







文章目录
Leveraging Hidden Positives for Unsupervised Semantic Segmentation
摘要
对标记像素级注释的人力的巨大需求引发了无监督语义分割的出现。尽管最近使用视觉转换器(ViT)主干的工作显示出了卓越的性能,但仍然缺乏对特定任务的训练指导和局部语义一致性的考虑。
本文方法
- 通过挖掘隐藏的正例因素来利用对比学习来学习丰富的语义关系,并确保局部区域的语义一致性。
- 首先基于固定的预训练主干和训练中的分割头分别定义的特征相似性,为每个锚点发现两种类型的全局隐藏正例因素,即任务无关和任务特定。后者的贡献逐渐增加,导致模型捕捉特定于任务的语义特征
- 引入了一种梯度传播策略来学习相邻patch之间的语义一致性,前提是相邻补丁极有可能拥有相同的语义。
- 具体来说,我们将传播到局部隐藏阳性、语义相似的附近补丁的损失与预定义的相似性分数成比例。
代码地址
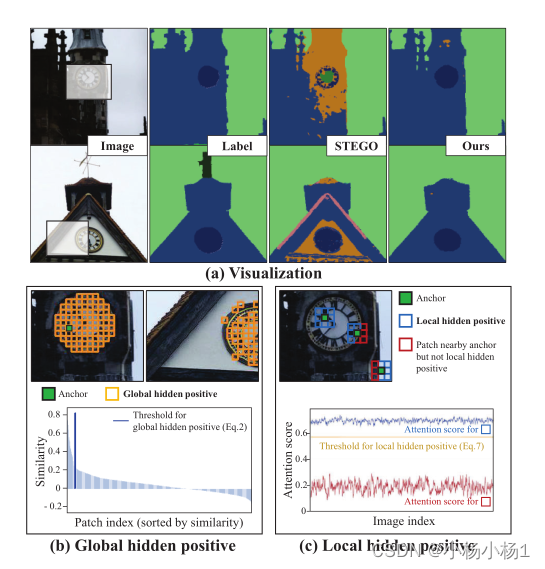
假设一个小批量包括(a)中所示的两个图像,我们描述了两种类型的隐藏正例因素,以用于对比学习。
(a) 通过在(b)和(c)中引入两种类型的隐藏积极因素,我们提供了一个例子,说明我们的训练方案如何提供更精确和一致的语义。(b) (顶部)整个小批量中语义相似的补丁被选为全局隐藏正例。(底部)每个锚点的数据驱动标准是为可靠的正向收集而设计的。根据该标准,所选正例如(b顶部)所示。
(c) (顶部)我们将每个锚点的局部隐藏正例定义为具有高语义一致性的相邻补丁,即蓝框。(底部)来自预训练的转换器架构的相邻patch的平均注意力得分。蓝线表示局部隐藏正例的注意力得分,而红线表示与锚相邻但语义一致性低的补丁。
本文方法
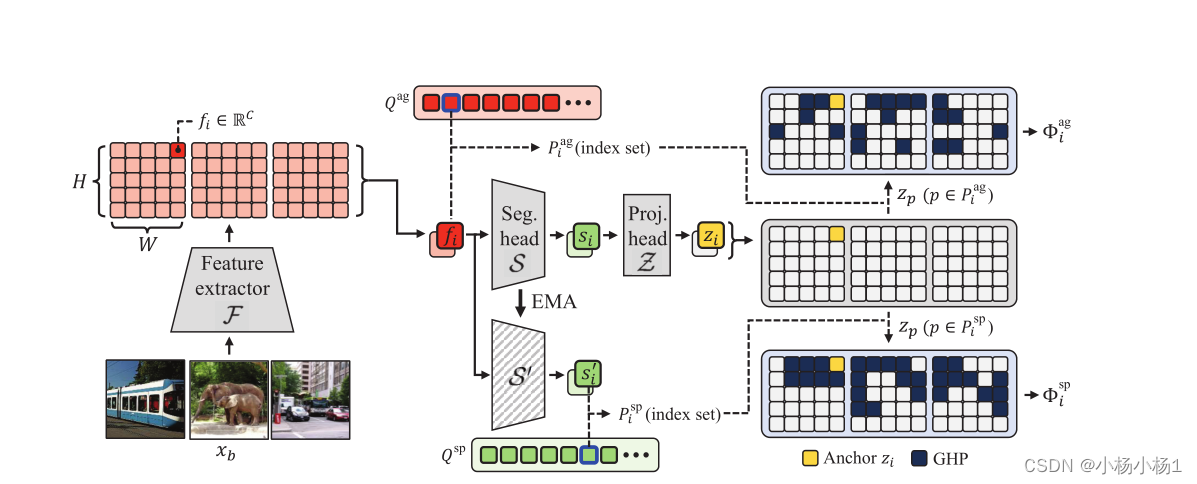
图2:global hidden positive(GHP)选择过程的说明。
