







原文:https://posenhuang.github.io/papers/cikm2013_DSSM_fullversion.pdf
作者简介:https://posenhuang.github.io/
作者是微软研究员,目前在谷歌deepmind,他的其他作品包括《单声道语音分离》、《TIMIT上的核方法匹配深度神经网络》、《单耳声源分离中掩模与深度递归神经网络的联合优化》、《ReasoNet:在机器理解中学会停止阅读》、《通过分段进行序列建模》、《基于神经短语的机器翻译》、《通过元学习生成结构化查询的自然语言》、《M-Walk:学习使用蒙特卡罗树搜索遍历图》、《知道何时停止:评估和验证输出尺寸规格的符合性》、《学习可转移图形探索》、《提高对手稳健性需要标签吗》、《通过区间有界传播实现对符号替换的鲁棒性验证》、《文本删除干预下的鲁棒性验证》、《通过与非纠缠表示的对抗混合实现野外鲁棒性》、《基于序列注意模型的鲁棒图像分类》、《通过反事实评估减少语言模型中的情感偏见》、《WMT2020的DeepMind汉英文档翻译系统》、《低标签、高数据体制下的自我监督对抗鲁棒性》、《**解毒?**语言模型面临的挑战》
可以看见该作者笔耕不辍,是科研人的榜样,同时他的作品涉及广泛,也让我深刻认识到,自己深深的不足,科研的道路是漫长的!
另外,作者邮箱挺搞笑的:(水印挡住了,重新截图)

文章带读:
摘要:
针对潜在语义问题,一般**“基于关键词的匹配”的匹配方式会失败的现象。
例如:我搜:今天出门带伞吗?关键词:今天、出门、伞。但实际上我问的是今天的天气情况**。
这篇文章提出了一种深层结构,就是解决这种潜在语义的文本匹配问题,是怎么做的呢?是如图:

利用用户搜索问题和最终文本的点击率数据(流量数据?不知道咋翻译),然后投影到低维空间并通过计算距离来。同时使用word hashing的方法,来处理大词汇表。
最后,达到了当时2013年的世界最棒的水平。

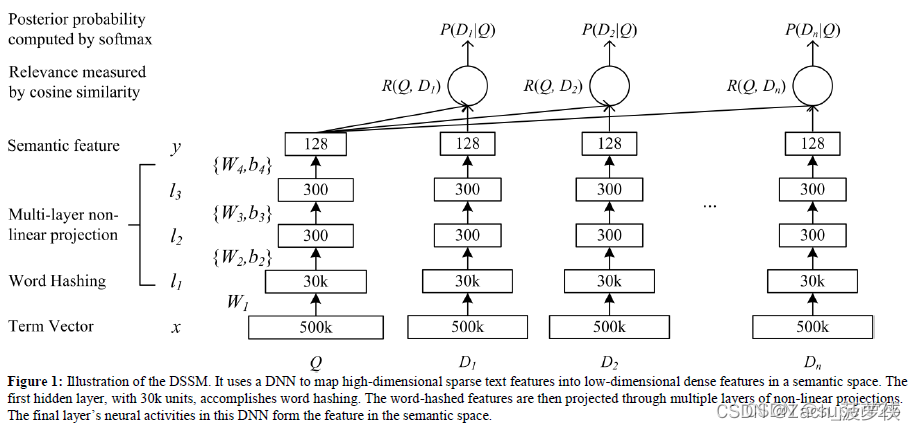
忘情摆渡的DSSMs: Deep Structured Semantic Models的文章https://blog.csdn.net/wangqingbaidu/article/details/79286038
发现作者还做过汇报:PPT如下
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/CVPR15_DeepVision_XiaodongHe.pdf
英文有点看不懂(我很菜,但在学),尽全力看了重点部分,但是防止漏掉一些关键信息,阅读了
superY25的翻译
https://blog.csdn.net/superY_26/article/details/123556772
他在结尾中提到:个人理解
全文讲了这么多,其实总结一下就是利用DNN模型将原来的term向量转化成隐含语义的低维向量,为了解决大词汇库的问题提出了word hashing技术。然后为了适应网页搜索排序任务,使用 P(D∣Q)的条件似然估计优化模型参数。
代码实现:
完整的代码实现有别人做的
一条水里的鱼 https://blog.csdn.net/XiangJiaoJun_/article/details/106144410
简之 https://blog.csdn.net/olizxq/article/details/118068337
文章作者自己也给了code:https://www.microsoft.com/en-us/research/project/dssm/downloads/
我是一个新手,所以还是在别人的代码上面加注释来提升自己的能力吧!
