







文章目录
Multiscale Unsupervised Retinal Edema Area Segmentation in OCT Images
摘要
- 提出了一种新的无监督分割框架
- 该框架由两个阶段组成:图像级聚类将图像分为不同的类别,像素级分割利用聚类网络的指导
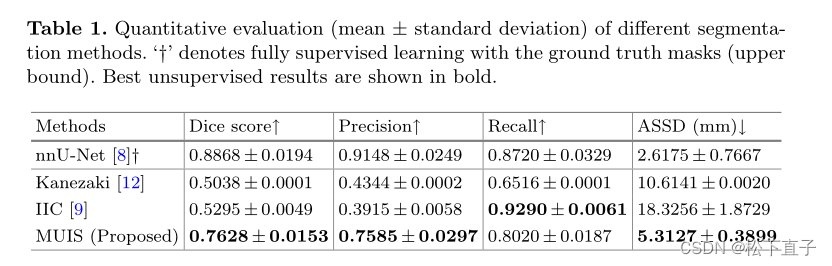
- 基于观察到较小的病变在具有详细纹理信息的大尺度图像上更明显,而较大的病变在大视场的小尺度图像上则更容易捕获,我们分别通过尺度不变正则化和多尺度类激活图(CAM)融合策略将多尺度信息引入这两个阶段。在公共视网膜数据集上的实验表明,所提出的框架在没有任何监督的情况下获得了76.28%的Dice分数,这大大优于最先进的无监督方法(Dice分数提高了20%以上)
代码链接
本文方法
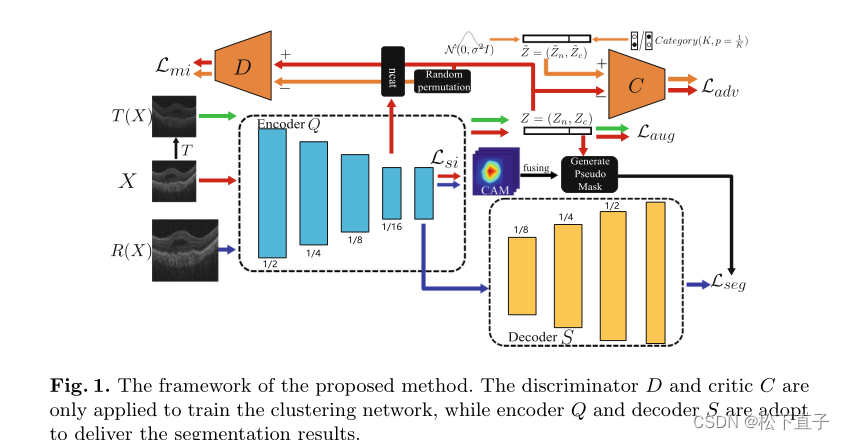
第一步,采用了最先进的深度聚类,使用类别风格表示(DCCS)方法作为骨干方法来训练聚类网络,包括鉴别器D、评论家C和编码器Q。尽管DCCS在自然图像方面具有优异的性能,但它过于关注全局模式,而正常和异常OCT扫描的差异更为局部。通过引入尺度不变正则化,网络可以获得更好的局部差异判别能力。
然后,在通过融合不同尺度的CAM获得的伪掩模的指导下,编码器Q和解码器S可以被优化以提供REA的逐像素分割。
原始的DCCS
给定输入图像X,DCCS旨在学习解耦的潜在表示Z=(Zc,Zs),其中类别向量Zc表示将X分配给每个类别的概率,风格向量Zs表示类内风格信息。引入了三个正则化项,包括互信息正则化、解耦正则化和先验分布正则化,以训练用于这种变换的适当编码器Q。
互信息正则化
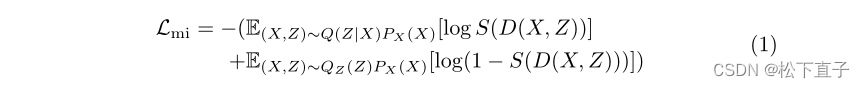
解耦正则化
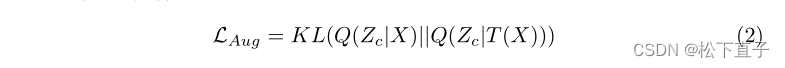
额外的损失正则化
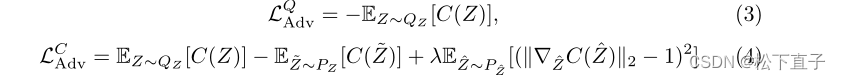
无监督图像聚类
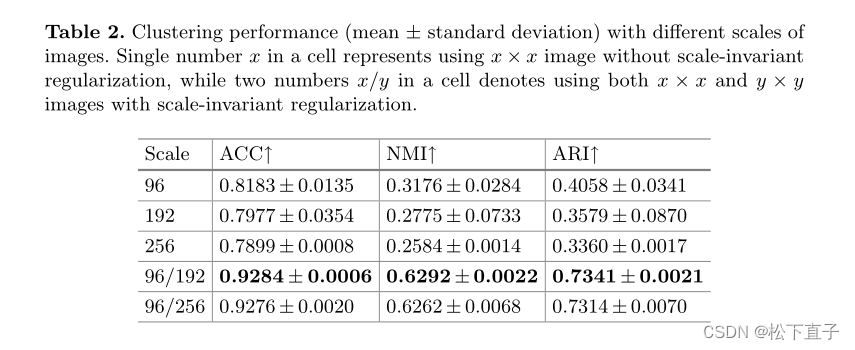
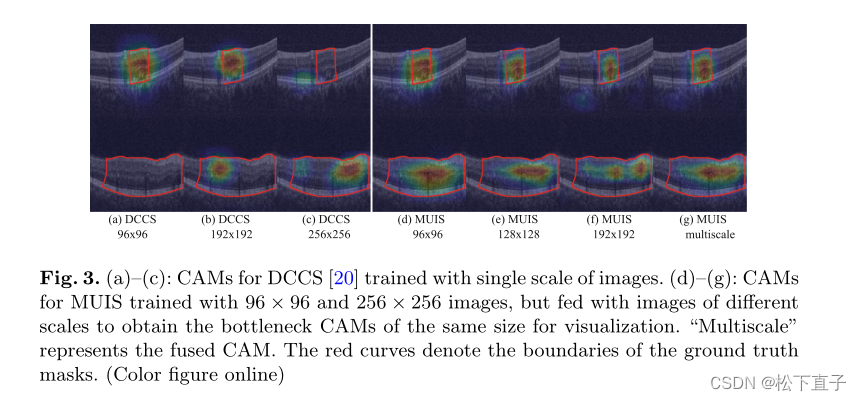
为了进一步提高聚类网络的准确性和鲁棒性,我们建议利用多尺度信息,假设不同图像尺度可以更好地捕捉不同大小的病变,即小病变的细节纹理信息在大尺度图像上更明显,而大的病变更容易用小尺度图像捕获,因为相对大的视场使得卷积核能够覆盖大部分(如果不是全部的话)病变区域
尺度不变正则化,以确保来自不同尺度的同一图像的CAM的一致性,其定义为:
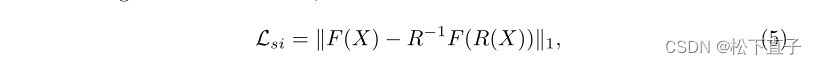
F:特征图
R:rescale操作