我们的GHP可以分为两个子集:任务不可知论和任务特定论。
任务不可知GHP的Pag的索引集包括在任务不可知参考池Qag内发现的阳性的索引。
注意,Qag由特征提取器F提取的随机采样特征组成。
一旦锚特征fi被投影到zi,如果小批量中的其他patch与锚特征的相似性超过了锚与Qag中最相似特征之间的相似性,则它们被收集为阳性。
另一方面,以类似的方式发现了任务特定的GHP,但具有任务特定的参考池Qsp,该参考池不断用动量分割头S的特征更新。
尽管任务不可知的GHP集合只对初始训练有贡献,但特定任务的GHP集逐渐取代任务不可知集合的部分,直到训练结束。
一旦收集了参考池,对于每个补丁特征fi,我们定义了一个依赖于锚的相似性标准ci以收集阳性,作为到参考池内最近的特征的距离Qag乘以余弦相似度:
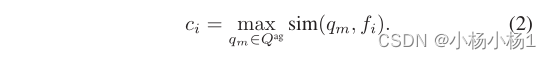
对于每个锚特征fi,如果fi和fj之间的相似性大于ci,我们基本上将小批量fj中的另一个特征视为正特征。尽管一个补丁特征可能是另一个的正样本,但它可能并不相互支持。这是因为ci的标准是锚定的。为了在训练中赋予一致性,我们使GHP选择对称,以防止两个补丁之间的关系不明确。因此,每个第i个锚特征fi的GHP P ag i的索引集定义如下:
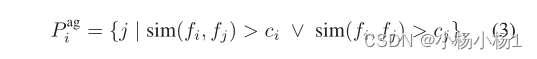
然而,尽管建立在无监督预训练网络特征基础上的参考库可以作为积极性的适当基础,但它可能是不够的,因为它缺乏任务特异性。我们认为,来自分割头部的特征比来自预训练主干的特征更具任务特异性。因此,除了由P ag选择的GHP之外,我们还利用分割头的特征构建了额外的任务专用GHP。
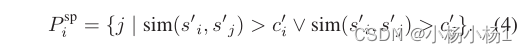
目标函数