class DSSM(BaseTower):
"""DSSM双塔模型"""
# 初始化(,用户那部分dnn一列特征,本地那部分dnn特征列,gamma==1,dnn_use_bn?
# dnn隐藏层(300,300,128),激活函数为‘relu’.l2_reg_dnn? l2_embedding=1e-6?
# 不随机丢弃=0,标准差=0.0001,随机种子为1024,任务为二分类问题,设备为cpu,没有gpu)
def __init__(self, user_dnn_feature_columns, item_dnn_feature_columns, gamma=1, dnn_use_bn=True,
dnn_hidden_units=(300, 300, 128), dnn_activation='relu', l2_reg_dnn=0, l2_reg_embedding=1e-6,
dnn_dropout=0, init_std=0.0001, seed=1024, task='binary', device='cpu', gpus=None):
# 继承DSSM模型,vibg进行初始化(用户、本地、lr_reg_embedding=??编码,
# std,seed,task,device,gpus)
super(DSSM, self).__init__(user_dnn_feature_columns, item_dnn_feature_columns,
l2_reg_embedding=l2_reg_embedding, init_std=init_std, seed=seed, task=task,
device=device, gpus=gpus)
# 如果用户dnn特征列>0
if len(user_dnn_feature_columns) > 0:
# 该模型的user dnn 就被赋值, DNN模型是直接调用的
# compute计算输入维度(用户特征列),隐藏单元,激活函数,l2 _reg?,use_bn?
# 标准差,device
self.user_dnn = DNN(compute_input_dim(user_dnn_feature_columns), dnn_hidden_units,
activation=dnn_activation, l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout,
use_bn=dnn_use_bn, init_std=init_std, device=device)
self.user_dnn_embedding = None
# 同上!此处省略很多字
if len(item_dnn_feature_columns) > 0:
self.item_dnn = DNN(compute_input_dim(item_dnn_feature_columns), dnn_hidden_units,
activation=dnn_activation, l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout,
use_bn=dnn_use_bn, init_std=init_std, device=device)
self.item_dnn_embedding = None
# 其他参数 gamma,12_reg_embedding,seed,task,device,gpus
# 有点不理解,很多明明都用过了,还要再来一次干嘛??
self.gamma = gamma
self.l2_reg_embedding = l2_reg_embedding
self.seed = seed
self.task = task
self.device = device
self.gpus = gpus
# 定义神经网络方法(输入?)
def forward(self, inputs):
# 若用户特征列>0,用户稀疏嵌入列表,用户稠密值列表=
# input_from_特征列表(输入,用户特征列,用户嵌入列表)
if len(self.user_dnn_feature_columns) > 0:
user_sparse_embedding_list, user_dense_value_list = \
self.input_from_feature_columns(inputs, self.user_dnn_feature_columns, self.user_embedding_dict)
# 用户dnn输入层= 联合dnn输入(用户稀疏嵌入列表,用户稠密值列表)
user_dnn_input = combined_dnn_input(user_sparse_embedding_list, user_dense_value_list)
# 用户dnn嵌入,用户输入
self.user_dnn_embedding = self.user_dnn(user_dnn_input)
# 同上,一模一样
if len(self.item_dnn_feature_columns) > 0:
item_sparse_embedding_list, item_dense_value_list = \
self.input_from_feature_columns(inputs, self.item_dnn_feature_columns, self.item_embedding_dict)
item_dnn_input = combined_dnn_input(item_sparse_embedding_list, item_dense_value_list)
self.item_dnn_embedding = self.item_dnn(item_dnn_input)
# 如果两个特征列都>0
if len(self.user_dnn_feature_columns) > 0 and len(self.item_dnn_feature_columns) > 0:
# 分数 ==余弦相似度(两个嵌入)
# 输出等于score
score = Cosine_Similarity(self.user_dnn_embedding, self.item_dnn_embedding, gamma=self.gamma)
output = self.out(score)
return output
# 否则,返回嵌入错误错误
elif len(self.user_dnn_feature_columns) > 0:
return self.user_dnn_embedding
elif len(self.item_dnn_feature_columns) > 0:
return self.item_dnn_embedding
else:
raise Exception("input Error! user and item feature columns are empty.")
