







2021SC@SDUSC
模型结构拆分为Backbone、Neck、Head、Post_Process四部分
首先是Backbone,算法结构图:
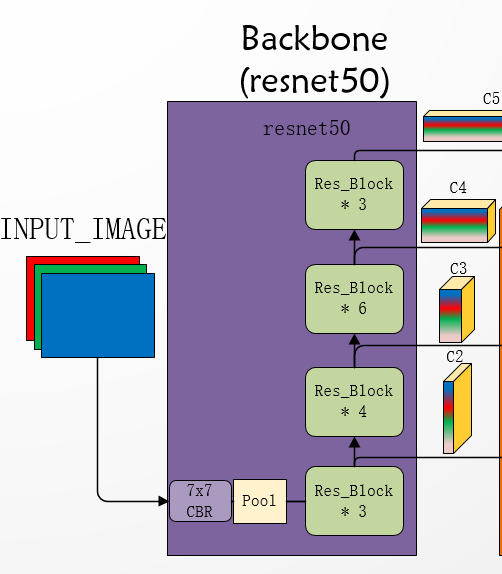
modeling/backbone/resnet.py源码解析
首先是在yaml的配置文件:/configs/_base_/models/mask_rcnn_r50_fpn.yml
'''
ResNet:#初始化
# index 0 stands for res2
depth: 50 #网络层数
norm_type: bn #BN类型
freeze_at: 0 #冻结权重
return_idx: [0,1,2,3] # 主干网络返回的主要阶段特征用于FPN作进一步的特征融合
num_stages: 4 #输出层数,指上面的索引个数
'''
相关引用库:
import numpy as np
from paddle import ParamAttr
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.nn import Conv2D, BatchNorm
from paddle.nn import MaxPool2D
from ppdet.core.workspace import register, serializable
from paddle.regularizer import L2Decay
from .name_adapter import NameAdapter
from numbers import Integral
class ConvNormLayer(nn.Layer):
def __init__(self,
ch_in,
ch_out,
filter_size,
stride,
name_adapter,
act=None,
norm_type='bn',
norm_decay=0.,
freeze_norm=True,
lr=1.0,
name=None):
super(ConvNormLayer, self).__init__()
assert norm_type in ['bn', 'sync_bn']
self.norm_type = norm_type
self.act = act
self.conv = Conv2D(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=1,
weight_attr=ParamAttr(
learning_rate=lr, name=name + "_weights"),
bias_attr=False)
bn_name = name_adapter.fix_conv_norm_name(name)
norm_lr = 0. if freeze_norm else lr
param_attr = ParamAttr(
learning_rate=norm_lr,
regularizer=L2Decay(norm_decay),
name=bn_name + "_scale",
trainable=False if freeze_norm else True)
bias_attr = ParamAttr(
learning_rate=norm_lr,
regularizer=L2Decay(norm_decay),
name=bn_name + "_offset",
trainable=False if freeze_norm else True)
global_stats = True if freeze_norm else False
self.norm = BatchNorm(
ch_out,
act=act,
param_attr=param_attr,
bias_attr=bias_attr,
use_global_stats=global_stats,
moving_mean_name=bn_name + '_mean',
moving_variance_name=bn_name + '_variance')
norm_params = self.norm.parameters()
if freeze_norm:
for param in norm_params:
param.stop_gradient = True
def forward(self, inputs):
out = self.conv(inputs)
if self.norm_type == 'bn':
out = self.norm(out)
return out该类为基础卷积+BN类,定义了相关模型参数以及forword前向传播方法。
class BottleNeck(nn.Layer):
def __init__(self,
ch_in,
ch_out,
stride,
shortcut,
name_adapter,
name,
variant='b',
lr=1.0,
norm_type='bn',
norm_decay=0.,
freeze_norm=True):
super(BottleNeck, self).__init__()
if variant == 'a':
stride1, stride2 = stride, 1
else:
stride1, stride2 = 1, stride
conv_name1, conv_name2, conv_name3, \
shortcut_name = name_adapter.fix_bottleneck_name(name)
self.shortcut = shortcut
if not shortcut:
self.short = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out * 4,
filter_size=1,
stride=stride,
name_adapter=name_adapter,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
name=shortcut_name)
self.branch2a = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=1,
stride=stride1,
name_adapter=name_adapter,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
name=conv_name1)
self.branch2b = ConvNormLayer(
ch_in=ch_out,
ch_out=ch_out,
filter_size=3,
stride=stride2,
