









原论文:NIPS2020 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
背景知识
图像处理、立体视觉等方向常常涉及到四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系。重点是掌握这几个坐标系的转换。也就是说,一个现实中的点是如何在图像中成像的。
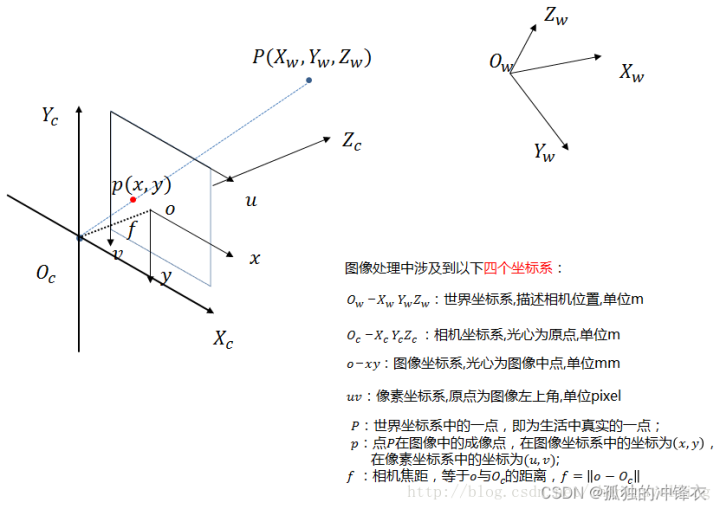
世界坐标系:绝对坐标系,它以现实世界空间中的某一点为坐标原点 ,以便描述现实空间中任意一个物体(如相机)的位置,单位为米(m)
相机坐标系:原点为光心 ,单位为米(m)
图像坐标系:原点为图像中心,单位为毫米(mm)
像素坐标系:原点在图像坐标系的左上角,单位为像素(pixel)
-
世界坐标系到相机坐标系(刚体变换)
设世界坐标系中有一点 ,设该点在相机坐标系中的坐标为
。从图像坐标系到相机坐标系涉及到点P绕着
轴的旋转以及沿着这三个轴的平移变换,设旋转变换矩阵为
,沿各轴的平移量分别为
,则有:
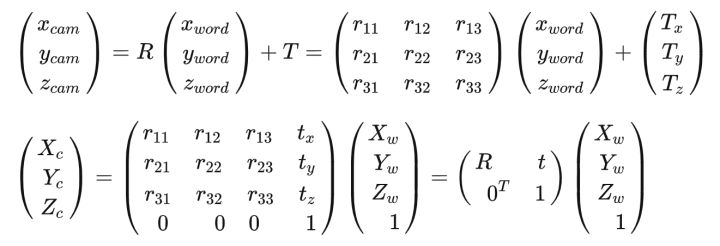
-
相机坐标系到图像坐标系(3D->2D,透视投影)
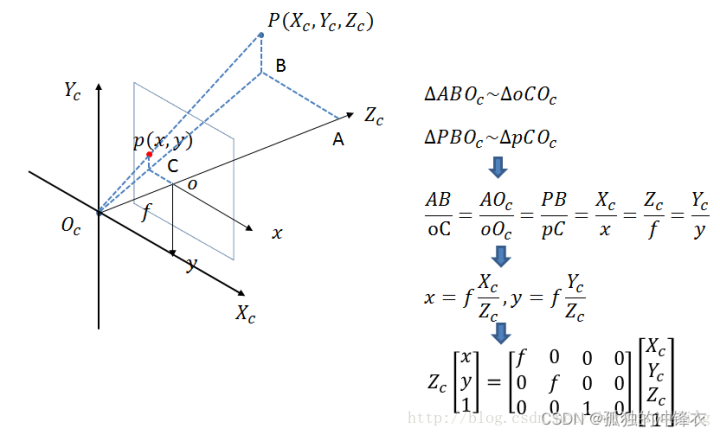
-
图像坐标系到像素坐标系(变换原点位置)
一般认为
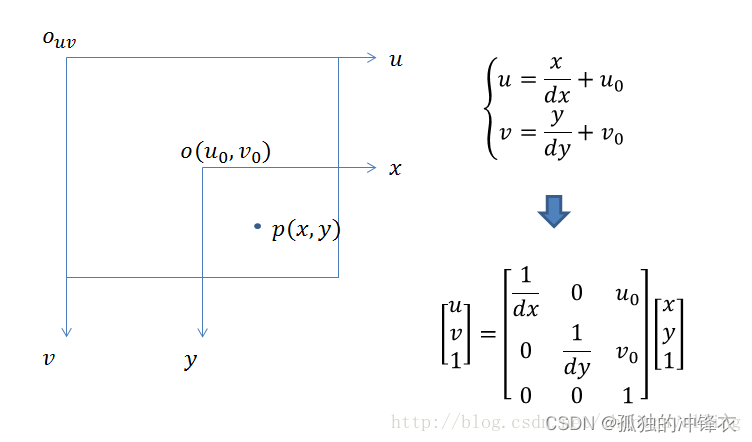
-
总体变换流程