这个时候再来理解双塔模型就感觉容易多了。
图片来自简之的文章。
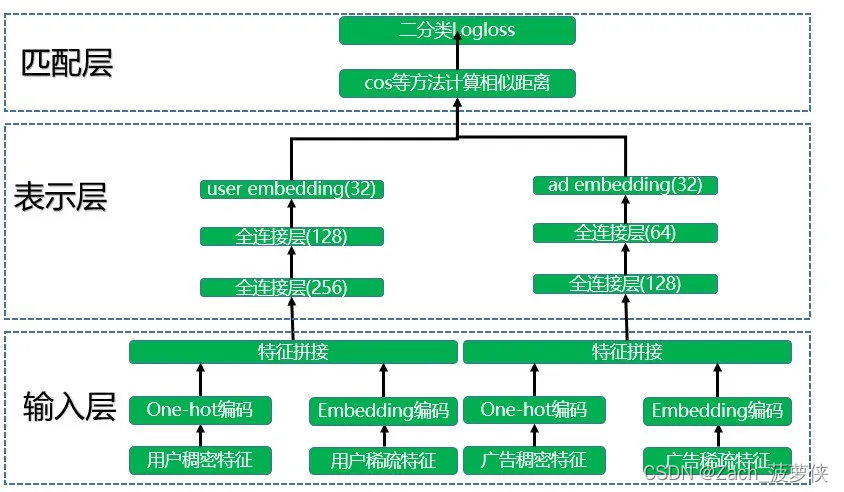
# 在这个类下面继承
# 根据简之所述,BaseTower定义了模型的基本操作,比如输入层的数据预处理、fit()、evaluate()、predict()等方法。
# 我也不懂,暂时先看着
class BaseTower(nn.Module):
# 初始化(,用户dnn特征列,本地dnn特征列,l2 reg 嵌入=1e-5,std,seed,task,device,gpus)
# 都差不多,函数体设置了继承、种子、reg_loss、aux_loss都初始化为全0,device
def __init__(self, user_dnn_feature_columns, item_dnn_feature_columns, l2_reg_embedding=1e-5,
init_std=0.0001, seed=1024, task='binary', device='cpu', gpus=None):
super(BaseTower, self).__init__()
torch.manual_seed(seed)
self.reg_loss = torch.zeros((1,), device=device)
self.aux_loss = torch.zeros((1,), device=device)
self.device = device
self.gpus = gpus
# 判断是否有gpu并确认是同一个gpu
if self.gpus and str(self.gpus[0]) not in self.device:
raise ValueError("`gpus[0]` should be the same gpu with `device`")
# 特征序号=
# 又是build input features这个函数,看见几次了
# (用户dnn特征列,本地dnn特征列)
self.feature_index = build_input_features(user_dnn_feature_columns + item_dnn_feature_columns)
# 将参数传递给self
# 并用创建嵌入矩阵来将用户矩阵制作成
self.user_dnn_feature_columns = user_dnn_feature_columns
self.user_embedding_dict = create_embedding_matrix(self.user_dnn_feature_columns, init_std,
sparse=False, device=device)
self.item_dnn_feature_columns = item_dnn_feature_columns
self.item_embedding_dict = create_embedding_matrix(self.item_dnn_feature_columns, init_std,
sparse=False, device=device)
self.regularization_weight = []
self.add_regularization_weight(self.user_embedding_dict.parameters(), l2=l2_reg_embedding)
self.add_regularization_weight(self.item_embedding_dict.parameters(), l2=l2_reg_embedding)
self.out = PredictionLayer(task,)
self.to(device)
# parameters of callbacks
self._is_graph_network = True # used for ModelCheckpoint
self.stop_training = False # used for EarlyStopping
def fit(self, x=None, y=None, batch_size=None, epochs=1, verbose=1, initial_epoch=0, validation_split=0.,
validation_data=None, shuffle=True, callbacks=None):
if isinstance(x, dict):
x = [x[feature] for feature in self.feature_index]
do_validation = False
if validation_data:
do_validation = True
if len(validation_data) == 2:
val_x, val_y = validation_data
val_sample_weight = None
elif len(validation_data) == 3:
val_x, val_y, val_sample_weight = validation_data
else:
raise ValueError(
'When passing a `validation_data` argument, '
'it must contain either 2 items (x_val, y_val), '
'or 3 items (x_val, y_val, val_sample_weights), '
'or alternatively it could be a dataset or a '
'dataset or a dataset iterator. '
'However we received `validation_data=%s`' % validation_data)
if isinstance(val_x, dict):
val_x = [val_x[feature] for feature in self.feature_index]
elif validation_split and 0 < validation_split < 1.:
do_validation = True
if hasattr(x[0], 'shape'):
split_at = int(x[0].shape[0] * (1. - validation_split))
else:
split_at = int(len(x[0]) * (1. - validation_split))
x, val_x = (slice_arrays(x, 0, split_at),
slice_arrays(x, split_at))
y, val_y = (slice_arrays(y, 0, split_at),
slice_arrays(y, split_at))
else:
val_x = []
val_y = []
for i in range(len(x)):
if len(x[i].shape) == 1:
x[i] = np.expand_dims(x[i], axis=1)
train_tensor_data = Data.TensorDataset(torch.from_numpy(
np.concatenate(x, axis=-1)), torch.from_numpy(y))
if batch_size is None:
batch_size = 256
model = self.train()
loss_func = self.loss_func
optim = self.optim
if self.gpus:
print('parallel running on these gpus:', self.gpus)
model = torch.nn.DataParallel(model, device_ids=self.gpus)
batch_size *= len(self.gpus) # input `batch_size` is batch_size per gpu
else:
print(self.device)
train_loader = DataLoader(dataset=train_tensor_data, shuffle=shuffle, batch_size=batch_size)
sample_num = len(train_tensor_data)
