







 研究发现,基于最大似然的解码方法如Beamsearch会导致文本生成退化。文章提出NucleusSampling,通过限制采样的概率空间,有效避免了通用、重复和不连贯的文本。实验表明,NucleusSampling在Open-ended生成任务中表现出色,尤其是在保持多样性的同时提升文本质量。
研究发现,基于最大似然的解码方法如Beamsearch会导致文本生成退化。文章提出NucleusSampling,通过限制采样的概率空间,有效避免了通用、重复和不连贯的文本。实验表明,NucleusSampling在Open-ended生成任务中表现出色,尤其是在保持多样性的同时提升文本质量。
论文:The Curious Case of Neural Text Degeneration | arXiv
⭐⭐⭐⭐
ICLR 2020
目录
文章速读
文本生成中的解码就是指,GPT 这类模型在做 next token prediction 时,如何从得到的单词概率分布中,选出下一个生成的 token。
这篇文章发现基于最大化似然的解码方法(比如 beam search)会导致生成的文本退化,也就是生成的文本往往是那些通用的、重复的、看上去有点笨拙的,因为 LM 往往会给这类文本打高分。
文章发现,产生的文本出现退化的主要原因是“不可靠的尾部”,也就是那些 LM 在做 next token prediction 时认为出现概率很小的那些词导致的:
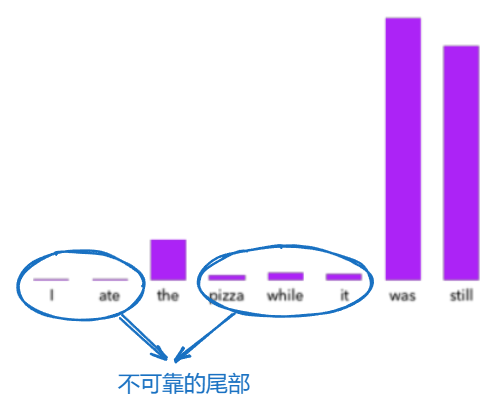
为了解决这个问题,本文提出了 Nucleus Sampling 的采样方法,做法如下:
在单词概率分布中,选出不固定的 k 个单词,让这 k 个单词的概率累加之和超过一个给定的 p p p,然后,next token prediction 就是从这 k 个单词中按照大小比率进行采样,不再考虑这 k 个单词之外的单词了,也就是实现了“truncation”。
具体的严格描述可以参考原论文。
论文值得关注的点
1. 两种 generation:Open-ended 和 Directed
文章着重区分了这两种 Generation:
-
像机器翻译、文本 sumarization、data2text 这类任务都属于 Directed Generation,这种生成任务是受限的有向生成,这种情况下 beam search 所导致的多样性差的问题其实也问题不大。这类任务的解决通常是使用 Encoder-Decoder 这类模型。
-
GPT 的这类生成其实就属于 Open-ended Generation,这类生成很重视上下文的连续性,生成文本的程度也更加自由开放。
所以,本文提出的 Nucleus Sampling 是更加适用于 Open-ended Generation 任务的。
2. 多种不同的采样策略
文章概述了多种不同的采样策略:
- Nucleus Sampling:也就是本文提出的采样策略
- Top- k k k 采样:从固定的概率最高的 k 个单词中进行采样。与 Nucleus Sampling 的区别就是,Top-k 是选择固定的最高 k 个,而 Nucleus Sampling 则是不固定的。
- Sampling with Temperature:类似于对单词概率分布做了一下 softmax,具体可参考原论文。有一个变量“温度 t”会影响概率分布的形状,较低的温度 t 会导致分布更加偏向于高概率事件,但可能会降低生成文本的多样性。
Top- k k k 采样方法存在一个很明显的困难: k k k 很难选。因为 k 选小了的话,会让生成的文本较为 generic 或者 bland;而 k 选大了的话,则可能会让一些不合适的候选者被采样选中导致生成的问题比较离谱。
论文所做的实验
实验的 evaluation 主要分成了三类:Likelihood Evaluation、Distributional Statistical Evaluation 和 Human Evaluation。三类 evaluation 又使用了多个不同的指标。下面介绍一下不同的指标。