Summary
-
NeRF是一种隐式的场景表示,因为我们不能像点云、mesh、voxel一样直接看见一个三维模型。
-
NeRF是Neural Radiance Fields的缩写。其中的Radiance Fields是指一个映射
,可以将输入的空间点位置信息以及观测角度
映射为该点的颜色及密度
,我们可以认为这样的映射是对三维场景的隐式表示。之所以称之为Neural Radiance Fields是因为该模型中的radiance field是用神经网络拟合的一种映射。
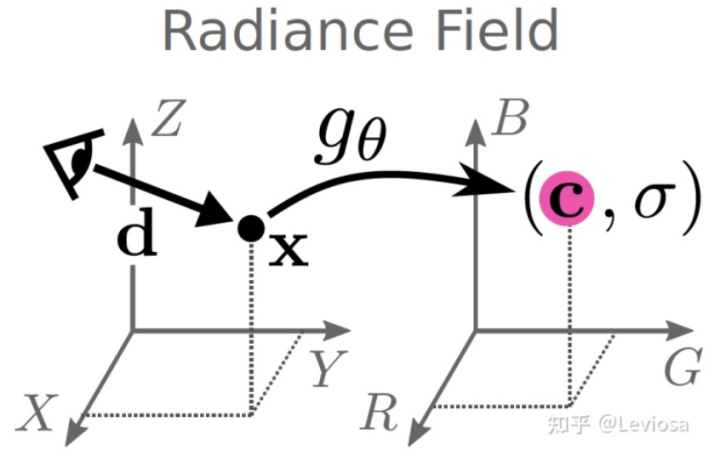
-
有了以NeRF形式存在的场景表示后,可以对该场景进行渲染,生成新视角的模拟图片。论文使用经典体积渲染(volume rendering)的原理,求解穿过场景的任何光线的颜色,从而渲染新的图像。要想渲染一张完整的图片,就需要为通过虚拟相机成像平面的每个像素的光线计算一个积分,得到该像素的颜色值。
-
下面是计算某个光线对应颜色值的积分形式公式:
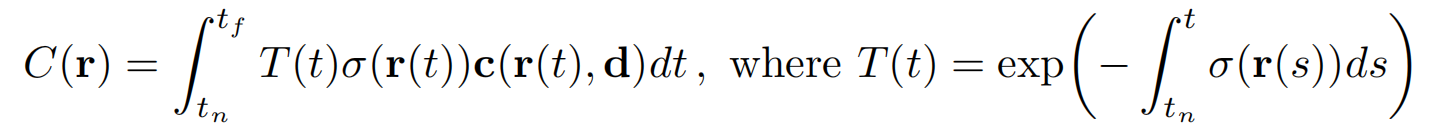
-
T(t) 是从 tn 到 t 的累计透射率,也就是光线从 tn 传播到t而没有碰到任何其他粒子(仍存活)的概率; σ(r(t)) 是射线在位置 r(t) 处的无穷小粒子处终止的微分概率,可以简单认为是微粒的密度或不透明度。
-
使用计算机求积分,必然是离散的采样(黎曼和),作者采用分层抽样(stratified sampling)对这个连续积分进行数值估计。原因:如果是仅仅固定地采用每个小区间的端点或者中点作为该区间的代表值,那么即使视角无限多,每个视角拍摄的图片也无限多,所利用的也仅仅是三维空间中固定的那些离散点(导致优化时只优化有限个固定点,而其他位置处的点均未学到场景的3D特征),并不能充分利用三维空间信息,即丧失了NeRF是连续空间表征的特点。分层采样:先将首尾总区间等距划分为 N 个小区间,然后在每个小区间内进行随机采样,采样出的代表点服从该小区间上的均匀分布。这样的话,只要视角和每个视角下的光线无限多,即可完全利用三维空间中每个点的 RGBσ 信息。
离散化公式推导
我们将区间划分为
个子区间,其中第
个区间为
。在每个子区间内随机采样一个代表点
,则有
。 我们用“积分的和”近似“和的积分”,即:

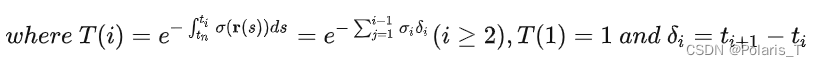
解释: T(i) 是从 tn 到 ti 的累计透射率,其离散表达式的由来和"用小矩形面积之和去近似某函数与x轴围成的区域面积"是一个道理, ci 是 ti 处的 RGB 值, σi 是 ti 处的volumn density, δi 是微小区间 [ti,ti+1] 的长度。
Tricks
位置编码(positional encoding):利用高频函数将低维输入映射到高维空间,提升网络捕捉高频信息的能力。由于网络很难学到一个从低频到高频的映射(实际上网络倾向于学习低频特征),因此如果使用原始的 XYZϕθ 坐标作为输入,则会导致网络很难学到高频细节(颜色、纹理、质地、光照)等信息。
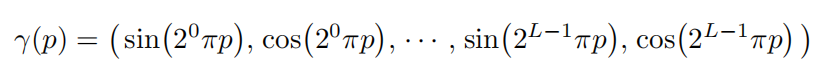
这里若取 L=10 ,则输入数据的维度为 2×10×3=60 维。
-
体积渲染的分层采样:coarse network采样64个点,先粗糙地渲染一遍结果图,并优化coarse network,然后根据这64个采样点的volunm density的分布再次精细采样出128个点,将粗采样+细采样的点输入fine network进行精细渲染并优化fine network。
-
合理的积分离散化采样:通过更高效的采样策略减小估算积分式的计算开销,加快训练速度,并且保证空间的中的绝大多数点都能被优化到,而非只优化某些固定的点(若使用每个小区间的左端点作为代表点的话)。
实验结果
定量比较:

视角合成效果:


Pros & Cons
-
隐式表示的好处是它一种连续的表示,能够适用于大分辨率场景,而且通常不需要3D信号进行监督。
-
相比SNR、NV、LLFF而言,NeRF能够渲染出高频细节信息、高分辨率图像,对输入的视图之间相差的像素个数不做要求,模型内存占用很小(10MB)。
-
多视角一致性:一点处的 σ 只与坐标有关,保证无论从什么方向看过去,该点的不透明度都一样,而仅是颜色不一样(view-dependent,由于光照等因素)

部分代码解释
要求出相机坐标系下的rays_d,其实就是求成像面上这 H×W 个点在相机坐标系下的坐标(因为光线源点就是光心 Oc ),因此也就是为什么源码中写:
dirs=np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)
# K = [[f, 0, W/2],
# [0, f, H/2],
# [0, 0, 1]]此外,个人猜测这边相机内参矩阵直接用的是f而非f_x, f_y是为了简化计算,认为1pixel=1mm,也即认为 dx=dy=1 了。
为什么相机坐标的 Y 和 Z 前面有负号?
因为COLMAP采用的是opencv定义的相机坐标系统,其中x轴向右,y轴向下,z轴向内;而nerf-pytorch采用的是OpenGL定义的相机坐标系统,其中x轴向右,y轴向上,z轴向外。因此需要在y与z轴进行相反数转换。
在给定世界坐标系的条件下,若已知相机位姿(光心在世界坐标系下的位置,相机朝向的方向向量),则可以求出相机外参矩阵,再次求逆即可得到源码中使用的cam2world矩阵。
由于NeRF使用的是posed images,也就是说每个图都已知拍摄它的相机的位姿,因此我们可以直接使用数据集中给出的位姿矩阵(cam2world矩阵,但似乎不同于外参)去进行相机坐标到世界坐标的变换。
rays_d=np.sum(dirs[..., np.newaxis, :] *c2w[:3,:3], -1) # viewing direction is normalized rays_d
rays_o=np.broadcast_to(c2w[:3,-1], np.shape(rays_d))注意:生成式NeRF模型(比如pi-GAN),由于未使用posed images,因此我们无法直接利用cam2world矩阵实现相机->世界坐标的变换,而是要经过如下的步骤:设定世界坐标系原点为 (0,0,0) ,在以 Ow 为圆心的半径为1m的球面上随机采样一个点作为相机光心位置(同时可得 θ,ϕ );利用相机位姿信息求出cam2world矩阵;将相机坐标系中的点的坐标左乘cam2world转换为世界坐标系下的坐标。
关于NeRF+GAN的论文分享将在后续进行更新~
















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