Pseudo-Mask-Guided Pixel-Wise Segmentation
在逐像素分割阶段,一旦训练了聚类模型,就可以使用编码器Q的瓶颈特征来生成伪掩码。
为了获得用于优化分割解码器S的更精确的伪掩码,我们进一步利用多尺度信息来获得自适应的CAM。如果我们用M来表示CAM,那么可以通过融合不同尺度的CAM来获得适配的CAM
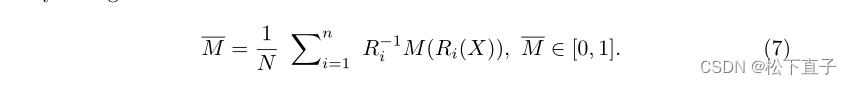
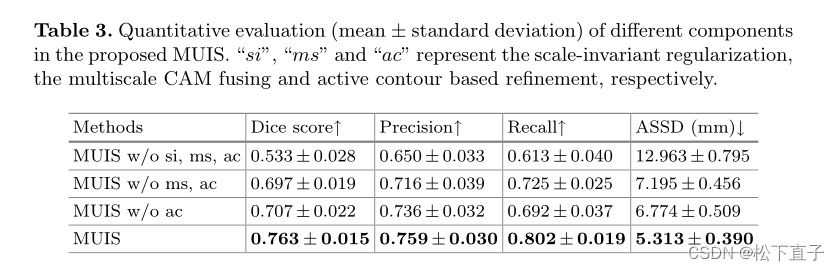
通过阈值化(根据经验设置为0.5)进一步对自适应的CAM进行二值化,并通过主动轮廓模型(active contour model)进行细化作为伪标签

实验结果

















 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