steps_per_epoch = (sample_num - 1) // batch_size + 1
# train
print("Train on {0} samples, validate on {1} samples, {2} steps per epoch".format(
len(train_tensor_data), len(val_y), steps_per_epoch))
for epoch in range(initial_epoch, epochs):
epoch_logs = {}
start_time = time.time()
loss_epoch = 0
total_loss_epoch = 0
train_result = {}
with tqdm(enumerate(train_loader), disable=verbose != 1) as t:
for _, (x_train, y_train) in t:
x = x_train.to(self.device).float()
y = y_train.to(self.device).float()
y_pred = model(x).squeeze()
optim.zero_grad()
loss = loss_func(y_pred, y.squeeze(), reduction='sum')
reg_loss = self.get_regularization_loss()
total_loss = loss + reg_loss + self.aux_loss
loss_epoch += loss.item()
total_loss_epoch += total_loss.item()
total_loss.backward()
optim.step()
if verbose > 0:
for name, metric_fun in self.metrics.items():
if name not in train_result:
train_result[name] = []
train_result[name].append(metric_fun(
y.cpu().data.numpy(), y_pred.cpu().data.numpy().astype('float64')
))
# add epoch_logs
epoch_logs["loss"] = total_loss_epoch / sample_num
for name, result in train_result.items():
epoch_logs[name] = np.sum(result) / steps_per_epoch
if do_validation:
eval_result = self.evaluate(val_x, val_y, batch_size)
for name, result in eval_result.items():
epoch_logs["val_" + name] = result
if verbose > 0:
epoch_time = int(time.time() - start_time)
print('Epoch {0}/{1}'.format(epoch + 1, epochs))
eval_str = "{0}s - loss: {1: .4f}".format(epoch_time, epoch_logs["loss"])
for name in self.metrics:
eval_str += " - " + name + ": {0: .4f} ".format(epoch_logs[name]) + " - " + \
"val_" + name + ": {0: .4f}".format(epoch_logs["val_" + name])
print(eval_str)
if self.stop_training:
break
def evaluate(self, x, y, batch_size=256):
pred_ans = self.predict(x, batch_size)
eval_result = {}
for name, metric_fun in self.metrics.items():
eval_result[name] = metric_fun(y, pred_ans)
return eval_result
def predict(self, x, batch_size=256):
model = self.eval()
if isinstance(x, dict):
x = [x[feature] for feature in self.feature_index]
for i in range(len(x)):
if len(x[i].shape) == 1:
x[i] = np.expand_dims(x[i], axis=1)
tensor_data = Data.TensorDataset(
torch.from_numpy(np.concatenate(x, axis=-1))
)
test_loader = DataLoader(
dataset=tensor_data, shuffle=False, batch_size=batch_size
)
pred_ans = []
with torch.no_grad():
for _, x_test in enumerate(test_loader):
x = x_test[0].to(self.device).float()
y_pred = model(x).cpu().data.numpy()
pred_ans.append(y_pred)
return np.concatenate(pred_ans).astype("float64")
def input_from_feature_columns(self, X, feature_columns, embedding_dict, support_dense=True):
sparse_feature_columns = list(
filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if len(feature_columns) else []
dense_feature_columns = list(
filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if len(feature_columns) else []
varlen_sparse_feature_columns = list(
filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
if not support_dense and len(dense_feature_columns) > 0:
raise ValueError(
"DenseFeat is not supported in dnn_feature_columns")
sparse_embedding_list = [embedding_dict[feat.embedding_name](
X[:, self.feature_index[feat.name][0]:self.feature_index[feat.name][1]].long()) for
feat in sparse_feature_columns]
varlen_sparse_embedding_list = get_varlen_pooling_list(embedding_dict, X, self.feature_index,
varlen_sparse_feature_columns, self.device)
dense_value_list = [X[:, self.feature_index[feat.name][0]:self.feature_index[feat.name][1]] for feat in
dense_feature_columns]
return sparse_embedding_list + varlen_sparse_embedding_list, dense_value_list
def compute_input_dim(self, feature_columns, include_sparse=True, include_dense=True, feature_group=False):
