








1.问题是对于v1/v2版本中的tx、ty的限制
2.GIoU:优化无重叠情况下的无法优化
3.DIoU:考虑两个网格之间的中心坐标的距离信息
4.CIoU:考虑形状信息

大特征图中保留到的局部细节特征往上传,可以优化对小目标的检测效果
浅层特征:较强的位置信息以及较弱的语义信息
深层特征:较强的语义信息以及较弱的位置信息
语义信息对于解决分类问题是有利的,定位信息对于解决框的回归问题是有利的,利用FPN以及PAN模块逐步将两者融合,从而使特征层得到较强的语义信息以及位置信息,可以更好的处理分类以及回归问题
解释了为什么YOLOV4/V5可以优化小目标检测较差的问题
提取特征能力更强,同时也提升了网络对大目标的检测能力
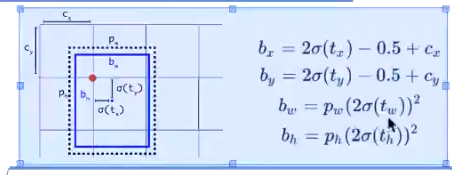
V5中回归坐标编码格式

正中心例外《当前网格就行,上下左右都不在需要 》
左上的范围是【0,1.5】《理想下的状况是【1,1.5】》 右下的范围是【-0.5,0】
宽和高的回归其放缩比在0到4倍之间,即先验框的大小与真实框的大小在四倍差距之间才使用该先验框做为正样本进行预测,缩放范围介于[1/4,4]之间

由于小目标不易检测,所以增大小目标的置信度权值
YOLOV4: PANet + FPN 增加特征融合能力
CSPNet 提升特征融合能力(灵感来源于DenseNet)
Yolov3中的残差用在了主干网络中,concat用在了FPN模块中
yolov4中主干网络中的即用到了add,又结合CSPNet用到了concat,concat同样用在了PANnet中,代替了原始的PANet中的add



**新的激活函数:Mish
relu的负半轴存在稀疏激活性的缺陷,导致参数无法得到更新**


关于激活函数的改进方法:
sigmoid,tanh,relu
最常用的是relu:速度快,梯度大,但是其负半轴同样存在缺陷
为啥不用sigmoid?:训练慢,会出现饱和现象造成梯度的消失(当然有了BN之后这个问题不再重要了,可以将输入数据的范围控制到【-1,1】之间,在这个区间中,激活函数的梯度是很大的),x的不同其梯度值大小不同,即梯度不稳定。
sigmoid的优点:我们加激活函数就是为了提升网络的非线性能力,让网络可以学习到更复杂的特征表示,sigmoid对比relu而言,明显其非线性能力更强(e的x次方求导是不变的,在高维度空间中也一样),理论上是可以学习到更复杂的特征表示的。
由于relu的非线性能力较弱,所以我们需要用到很多的网络层提升其非线性的能力,所以为什么resnet、densenet等这些网络都需要设计的很深。优点:快(梯度大)、稳(梯度是不变的),高维空间时其非线性能力会消失
由上述分析可得:relu与sigmoid的优缺点刚好是互补的,因为有人提出办法将sigmoid与relu激活函数进行融合,以及tanh和relu进行结合,发现了新大陆,朝着复合函数的方向进行发展
损失函数的改进:

MAE优点:梯度稳定,损失下降就很稳定,不会出现梯度爆炸或者是梯度消失的情况,缺点就是在0的时候哪一点不可导,类似于relu一样,但是在激活函数那一块人为的定义哪一点的导数为0,但是损失函数不可以这样定义。
MSE:连续平滑,处处可到,缺点就是随着x的增大,其梯度值不断增大,会出现梯度爆炸的情况出现,当x非常小时,其梯度值也很小,训练速度也会变慢
smooth l1:融合MAE和MSE的优缺点,当x较小时,用mse代替,可以避免哪一个不可导点的情况出现,当x较大值,用MAE代替,梯度稳定,避免了梯度爆炸的情况出现
**IoU损失的问题:
仅仅提供了衡量面积大小的情况,并没有指出框该往哪个方向回归
V3中计算置信度用到的是IoU,其损失函数还是使用的MSE损失,为了均衡不同大小的框之间的损失,对wh加了根号**

GIOU:
图3中的黄框优于图3中的黄框,从图2至图3明显状态在变好,但是损失却没变


并集越接近于外接矩形越好,提供了一个优化的方向
GIOU的缺陷:

无法优化一种框包含了另一种框在内部的情况,状态123的GIOU损失都是相等的,抛弃iou不谈的情况下,先根据v3的损失公式来看,状态2只需要调整wh,而状态1和3还需要调整中心点偏移量的大小
DIOU损失: 不仅仅可以解决大框套小框时损失不变的情况,同样有giou中的效果。

考虑1:极端情况下两种框的损失
考虑2:

为什么要除最小外接矩形框之间的对角线距离:起到归一化的作用
DIoU损失的缺陷:

在上述3种情况中,3种diou都相等,但是从图中看起来状态2的形状要接近于真实框
CIoU损失:考虑形状的相似度,即夹角的相似度

P代表的是标签,gt代表的是真实wh,不是先验框的wh

求arc相当于求这个夹角值

NMS环节:

既然CIoU损失是最好的,那为什么不用CIoU?而用DIoU
CIoU中需要使用预测框的wh以及需用用到标签的wh,但是在预测环节只有预测的结果
DIoU NMS有一定的效果,其实和NMS的差别不是很大,在训练中已经淘汰了一批不合格的框


CSPNet意义何在:稠密网络带来的信息的流通性更好?,降低计算瓶颈:缓和了梯度消失的问题
训练tricks(yolov4最大的得益之处)
监督------>监督+自监督<自对抗训练>
完整的数据以及残差不全的数据,当网络使用残差不全的数据时,其标签与完整数据的标签是一致的,迫使网络提取跟标签相关的特征,根据部分特征来对整体进行预测,其作用其实类似于drop-block,对特征图进行dropout(普通的dropout是作用于权重上的,让部分权重随机失活),避免过拟合,随机舍弃部分特征
1.cutout 随机对某一部分进行遮挡,训练时仅对浅层起作用,网络层数较深时特征已经通过特征提取得到了恢复
(丢弃区域的大小不好确定,不可以过大也不可以过小,当丢弃区域过大时反而导致网络去学习背景特征,导致网络带来退化)
2.drop-block 对特征图进行随机丢弃
(争论drop作用于权重和输入上所带来的效果为什么不一样呢?)

YOLOV5的名称争议是巨大的,YOLOV4改进了V3中很多的缺陷,但是V5网络中仅仅提出了一个新的Fcous,灌水严重。。。。
YOLOV5中网络结构的2个超参数配置:一个是网络的深度,一个是网络的宽度,2种不同的组合构成不同的模型名称
自适应锚框:在v3中,anchors的大小首先由kmeans算法得到之后就固定不变了
图片自适应缩放:提升检测速度

(建议不使用,哪怕是有效的,但是速度也会非常的慢)
问题:对于原始图片很大,但是其中的目标较小,若强行将图片缩放到416416会导致小目标的特征变得很小甚至消失
解决办法:对原始图片进行切分,将图片切分成416416,但是切的时候一定要注意gt目标一定不能够被1分为2,否则很容易就检测不到了。














 5040
5040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









