







在芯片的构架中有两条线,一条为高速的AHB(Advanced High performance Bus)总线,另一条为较低速的APB(Advanced Peripheral Bus)总线。SRAM位于AHB总线上,总线上分为主从模块,SRAM是从模块,它只能根据外部输入的命令做出相应行为。
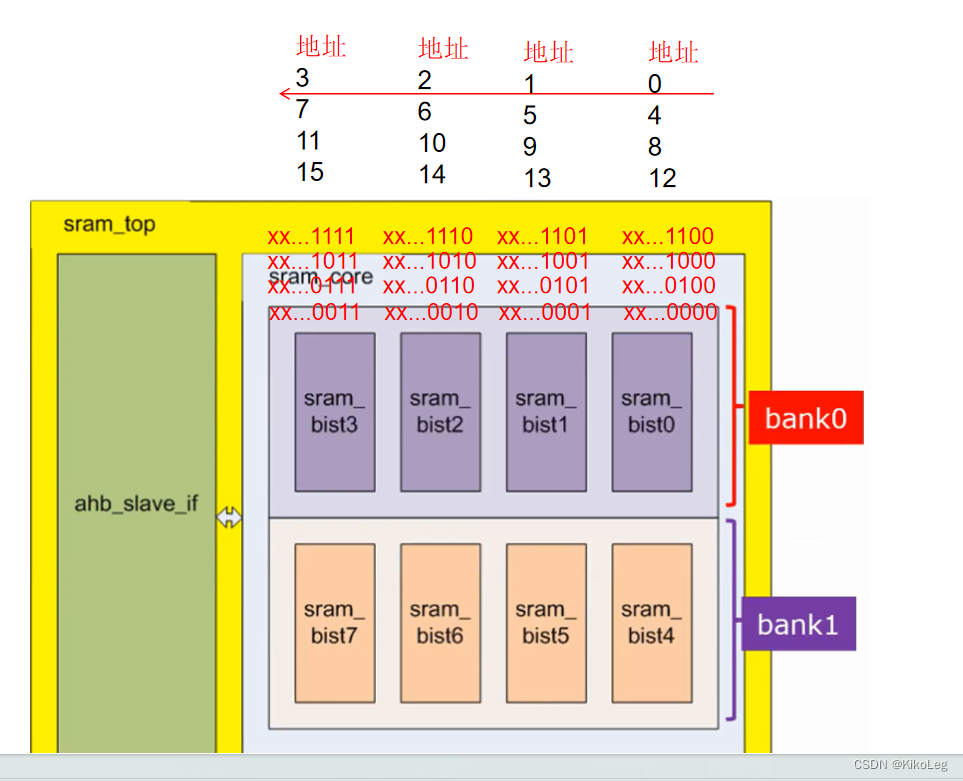
所以AHB-SRAM操作总共分为几个部分,一个是从AHB总线传来的命令,另一个就是将命令转化为SRAM内部操作;有两个模块,一个是AHB与SRAM之间信号传递的interface,另一个是sram内部的存储模块,我们将sram分为八块,因为不选中其他块的话就会降低功耗,所以分多块可以降低功耗,每一块是8Kx8,就是8KB的容量,八块就是64KB的容量(纵向为地址,横向为位宽)
这里将这两个模块封装为一个top模块,由它来接受AHB的控制信号:
hsel为选中SRAM模块,若为1则选中。
hwrite为读写操作,1为写,0为读。
hready为准备就绪。master发送给slave
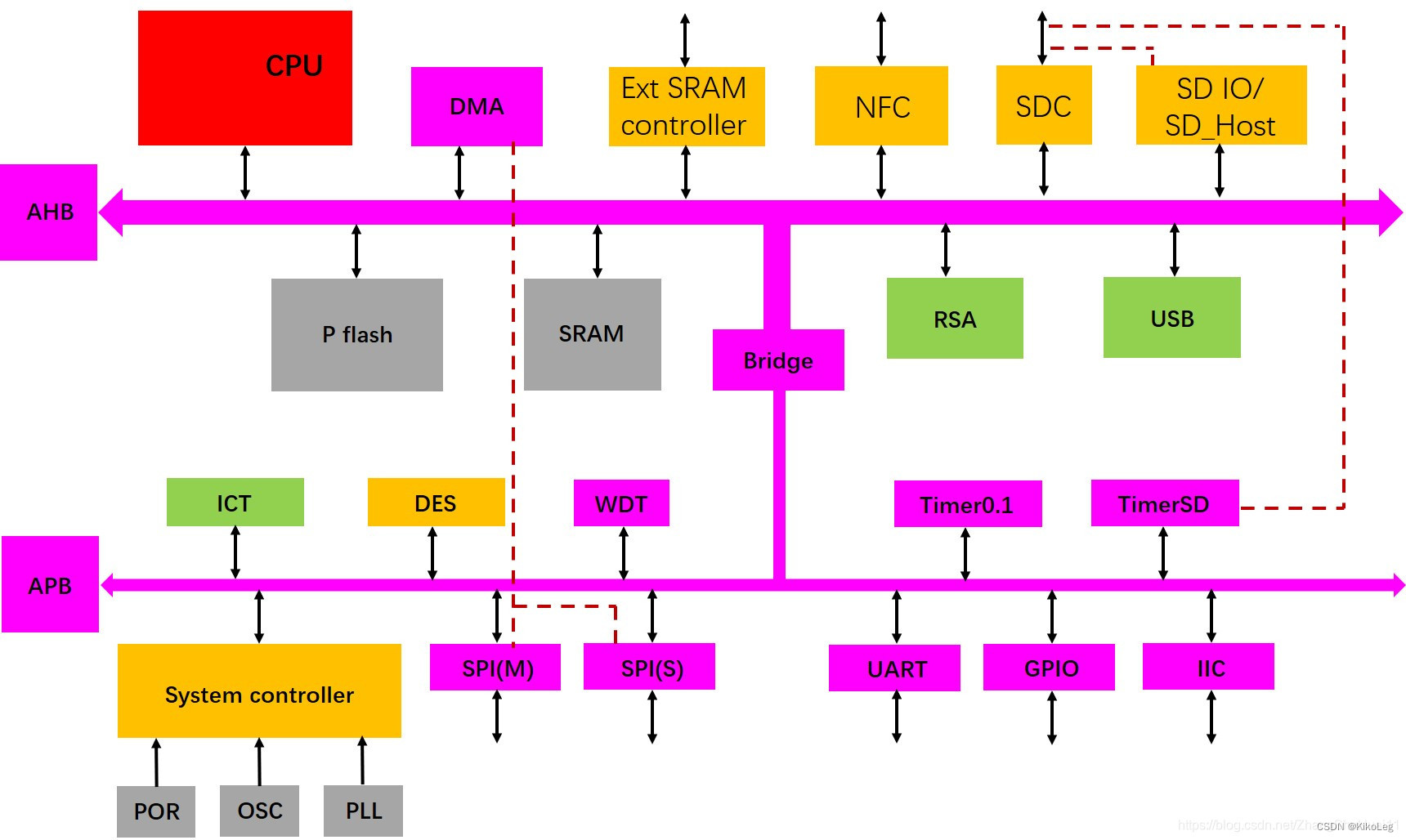
hsize比较重要,为读写的位宽,00为8bit,01为16bit,10为32bit,11为64bit,以此类推。
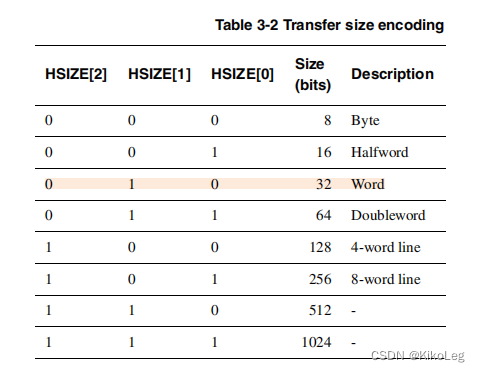
hburst也是比较重要的一个点,而且较难理解,我理解的是连续传输好几个数据,hburst提供了对写入地址的递增操作,INCR很简单就是直接加,不循环,wrap为循环加。例如传一个4-beat(共四段)的wrapping brust of word(4-byte),此时每次写入的地址应该加4,且最后一个地址加4就回到初始地址,即:0X34,0X38,0X3C,0X30。如果是warp8的话初始地址还是0X34,最后的地址还是0X30,但是中间的地址变为38,3C,20,24,28,2C。
