







 本文展示了如何使用LangChain和OpenAI技术,结合Markdown文档,构建一个基于RetrievalQA的RAG模型,实现在知识问答中利用本地文档进行有效回答。
本文展示了如何使用LangChain和OpenAI技术,结合Markdown文档,构建一个基于RetrievalQA的RAG模型,实现在知识问答中利用本地文档进行有效回答。
本篇文章通过使用 LangChain + OpenAI 来搭建一个基本的 RAG,实现根据本地文档来进行知识问答。
完整代码如下:
import os
from langchain.chains import RetrievalQA
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import MarkdownTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
# OpenAI 的相关 key
os.environ["OPENAI_API_BASE"] = 'xxxx'
os.environ["OPENAI_API_KEY"] = 'xxxx'
# 加载文档
loader = UnstructuredMarkdownLoader("./TypingWord.md")
documents = loader.load()
# 切分文本
text_splitter = MarkdownTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings() # Document Encoder
db = Chroma.from_documents(texts, embeddings) # 文档库
llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=1) # Generator
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=db.as_retriever(),
verbose=True
)
qa.run("你了解 Typing Word 软件吗")
在这里,本地文档使用了从 Gitee 上的一个项目上下载的 README.md:Typing Word | Gitee,这个 markdown 是对软件产品 Typing Word 的描述。我们使用这个文档构建本地文档库,使用 UnstructuredMarkdownLoader 来加载的这个文档。
因为一个 markdown 文件可能很大,所以需要对其切分为多个 chunk,一个 chunk 也就是一个文档,之后使用 OpenAI 的 Embeddings 将其转化为文档向量,进而构建成本地文档库。
Generator 使用 OpenAI 的对话模型,并借助 LangChain 提供的 RetrievalQA 搭建出 RAG 产品。
运行上述代码后,模型输出为:
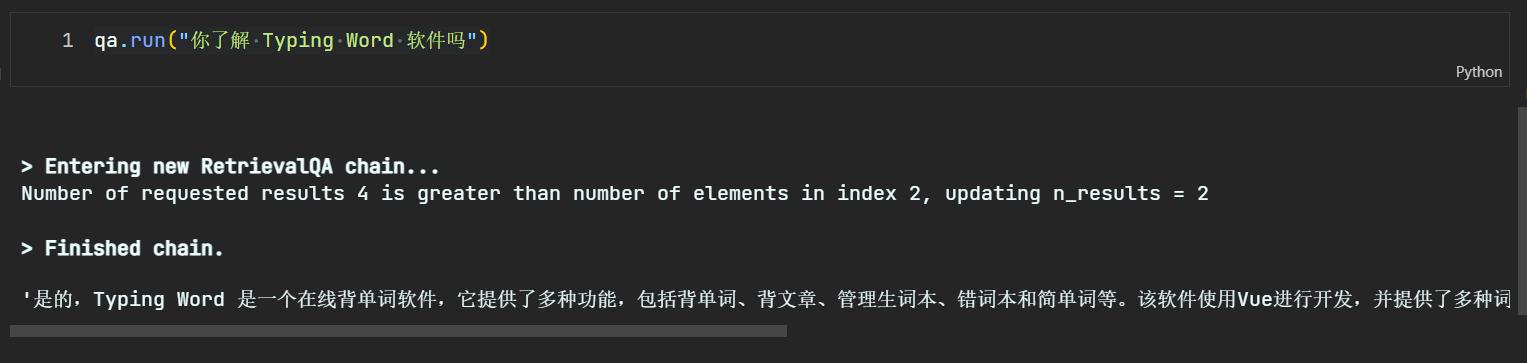
可以看到,输出中包含了本地文档库的知识,如果没有本地文档库的辅助,那么 ChatGPT 的回答会是如下:

可以看到,ChatGPT 将 Typing Word 当做了一个打字练习软件,而非我们本地知识库中的“背单词软件”。















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