name_adapter=name_adapter,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
name=conv_name2)
self.branch2c = ConvNormLayer(
ch_in=ch_out,
ch_out=ch_out * 4,
filter_size=1,
stride=1,
name_adapter=name_adapter,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
name=conv_name3)
def forward(self, inputs):
out = self.branch2a(inputs)
out = self.branch2b(out)
out = self.branch2c(out)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
out = paddle.add(x=out, y=short)
out = F.relu(out)
return out该类为瓶颈模块类 即Res_block
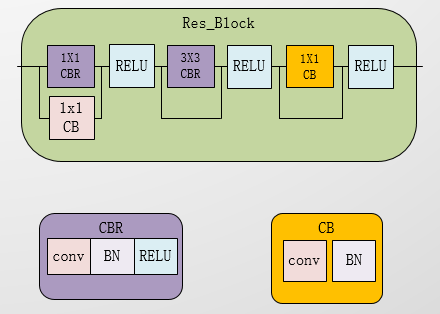
class Blocks(nn.Layer):
def __init__(self,
ch_in,
ch_out,
count,
name_adapter,
stage_num,
lr=1.0,
norm_type='bn',
norm_decay=0.,
freeze_norm=True):
super(Blocks, self).__init__()
self.blocks = []
for i in range(count):
conv_name = name_adapter.fix_layer_warp_name(stage_num, count, i)
block = self.add_sublayer(
conv_name,
BottleNeck(
ch_in=ch_in if i == 0 else ch_out * 4,
ch_out=ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
name_adapter=name_adapter,
name=conv_name,
variant=name_adapter.variant,
lr=lr,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm))
self.blocks.append(block)
def forward(self, inputs):
block_out = inputs
for block in self.blocks:
block_out = block(block_out)
return block_outresnet 大模块类(含有多个瓶颈模块)
rennet 50 101 152 中各中每个block的数量列表:
ResNet_cfg = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}@register
@serializable
class ResNet(nn.Layer):
def __init__(self,
depth=50,
variant='b',
lr_mult=1.,
norm_type='bn',
norm_decay=0,
freeze_norm=True,
freeze_at=0,
return_idx=[0, 1, 2, 3],
num_stages=4):
super(ResNet, self).__init__()
self.depth = depth
self.variant = variant
self.norm_type = norm_type
self.norm_decay = norm_decay
self.freeze_norm = freeze_norm
self.freeze_at = freeze_at
if isinstance(return_idx, Integral):
return_idx = [return_idx]
assert max(return_idx) < num_stages, \
'the maximum return index must smaller than num_stages, ' \
'but received maximum return index is {} and num_stages ' \
'is {}'.format(max(return_idx), num_stages)
self.return_idx = return_idx
self.num_stages = num_stages
block_nums = ResNet_cfg[depth]
na = NameAdapter(self)
conv1_name = na.fix_c1_stage_name()
if variant in ['c', 'd']:
conv_def = [
[3, 32, 3, 2, "conv1_1"],
[32, 32, 3, 1, "conv1_2"],
[32, 64, 3, 1, "conv1_3"],
]
else:
conv_def = [[3, 64, 7, 2, conv1_name]]
self.conv1 = nn.Sequential()
for (c_in, c_out, k, s, _name) in conv_def:
self.conv1.add_sublayer(
_name,
ConvNormLayer(
ch_in=c_in,
ch_out=c_out,
filter_size=k,
stride=s,
name_adapter=na,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr_mult,
name=_name))
self.pool = MaxPool2D(kernel_size=3, stride=2, padding=1)
ch_in_list = [64, 256, 512, 1024]
ch_out_list = [64, 128, 256, 512]
self.res_layers = []
for i in range(num_stages):
stage_num = i + 2
res_name = "res{}".format(stage_num)
res_layer = self.add_sublayer(
res_name,
Blocks(
ch_in_list[i],
ch_out_list[i],
count=block_nums[i],
name_adapter=na,
