






图像分割–FCN的论文复现(pytorch实现)
1.首先,要对评估图像分割模型性能的指标进行了解。
IOU(Intersection over Union)和ACC(Accuracy)。
IOU是指分割结果与真实分割结果之间的交集与并集之比。在图像分割中,我们通常将每个像素的预测标签与真实标签进行比较,然后计算它们之间的IOU。具体来说,对于每个类别,我们可以计算出它们在分割结果和真实结果中的像素数目,并计算它们之间的交集和并集。然后,我们可以将交集除以并集,得到该类别的IOU。最后,我们可以将所有类别的IOU求平均,得到整个图像的平均IOU。IOU越高,说明分割结果与真实结果越接近,分割性能越好。
ACC是指分割结果中正确分类的像素数与总像素数之比。在图像分割中,我们通常将每个像素的预测标签与真实标签进行比较,然后计算它们之间的正确率。具体来说,我们可以统计分割结果中与真实结果相同的像素数目,然后将它们除以总像素数,得到分割的准确率。ACC越高,说明分割结果中正确分类的像素越多,分割性能越好。
aAcc、mIoU和mAcc是三种常用的图像分割模型指标,用于评估模型在不同类别下的性能表现。
aAcc(Average Accuracy)是指模型在所有类别中的像素分类正确率的平均值。具体来说,对于每个类别,我们可以计算出它们在分割结果和真实结果中的像素数目,然后计算分类正确的像素数目,最后将所有类别的像素分类正确率求平均。aAcc可以用来评估模型整体的分类准确率,但它不能反映出不同类别之间的性能差异。
mIoU(Mean Intersection over Union)是指所有类别的IOU的平均值。在图像分割中,我们通常将每个像素的预测标签与真实标签进行比较,然后计算它们之间的IOU。对于每个类别,我们可以计算出它们在分割结果和真实结果中的像素数目,并计算它们之间的交集和并集。然后,我们可以将交集除以并集,得到该类别的IOU。最后,我们可以将所有类别的IOU求平均,得到整个图像的平均IOU。mIoU可以用来评估模型在不同类别之间的性能差异,越高表示模型在不同类别上的分割性能越好。
mAcc(Mean Accuracy)是指所有类别的像素分类正确率的平均值。具体来说,对于每个类别,我们可以计算出它们在分割结果和真实结果中的像素数目,然后计算分类正确的像素数目。最后,我们可以将所有类别的像素分类正确率求平均,得到整个图像的平均像素分类正确率。mAcc可以用来评估模型在不同类别之间的性能差异,并且能够反映出模型在像素分类方面的整体性能。
1.aAcc可以用来评估模型整体的分类准确率,但它不能反映出不同类别之间的性能差异。
2.mIoU可以用来评估模型在不同类别之间的性能差异,越高表示模型在不同类别上的分割性能越好。
3.mAcc可以用来评估模型在不同类别之间的性能差异,并且能够反映出模型在像素分类方面的整体性能。
2.FCN网络结构讲解
在原论文中的FCN网络backbone部分主要使用了VGG16,而在pytorch的实现中则主要使用了ResNet作为其backbone。
CNN和FCN其两者是有很大的联系的,通常CNN在卷积层之后添加的是若干个全连接层,而FCN则将CNN中的全连接层换成了卷积层。
FCN网络的结构图如下所示:
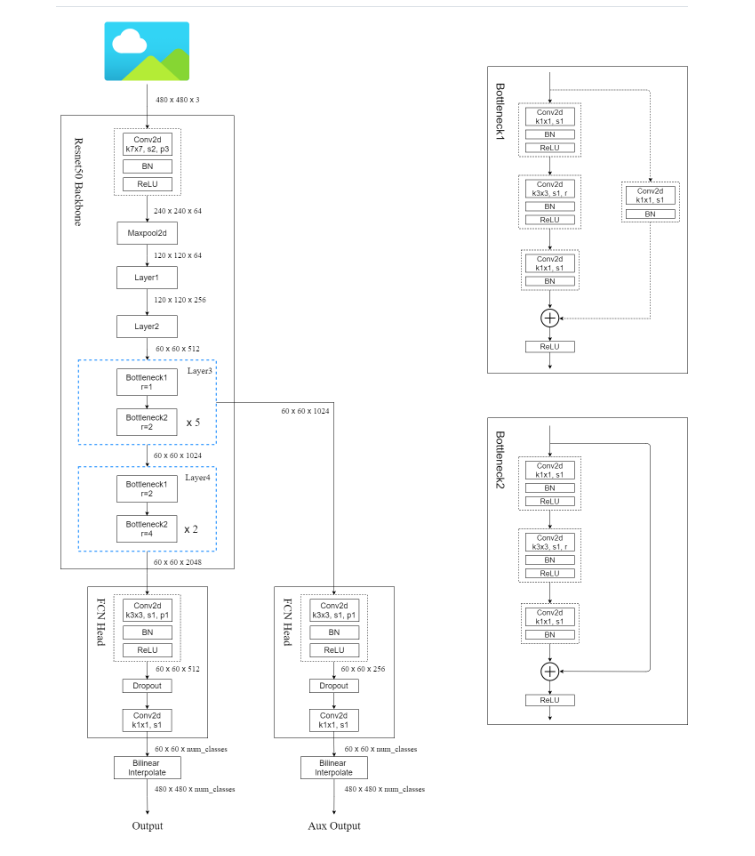
具体的目录机构如下所示:
3.代码实现部分
具体的代码可以查看下面给出的参考链接,在这儿放出一些模型代码如下所示:
在src中是模型所在的部分,backbone是ResNet模型
import torch
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1): # 卷积核大小为3*3
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1): # 卷积核大小为1*1
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
def _resnet(block, layers, **kwargs):
model = ResNet(block, layers, **kwargs)
return model
def resnet50(**kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet(Bottleneck, [3, 4, 6, 3], **kwargs)
def resnet101(**kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet(Bottleneck, [3, 4, 23, 3], **kwargs)
fcn_model则是实现部分
from collections import OrderedDict
from typing import Dict
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from .backbone import resnet50, resnet101
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
# 重新构建backbone,将没有使用到的模块全部删掉
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x: Tensor) -> Dict[str, Tensor]:
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
class FCN(nn.Module):
"""
Implements a Fully-Convolutional Network for semantic segmentation.
Args:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"out" for the last feature map used, and "aux" if an auxiliary classifier
is used.
classifier (nn.Module): module that takes the "out" element returned from
the backbone and returns a dense prediction.
aux_classifier (nn.Module, optional): auxiliary classifier used during training
"""
__constants__ = ['aux_classifier']
def __init__(self, backbone, classifier, aux_classifier=None):
super(FCN, self).__init__()
self.backbone = backbone
self.classifier = classifier
self.aux_classifier = aux_classifier
def forward(self, x: Tensor) -> Dict[str, Tensor]:
input_shape = x.shape[-2:]
# contract: features is a dict of tensors
features = self.backbone(x)
result = OrderedDict()
x = features["out"]
x = self.classifier(x)
# 原论文中虽然使用的是ConvTranspose2d,但权重是冻结的,所以就是一个bilinear插值
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["out"] = x
if self.aux_classifier is not None:
x = features["aux"]
x = self.aux_classifier(x)