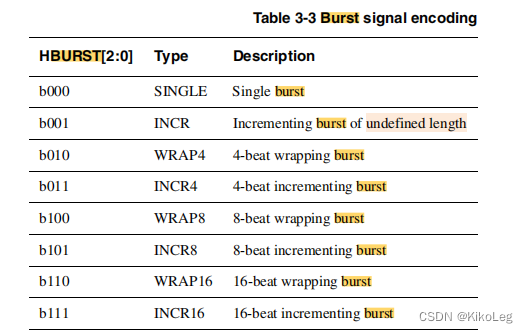
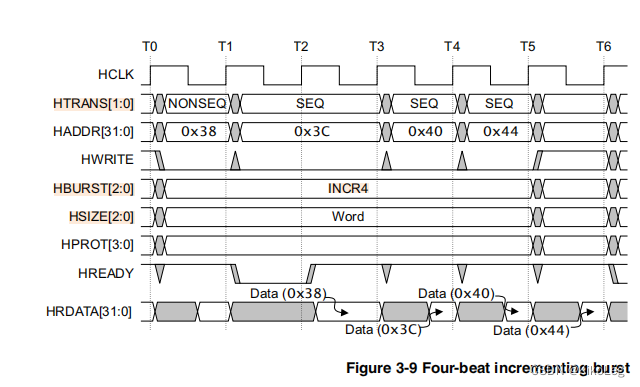
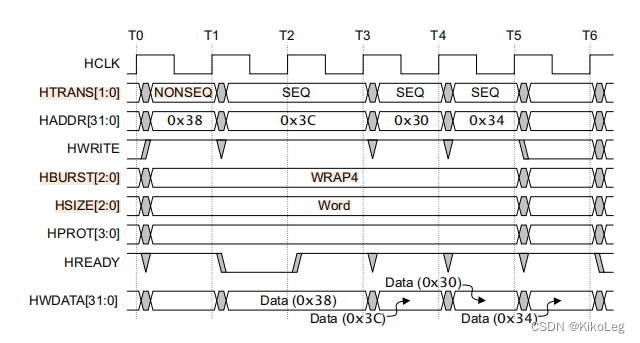

Htrans为 表示此时的状态,一般用到的是IDLE和NONSEQ,SEQ的开头必须是NONSEQ,表示为连续传输,和burst一起用。

再加上输入地址haddr和写入数据hwdata就构成了AHB总线的输入信号。输入到interface中,在if中需要通过读写命令,已经地址,对SRAM进行控制,同时也要将SRAM中读取的值输出出来。
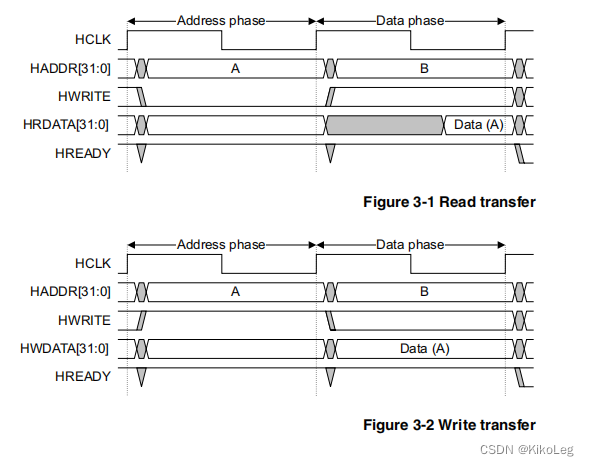
接下来就需要了解一下AHB-SRAM的协议,AHB总线的协议在时序上的体现为,先发送读/写地址,再发送/写入数据,需要有一个时钟的延迟。
AHB—SRAMC项目(结构图,核心代码、Testbench架构)-CSDN博客
那么if是如何对SRAM进行控制的呢,如何知道写入哪一块sram中呢 ?我们对if内的语句加以分析:首先将八块sram分为两部分bank0和bank1,由地址(64K地址(2^6 * 2^10=2^16),地址为16位)的最高位决定。bank-sel为bank的选择信号,最高位为1
(说明地址为2^15~2^16-1:1000000000000000~1111111111111111)选中bank1
(sram4sram5,sram6,sram7,)
最高位为0
((说明地址为0~2^15-1):0000000000000000~0111111111111111)选中bank0
(sram0sram1,sram2,sram3)
assign bank_sel = (sram_csn_en && (sram_addr[15] == 1'b0))?1'b1:1'b0; 四块sram组合起来为32位宽,那么输入8位,16位的话该怎么办呢?