为了与挖掘的GHP形成对比目标,我们还需要负面特征。当我们在整个小批量中收集积极因素时,对比学习的实现将利用除了小批量中选择的积极因素之外的所有特征作为消极因素。然而,由于负集大小的过度增加可能会干扰模型训练,我们通过为每个第i个锚随机选择剩余补丁的ρ%来形成负集Ni。
我们对每个第i个锚的对比损失更像是监督目标,因为我们得到了多个正例:
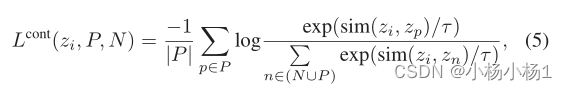
Gradient Propagation to Local Hidden Positives
除了全局考虑语义相似的特征外,常见的假设是附近的像素极有可能属于同一语义类。为此,我们通过将损失梯度传播到锚的周围特征来考虑局部性的性质。尽管如此,传播应该谨慎设计,因为没有给出相邻补丁的语义标签;相邻补丁之间的语义一致性大多成立,但有时不成立(即,在对象边界)。因此,为了决定附近的语义一致的补丁,我们利用来自无监督预训练的ViT主干F的注意力得分。
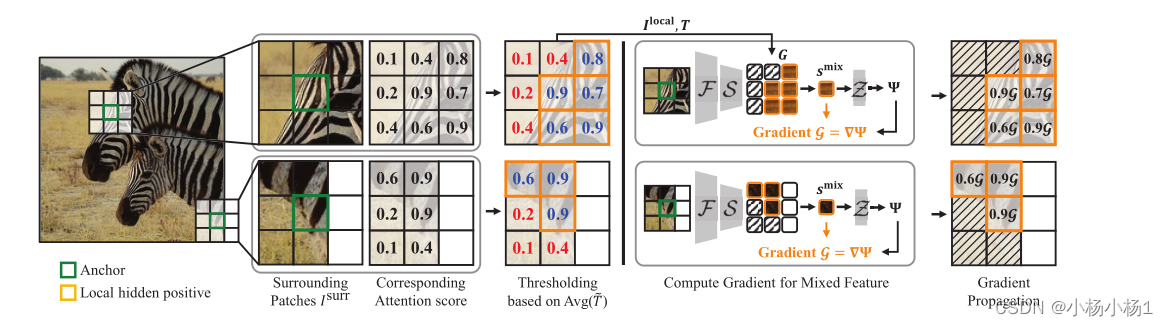
梯度传播策略以保持局部语义一致性。对于每个锚,利用其周围的补丁Isurr和来自特征提取器F的相应注意力分数,基于阈值Avg(~T)指定局部隐藏阳性(LHP)Ilocal(等式7)。在前向传递中,根据注意力得分T,通过加权平均混合LHP G(等式8)的特征,以计算目标函数Ψ。以这种方式,损失梯度在后向通路中与T成比例地向LHP传播。
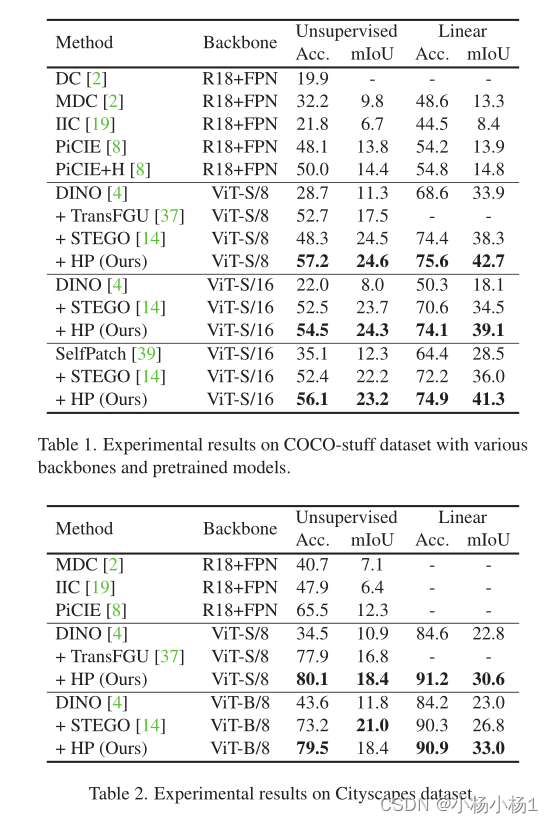
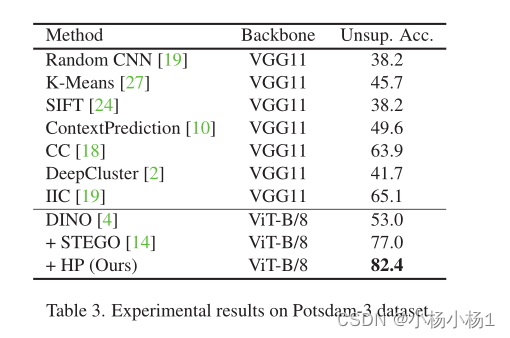
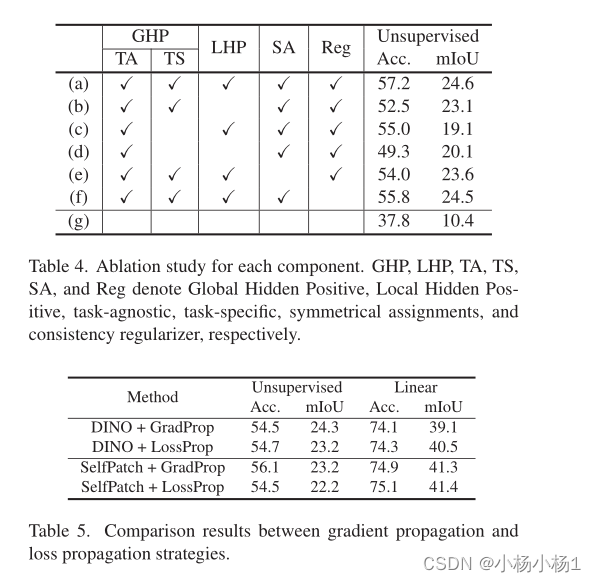
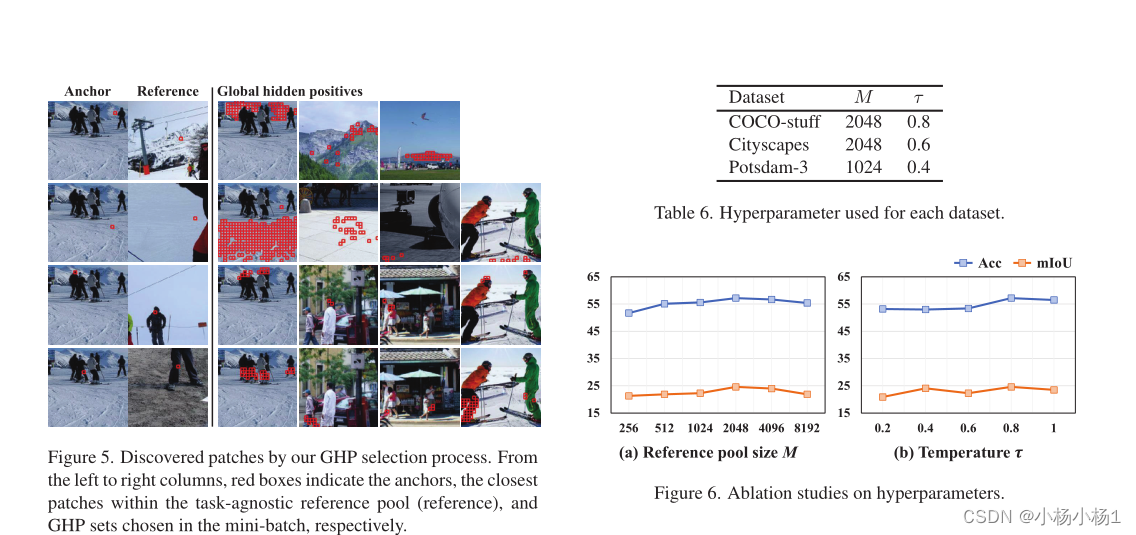
实验结果
















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