# 原论文中虽然使用的是ConvTranspose2d,但权重是冻结的,所以就是一个bilinear插值
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["aux"] = x
return result
class FCNHead(nn.Sequential):
def __init__(self, in_channels, channels):
inter_channels = in_channels // 4
layers = [
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(inter_channels),
nn.ReLU(),
nn.Dropout(0.1),
nn.Conv2d(inter_channels, channels, 1)
]
super(FCNHead, self).__init__(*layers)
def fcn_resnet50(aux, num_classes=21, pretrain_backbone=False):
# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'
# 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth'
backbone = resnet50(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet50 backbone预训练权重
backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = FCNHead(out_inplanes, num_classes)
model = FCN(backbone, classifier, aux_classifier)
return model
def fcn_resnet101(aux, num_classes=21, pretrain_backbone=False):
# 'resnet101_imagenet': 'https://download.pytorch.org/models/resnet101-63fe2227.pth'
# 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth'
backbone = resnet101(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet101 backbone预训练权重
backbone.load_state_dict(torch.load("resnet101.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = FCNHead(out_inplanes, num_classes)
model = FCN(backbone, classifier, aux_classifier)
return model
get_palette.py可以看到图片的调色板信息
import json
import numpy as np
from PIL import Image
import os
print(os.getcwd())
# 读取mask标签
target = Image.open("E:/PostGraduate/Paper_review/computer_view_model/FCN/data/VOC2012/SegmentationClass/2007_001288.png")
# 获取调色板
palette = target.getpalette()
palette = np.reshape(palette, (-1, 3)).tolist()
# 转换成字典子形式
pd = dict((i, color) for i, color in enumerate(palette))
json_str = json.dumps(pd)
with open("palette.json", "w") as f:
f.write(json_str)
# target = np.array(target)
# print(target)
my_dataset.py则是实现对数据进行读取:
import os
import torch.utils.data as data
from PIL import Image
class VOCSegmentation(data.Dataset):
def __init__(self, voc_root, year="2012", transforms=None, txt_name: str = "train.txt"):
super(VOCSegmentation, self).__init__()
assert year in ["2007", "2012"], "year must be in ['2007', '2012']"
root = os.path.join(voc_root, f"VOC{year}")
assert os.path.exists(root), "path '{}' does not exist.".format(root)
image_dir = os.path.join(root, 'JPEGImages') # 将原始图片的链接插入文件目录中
mask_dir = os.path.join(root, 'SegmentationClass') # 要分割的类别列表
txt_path = os.path.join(root, "ImageSets", "Segmentation", txt_name) # 训练的文件夹列表
assert os.path.exists(txt_path), "file '{}' does not exist.".format(txt_path)
with open(os.path.join(txt_path), "r") as f:
file_names = [x.strip() for x in f.readlines() if len(x.strip()) > 0] # 读取文件列表
self.images = [os.path.join(image_dir, x + ".jpg") for x in file_names]
self.masks = [os.path.join(mask_dir, x + ".png") for x in file_names]
assert (len(self.images) == len(self.masks))
self.transforms = transforms
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is the image segmentation.
"""
img = Image.open(self.images[index]).convert('RGB')
target = Image.open(self.masks[index])
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.images)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
# 计算该batch数据中,channel, h, w的最大值
max_size = tuple(max(s) for s in zip(*[img.shape for img in images])) # 取最大的值,对于那些大小不够的要进行0填充
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
# dataset = VOCSegmentation(voc_root="/data/", transforms=get_transform(train=True))
# d1 = dataset[0]
# print(d1)
接下来就是对模型进行训练和验证的部分