sparse_feature_columns = list(
filter(lambda x: isinstance(x, (SparseFeat, VarLenSparseFeat)), feature_columns)) if len(
feature_columns) else []
dense_feature_columns = list(
filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if len(feature_columns) else []
dense_input_dim = sum(
map(lambda x: x.dimension, dense_feature_columns))
if feature_group:
sparse_input_dim = len(sparse_feature_columns)
else:
sparse_input_dim = sum(feat.embedding_dim for feat in sparse_feature_columns)
input_dim = 0
if include_sparse:
input_dim += sparse_input_dim
if include_dense:
input_dim += dense_input_dim
return input_dim
def add_regularization_weight(self, weight_list, l1=0.0, l2=0.0):
if isinstance(weight_list, torch.nn.parameter.Parameter):
weight_list = [weight_list]
else:
weight_list = list(weight_list)
self.regularization_weight.append((weight_list, l1, l2))
def get_regularization_loss(self):
total_reg_loss = torch.zeros((1,), device=self.device)
for weight_list, l1, l2 in self.regularization_weight:
for w in weight_list:
if isinstance(w, tuple):
parameter = w[1] # named_parameters
else:
parameter = w
if l1 > 0:
total_reg_loss += torch.sum(l1 * torch.abs(parameter))
if l2 > 0:
try:
total_reg_loss += torch.sum(l2 * torch.square(parameter))
except AttributeError:
total_reg_loss += torch.sum(l2 * parameter * parameter)
return total_reg_loss
def add_auxiliary_loss(self, aux_loss, alpha):
self.aux_loss = aux_loss * alpha
def compile(self, optimizer, loss=None, metrics=None):
self.metrics_names = ["loss"]
self.optim = self._get_optim(optimizer)
self.loss_func = self._get_loss_func(loss)
self.metrics = self._get_metrics(metrics)
def _get_optim(self, optimizer):
if isinstance(optimizer, str):
if optimizer == "sgd":
optim = torch.optim.SGD(self.parameters(), lr=0.01)
elif optimizer == "adam":
optim = torch.optim.Adam(self.parameters()) # 0.001
elif optimizer == "adagrad":
optim = torch.optim.Adagrad(self.parameters()) # 0.01
elif optimizer == "rmsprop":
optim = torch.optim.RMSprop(self.parameters())
else:
raise NotImplementedError
else:
optim = optimizer
return optim
def _get_loss_func(self, loss):
if isinstance(loss, str):
if loss == "binary_crossentropy":
loss_func = F.binary_cross_entropy
elif loss == "mse":
loss_func = F.mse_loss
elif loss == "mae":
loss_func = F.l1_loss
else:
raise NotImplementedError
else:
loss_func = loss
return loss_func
def _log_loss(self, y_true, y_pred, eps=1e-7, normalize=True, sample_weight=None, labels=None):
# change eps to improve calculation accuracy
return log_loss(y_true,
y_pred,
eps,
normalize,
sample_weight,
labels)
def _get_metrics(self, metrics, set_eps=False):
metrics_ = {}
if metrics:
for metric in metrics:
if metric == "binary_crossentropy" or metric == "logloss":
if set_eps:
metrics_[metric] = self._log_loss
else:
metrics_[metric] = log_loss
if metric == "auc":
metrics_[metric] = roc_auc_score
if metric == "mse":
metrics_[metric] = mean_squared_error
if metric == "accuracy" or metric == "acc":
metrics_[metric] = lambda y_true, y_pred: accuracy_score(
y_true, np.where(y_pred > 0.5, 1, 0))
self.metrics_names.append(metric)
return metrics_
@property
def embedding_size(self):
feature_columns = self.dnn_feature_columns
sparse_feature_columns = list(
filter(lambda x: isinstance(x, (SparseFeat, VarLenSparseFeat)), feature_columns)) if len(
feature_columns) else []
embedding_size_set = set([feat.embedding_dim for feat in sparse_feature_columns])
if len(embedding_size_set) > 1:
raise ValueError("embedding_dim of SparseFeat and VarlenSparseFeat must be same in this model!")
return list(embedding_size_set)[0]
还有剩下的,回头更新!















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