bank_csn为四块sram的片选
assign bank0_csn = (sram_csn_en && (sram_addr[15] == 1'b0))?sram_csn:4'b1111;
assign bank1_csn = (sram_csn_en && (sram_addr[15] == 1'b1))?sram_csn:4'b1111; sram_csn如下,haddr_sel为地址的最后两位,haddr_sel=sram_addr[1:0],hsize_sel表示传输数据的位宽,如上所述,当为10时,32位,四片全选,当为01时,16位,只选两片,当为0时,8位只选一片。选择的规则则是用地址的最后两位haddr_sel。
不知道有没有注意到AHB的输入地址为16位,但是单片sram为8K地址,只有13位,少了三位去哪了? 最高位放在了bank的选择上,最低两位放在了片选sram上,再看代码8位时,从右到左,地址一次增加。
always@(hsize_sel or haddr_sel) begin
if(hsize_sel == 2'b10) //32
sram_csn = 4'b0;
else if(hsize_sel == 2'b01) //16
begin
if(haddr_sel[1] == 1'b0)
sram_csn = 4'b1100;
else
sram_csn = 4'b0011;
end
else if(hsize_sel == 2'b00) //8bits
begin
case(haddr_sel)
2'b00:sram_csn = 4'b1110; //访问最右侧的sram
2'b01:sram_csn = 4'b1101; //访问最右侧左边第一片sram
2'b10:sram_csn = 4'b1011; //访问最左侧右边第一片sram
2'b11:sram_csn = 4'b0111; //访问最左侧的sram