import torch
from torch import nn
import train_utils.distrributed_utils as utils
def criterion(inputs, target):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
def evaluate(model, data_loader, device, num_classes):
model.eval()
confmat = utils.ConfusionMatrix(num_classes)
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, 100, header):
image, target = image.to(device), target.to(device)
output = model(image)
output = output['out']
confmat.update(target.flatten(), output.argmax(1).flatten())
confmat.reduce_from_all_processes()
return confmat
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler, print_freq=10, scaler=None):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image, target = image.to(device), target.to(device)
with torch.cuda.amp.autocast(enabled=scaler is not None):
output = model(image)
loss = criterion(output, target)
optimizer.zero_grad()
if scaler is not None:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
metric_logger.update(loss=loss.item(), lr=lr)
return metric_logger.meters["loss"].global_avg, lr
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
import os
import time
import datetime
import torch
from src.fcn_model import fcn_resnet50
from train_utils.train_and_evals import train_one_epoch, evaluate, create_lr_scheduler
from my_dataset import VOCSegmentation
import transforms as T
class SegmentationPresetTrain: # 对输入的图片进行尺寸变换即transform,使模型更具有泛化性,训练集数据
def __init__(self, base_size, crop_size, hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
min_size = int(0.5 * base_size)
max_size = int(2.0 * base_size)
trans = [T.RandomResize(min_size, max_size)]
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
trans.extend([
T.RandomCrop(crop_size), # 随机区域裁剪
T.ToTensor(),
T.Normalize(mean=mean, std=std), # 进行正则化
])
self.transforms = T.Compose(trans) # 对trans里面的内容进行遍历执行
def __call__(self, img, target):
return self.transforms(img, target)
class SegmentationPresetEval: # 对测试集数据进行操作
def __init__(self, base_size, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.RandomResize(base_size, base_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)
def get_transform(train): # 该函数用来调用上述两个类
base_size = 520
crop_size = 480
return SegmentationPresetTrain(base_size, crop_size) if train else SegmentationPresetEval(base_size)
def create_model(aux, num_classes, pretrain=True): # 加载模型
model = fcn_resnet50(aux=aux, num_classes=num_classes)
if pretrain:
weights_dict = torch.load("E:\PostGraduate\Paper_review\computer_view_model\FCN/model_weight/fcn_resnet50_coco.pth", map_location='cpu')
if num_classes != 21:
# 官方提供的预训练权重是21类(包括背景)
# 如果训练自己的数据集,将和类别相关的权重删除,防止权重shape不一致报错
for k in list(weights_dict.keys()):
if "classifier.4" in k:
del weights_dict[k]
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
return model
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
batch_size = args.batch_size
# segmentation nun_classes + background
num_classes = args.num_classes + 1
# 用来保存训练以及验证过程中信息
results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> train.txt
train_dataset = VOCSegmentation(args.data_path,
year="2012",
transforms=get_transform(train=True),
txt_name="train.txt")
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> val.txt
val_dataset = VOCSegmentation(args.data_path,
year="2012",
transforms=get_transform(train=False),
txt_name="val.txt")
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=1,
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
model = create_model(aux=args.aux, num_classes=num_classes)
model.to(device)
