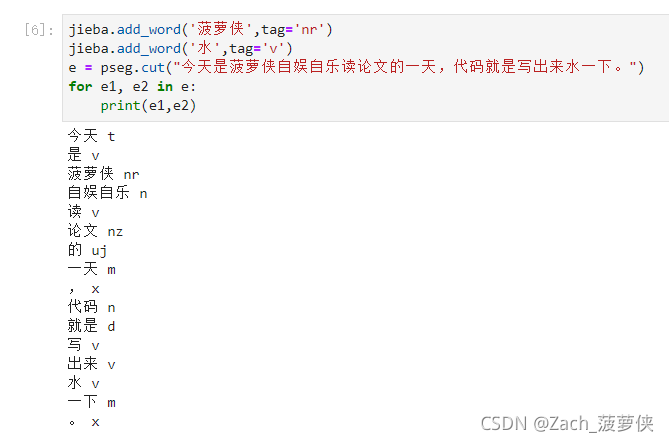
- 不难看出,jieba库还是很容易犯错的
- 菠萝侠:他把这个拆成了 “菠萝” 和 “侠”
- 把”水一下“:标注为名词和量词而不是流行的 “水” 指的是 “划水”,动词,表达简单做点事之意。
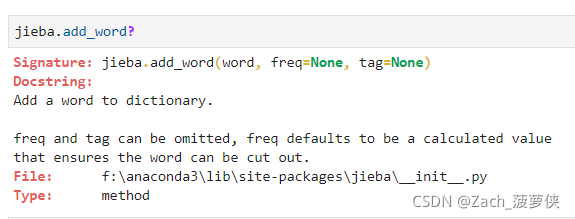
- 解决问题:
- 自定义词典:
- 自定义词典:
个人全文总结:
- 读了整篇文章,熟悉了本文的实验内容和一些关键性的算法,虽然不是能生成目标文章,但是也给了自己很多启发,比如我的大目标是一篇文章,那我可以从先生成一个文本开始,再进行文本内容的补充,最后再根据演讲的对象:比如对待长辈,需要有尊重之情;面对朋友,需要幽默之感;面对晚辈,需要语重心长…总之,很开心读到一篇文章,让自己至少近期有点事情可做。
论文1
基于深度学习的文本生成技术研究
作者:任光华
摘要概括: 运用词向量、Char-RNN模型和WGAN模型生成文本,同时本文新提出的一种模型:基于词向量相似度的CLSTM文本生成模型
目标文本的语种:英文(直接翻到实验,呜呜呜!!又是英文!!不一样的是已经是一段话了!!有所进步!!)
精读内容:
- 绪论——国内外研究现状、论文研究内容
- 词向量——为啥单独一章?
- Char-RNN和WGAN实验
- CLSTM算法和实验
- 绪论
- 哦!原来这个领域有自己的名字“自然语言生成”而且已经有缩写了:NLG,自然语言生成,后面的英文期刊阅读的时候,就能更快搜到我需要的了!多读书果然有好处。
- 刚刚搜了一下,可能是我搜的技术不行,国内外的文本生成其实在自然语言处理这个大领域的比例实在是九牛一毛。其中,大部分还是GAN的基础上出现的。

- 词向量
- 有论文框架,所以作者已经总结的很好了!!!太好了,最喜欢爱总结的作者。
第二章总结这章介绍了多个词向量的方法:离散表示和分布式表示,我认为模型是很关键的,但是还没懂其中奥妙。

十点多了,没时间解释了,今天就到这里吧。
-
Char-RNN和WGAN实验

-
CLSTM算法和实验
















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