default:sram_csn = 4'b1111;
endcase
end
else
sram_csn = 4'b1111;
end意思是只要最后两位地址为0的就选中sram0 ,只要最后两位地址为1就选中sram1....以此类推,我们单独研究一块sram就可以发现,他内部的地址实际上是以4在增加,整个bank地址是连续的分布在四片sram中的,同一层的地址是连续的。原因是单词读写32bit是需要同时启用四块sram的,因为单片的位宽只有8位。所以输入到sram-core中的地址需要除去第一位和后两位。
assign sram_addr_out = sram_addr[14:2]
最后对于rtl代码还有比较重要的一点是,sram的时序和AHB不同,AHB的地址和数据是分离的,而SRAM的地址和数据需要是同一时刻发送到的。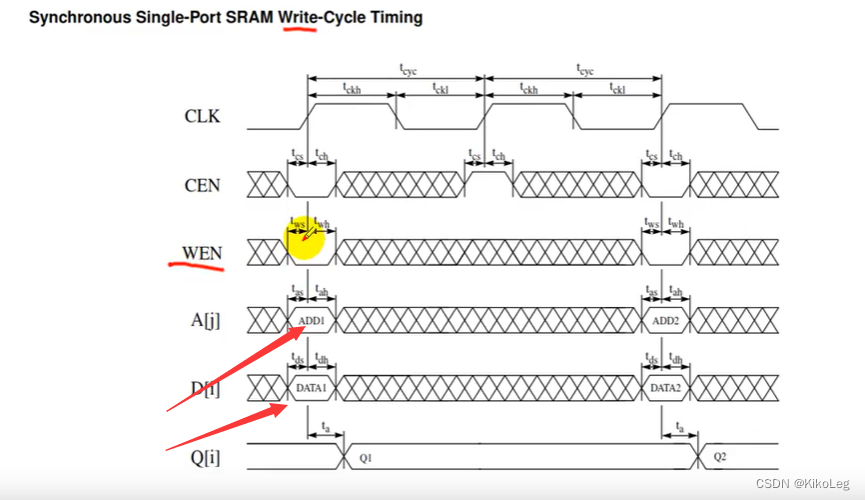
所以需要把除了data的AHB信号都打一拍,与数据同时刻。
else if(hsel && hready)
begin
hwrite_r <= hwrite;
hsize_r <= hsize;
hburst_r <= hburst;
htrans_r <= htrans;
haddr_r <= haddr;
end----------------------------------------------------分割线------------------------------------------------------------------
至此就差不多讲好了AHB-SRAM的rtl原理,协议等。下面就对其输入激励。 先搭建一个简单的
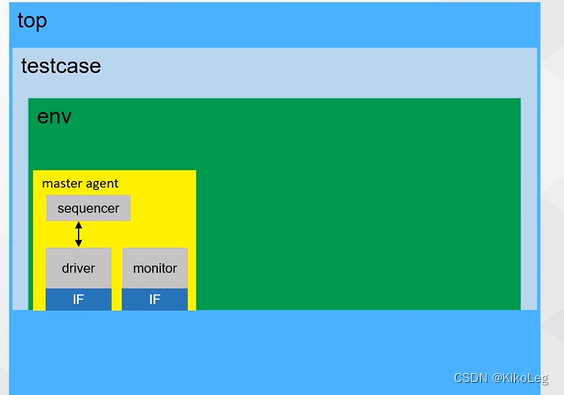
包含的文件有:
层次结构为:
首先写interface:需要输入clk和rst。driver将信号输入给DUT,monitor从DUT捕获信号,所以在driver的clocking中大多为output(hrdata为input,为返回值),在monitor中全为input。clocking的作用是将信号打包到同一时刻触发,在这里在同时在上升沿触发,例如testbench中的#10 hsel=,hsize=...
sequencer直接从uvm_sequencer中扩展,功能已经很多了,无需添加。
my_transaction为随机数据包,从uvm_sequence_item扩展,内涵随机数,在这里只先定义了输入数据和地址的随机值,并使用uvm_filed机制,为其赋予更多的可操作性。
sequence在功能在body任务中,使用`uvm_do宏进行发送transaction数据,宏包括的内容有,所以在extends时需要加上transaction
①创建一个my_transaction的实例m_trans;
②产生随机化的transaction;
③将产生的transaction送给sequencer;
除了uvm_do宏,uvm_create宏与uvm_send宏也可以用来产生transaction,示例如下:
virtual task body();
repeat (10) begin
`uvm_create(m_trans)
//用来实例化m_trans, 也可直接调用new进行实例化,如:m_trans = new("m_trans");
assert(m_trans.randomize());
`uvm_send(m_trans)
//将m_trans送到对应的sequencer;
end除了用uvm_do和uvm_creat宏,start_item与finish_item也可以产生transaction,示例如下:
class my_sequence extends uvm_sequence #(my_transaction);
my_transaction m_trans;
...