params_to_optimize = [
{"params": [p for p in model.backbone.parameters() if p.requires_grad]},
{"params": [p for p in model.classifier.parameters() if p.requires_grad]}
]
if args.aux:
params = [p for p in model.aux_classifier.parameters() if p.requires_grad]
params_to_optimize.append({"params": params, "lr": args.lr * 10})
optimizer = torch.optim.SGD(
params_to_optimize,
lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)
scaler = torch.cuda.amp.GradScaler() if args.amp else None
# 创建学习率更新策略,这里是每个step更新一次(不是每个epoch)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True)
if args.resume:
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
if args.amp:
scaler.load_state_dict(checkpoint["scaler"])
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch,
lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
confmat = evaluate(model, val_loader, device=device, num_classes=num_classes)
val_info = str(confmat)
print(val_info)
# write into txt
with open(results_file, "a") as f:
# 记录每个epoch对应的train_loss、lr以及验证集各指标
train_info = f"[epoch: {epoch}]\n" \
f"train_loss: {mean_loss:.4f}\n" \
f"lr: {lr:.6f}\n"
f.write(train_info + val_info + "\n\n")
save_file = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
"epoch": epoch,
"args": args}
if args.amp:
save_file["scaler"] = scaler.state_dict()
torch.save(save_file, "save_weights/model_{}.pth".format(epoch))
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print("training time {}".format(total_time_str))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch fcn training")
parser.add_argument("--data-path", default="E:\PostGraduate\Paper_review\computer_view_model\FCN/data/", help="VOCdevkit root")
parser.add_argument("--num-classes", default=20, type=int)
parser.add_argument("--aux", default=True, type=bool, help="auxilier loss")
parser.add_argument("--device", default="cuda", help="training device")
parser.add_argument("-b", "--batch-size", default=4, type=int)
parser.add_argument("--epochs", default=30, type=int, metavar="N",
help="number of total epochs to train")
parser.add_argument('--lr', default=0.0001, type=float, help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
main(args)
训练数据的获取Resnet预训练参数的获取都可以参考下面给出的代码链接中找到。
参考链接:
[图像分割模型性能的指标IOU与ACC_分割iou-CSDN博客](https://blog.csdn.net/qq_44089890/article/details/130442000#:~:text=IOU是指分割结果与真实分割结果之间的交集与并集之比。,在图像分割中,我们通常将每个像素的预测标签与真实标签进行比较,然后计算它们之间的IOU。 具体来说,对于每个类别,我们可以计算出它们在分割结果和真实结果中的像素数目,并计算它们之间的交集和并集。)
etavar=‘N’,
help=‘start epoch’)
# Mixed precision training parameters
parser.add_argument(“–amp”, default=False, type=bool,
help=“Use torch.cuda.amp for mixed precision training”)
args = parser.parse_args()
return args
if name == ‘main’:
args = parse_args()
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
main(args)
训练数据的获取Resnet预训练参数的获取都可以参考下面给出的代码链接中找到。
参考链接:
[图像分割模型性能的指标IOU与ACC_分割iou-CSDN博客](https://blog.csdn.net/qq_44089890/article/details/130442000#:~:text=IOU是指分割结果与真实分割结果之间的交集与并集之比。,在图像分割中,我们通常将每个像素的预测标签与真实标签进行比较,然后计算它们之间的IOU。 具体来说,对于每个类别,我们可以计算出它们在分割结果和真实结果中的像素数目,并计算它们之间的交集和并集。)
[全卷积网络 FCN 详解 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/30195134)
[deep-learning-for-image-processing/pytorch_segmentation/fcn/src/fcn_model.py at bf4384bfc14e295fdbdc967d6b5093cce0bead17 · WZMIAOMIAO/deep-learning-for-image-processing (github.com)](https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/bf4384bfc14e295fdbdc967d6b5093cce0bead17/pytorch_segmentation/fcn/src/fcn_model.py)
















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