stage_num=stage_num,
lr=lr_mult,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm))
self.res_layers.append(res_layer)
def forward(self, inputs):
x = inputs['image']
conv1 = self.conv1(x)
x = self.pool(conv1)
outs = []
for idx, stage in enumerate(self.res_layers):
x = stage(x)
if idx == self.freeze_at:
x.stop_gradient = True
if idx in self.return_idx:
outs.append(x)
return outsresnet总类(由resnet的 block类组成)。
然后是Neck部分:算法结构图:
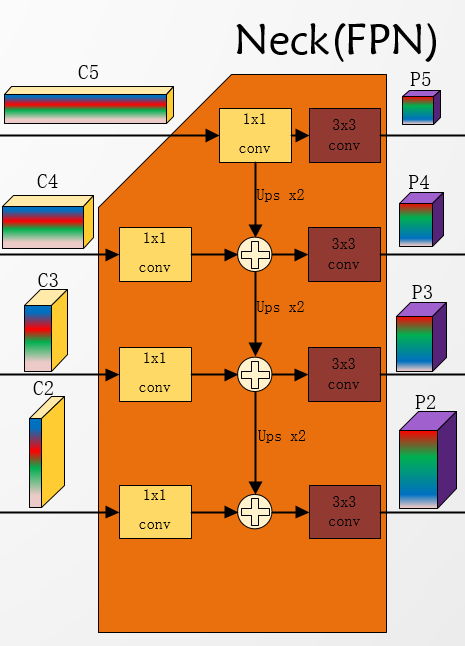
modeling/neck/fpn.py源码解析
首先是在yaml的配置文件:/configs/_base_/models/mask_rcnn_r50_fpn.yml
'''
FPN: #特征金字塔类名
in_channels: [256, 512, 1024, 2048] #FPN输入通道数
out_channel: 256 #FPN输出通道数
min_level: 0 #从0开始 [0,1,2,3]
max_level: 4 #到4结束 [0,1,2,3]
spatial_scale: [0.25, 0.125, 0.0625, 0.03125] #变换尺度
'''相关引用库:
import numpy as np
import paddle
import paddle.nn.functional as F
from paddle import ParamAttr
from paddle.nn import Layer
from paddle.nn import Conv2D
from paddle.nn.initializer import XavierUniform
from paddle.regularizer import L2Decay
from ppdet.core.workspace import register, serializable@register
@serializable
class FPN(Layer):
def __init__(self,
in_channels,
out_channel,
min_level=0,
max_level=4,
spatial_scale=[0.25, 0.125, 0.0625, 0.03125]):
super(FPN, self).__init__()
self.lateral_convs = []
self.fpn_convs = []
fan = out_channel * 3 * 3
for i in range(min_level, max_level):
if i == 3:
lateral_name = 'fpn_inner_res5_sum'
else:
lateral_name = 'fpn_inner_res{}_sum_lateral'.format(i + 2)
in_c = in_channels[i]
lateral = self.add_sublayer(
lateral_name,
Conv2D(
in_channels=in_c,
out_channels=out_channel,
kernel_size=1,
weight_attr=ParamAttr(
initializer=XavierUniform(fan_out=in_c)),
bias_attr=ParamAttr(
learning_rate=2., regularizer=L2Decay(0.))))
self.lateral_convs.append(lateral)
fpn_name = 'fpn_res{}_sum'.format(i + 2)
fpn_conv = self.add_sublayer(
fpn_name,
Conv2D(
in_channels=out_channel,
out_channels=out_channel,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(
initializer=XavierUniform(fan_out=fan)),
bias_attr=ParamAttr(
learning_rate=2., regularizer=L2Decay(0.))))
self.fpn_convs.append(fpn_conv)
self.min_level = min_level
self.max_level = max_level
self.spatial_scale = spatial_scale
def forward(self, body_feats):
laterals = []
for lvl in range(self.min_level, self.max_level):
laterals.append(self.lateral_convs[lvl](body_feats[lvl]))
for i in range(self.min_level + 1, self.max_level):
lvl = self.max_level + self.min_level - i
upsample = F.interpolate(
laterals[lvl],
scale_factor=2.,
mode='nearest', )
laterals[lvl - 1] = laterals[lvl - 1] + upsample
fpn_output = []
for lvl in range(self.min_level, self.max_level):
fpn_output.append(self.fpn_convs[lvl](laterals[lvl]))
extension = F.max_pool2d(fpn_output[-1], 1, stride=2)
spatial_scale = self.spatial_scale + [self.spatial_scale[-1] * 0.5]
fpn_output.append(extension)
return fpn_output, spatial_scaleFPN类,通过特征金字塔结构进行特征融合。















 1256
1256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