virtual task body();
repeat (10) begin
tr = new("m_trans");
//start_item在使用前必须对transaction进行实例化
assert(tr.randomize() with {tr.pload.size == 200;});
start_item(tr);
finish_item(tr);
end
endtask
endclassuvm_do括号中为req时不需要提前例化my_transaction,如果例化了transaction后,括号内需写入transaction的例化名。需要注意的是,在task中还需要raise和drop objection。
driver需要和sequencer相连接,发生的地点为agent中,继承于uvm_driver 的driver自带了接口seq_item_port, sequencer自带接口seq_item_export(实际上例化自import)。在agent的connect_phase中完成连接
drv.seq_item_port.connect(sqr.seq_item_export);
这样在driver中使用
seq_item_port.get_next_item(req) ... seq_item_port.item_done() 来获取transaction
如果采用手动sequence的话还需要发送rsp
rsp=my_ transaction: :type_ id: :create("rsq");
$cast(rsp,req.clone());
rsp.set_id_ info(req);
seq_ item_ port. put_ response(rsp);
driver中主要的功能是一开始复位,驱动数据等。
接下来是monitor,负责监视DUT,通过interface获取相应的值,并发送给reference_model
建立完所有agent组件后,需要在agent中例化各部分,并连接driver和sequencer
在env中例化agent
在testcase中例化env,并自动启动sequence。
分析波形图,haddr比hwdata早来一拍,符合AHB的时序,sram_addr和sram_wdata同拍,符合sram时序图。在看内容,到达的16位地址线首位为0,选中bank0,后两位为01,再加上此时hsize=1,16bit传输,选中低两位的sram,bank0_csn=1100。最后传入sram的地址为[14:2]位,传入sram的数据位16bit,并放入sram0和sram1中。
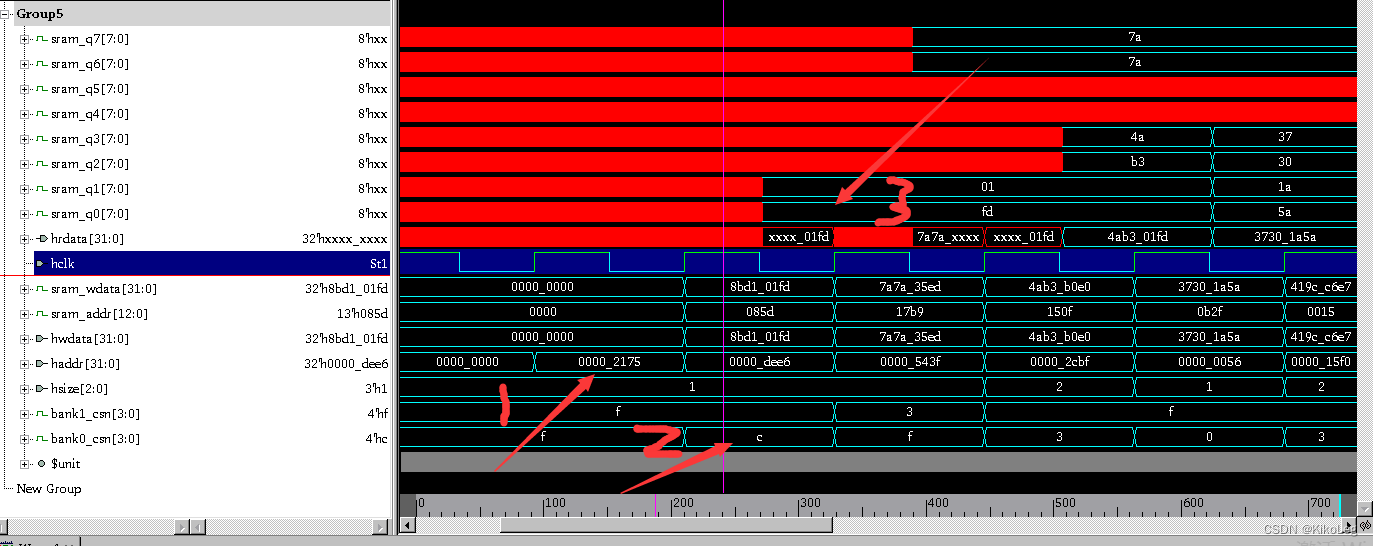
第二个地址最高位为1,所以选中了bank1,hsize还是=1,最后两位为10,选bank1高位的两片sram即sram6 sram7,将输入数据的高16bit输入。为什么选输入数据的高16位呢? 因为32bit本来就是从高到低对应sram的。
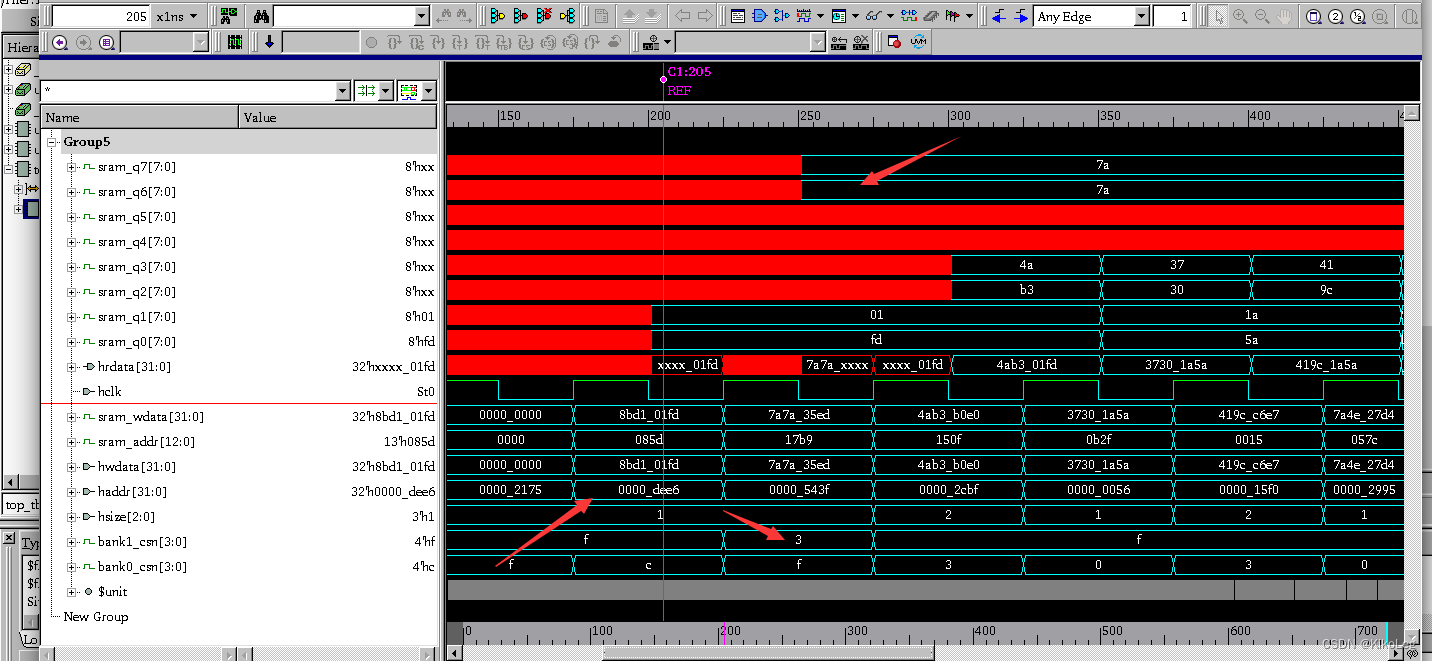
这里的读数据有点问题,但是现在还没加读的功能,所以暂时先不管。
















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