1)Perplexity
Perplexity(困惑度)是自然语言处理中用来衡量语言模型性能的一个指标。它衡量的是模型对测试数据的不确定性,即模型对测试集中每个词的预测准确性。困惑度越低,表示模型对数据的预测越准确,语言模型的性能越好。
论文通过衡量一个采样策略生成的文本的 perplexity 和 golden text 的 perplexity 接近程度,来比较不同采样策略的好坏。
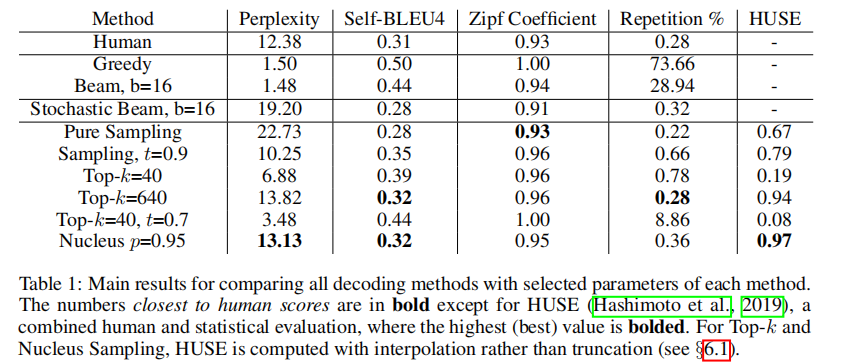
可以从 Table 1 中看到,Nucleus Sampling 得到的 perplexity 与 human text 最接近。
2)Zipf Coefficient
Zipf Coefficient(齐普夫系数)是一个用于衡量文本中词汇分布遵循齐普夫定律程度的指标。齐普夫定律(Zipf’s Law)是一个在自然语言中普遍观察到的现象,它指出在一个文本样本中,一个词的频率与其在频率排名中的位置成反比,且这种关系呈现指数关系。换句话说,排名最高的词出现的频率非常高,而排名较低的词出现的频率迅速下降。
齐普夫系数的意义:
- 齐普夫系数 s 接近1:表示文本中的词汇分布非常遵循齐普夫定律,即少数高频词汇和大量低频词汇的分布特征明显。
- 齐普夫系数 s 大于1:表明文本中的高频词汇比齐普夫定律预测的还要频繁,而低频词汇则相对较少。
- 齐普夫系数 s 小于1:则意味着低频词汇比齐普夫定律预测的更为常见,而高频词汇的频率较低。
实验计算出发现,Pure Sampling 和 Nucleus Sampling 得到的 Zipf Coefficient 是更加符合 human text 的。
3)Self-BLEU
Self-BLEU 指标被用来衡量生成文本的多样性。
通过使用 Self-BLEU 指标,论文作者能够展示 Nucleus Sampling 解码策略在提高生成文本多样性方面的优势,从而支持他们提出的解码方法在避免文本退化和提高生成文本质量方面的有效性。
4)Repetition
这个指标就是判断生成的文本是否存在很多重复的现象。对比之后发现,Nucleus Sampling 策略是适用场景最广的。
5)HUSE
HUSE(Human Unified with Statistical Evaluation)是一种评估文本生成模型性能的指标,它结合了人类评价和统计评估的方法。HUSE 的目的是提供一种更全面的评估机制,不仅考虑生成文本的质量,还考虑文本的多样性。这种评估方法特别适用于自然语言生成任务,如故事生成、对话生成等,其中文本的连贯性、可读性和多样性都是重要的评价因素。HUSE 提供了一个强有力的工具,用于指导和改进文本生成模型的开发和调优。
通过 HUSE 评估,作者能够确定 Nucleus Sampling 是在当时可用的解码策略中,生成高质量且多样化文本的最优方法。
总结
这篇文章指出了在 Open-ended 的文本生成场景下,Pure Sampling、beam search、Top- k k k 等这类方法都往往会出现 copious repetition 或者 incoherence 的问题,而 Nucleus Sampling 则能规避这两类问题。下图给出了各种 sampling 方法出现这两种问题的示例(蓝色高亮是大量重复问题,红色高亮是 incoherence 问题):

不能直接使用最大化似然的解码策略主要原因在于,LM 往往会给那些很通用性、缺乏灵活多样性的文本生成结果以很高的分数,因此直接最大化似然来解码会得到退化的文本生成结果。同时,“不可靠的尾部”又让一些概率很低的候选 token 可能会被采样选中,从而导致生成的文本内容变得离谱。所以依照这些问题,文章才提出了 Nucleus Samping 的采样策略来解决。















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









