







 文章介绍了MedViT,一个结合CNN和Transformer的模型,旨在提升医疗图像分类的鲁棒性。通过引入局部前馈网络和特定的块设计,如LTB和ECB,模型能有效捕捉长期和短期依赖,同时增强对抗攻击的抵抗力。MedViT还在MedMNIST数据集上进行了实验,展示其性能和对抗性优势。
文章介绍了MedViT,一个结合CNN和Transformer的模型,旨在提升医疗图像分类的鲁棒性。通过引入局部前馈网络和特定的块设计,如LTB和ECB,模型能有效捕捉长期和短期依赖,同时增强对抗攻击的抵抗力。MedViT还在MedMNIST数据集上进行了实验,展示其性能和对抗性优势。
文章目录
MedViT: A Robust Vision Transformer for Generalized Medical Image Classification
摘要
卷积神经网络(cnn)在现有医疗系统的自动疾病诊断方面取得了进步。然而,由于不准确的诊断可能会导致安全领域的灾难性后果,因此仍然存在对深度医疗诊断系统抵御对抗性攻击潜在威胁的可靠性的担忧。
本文方法
- 提出了一个高度鲁棒且高效的CNN-Transformer混合模型,该模型具有cnn的局域性以及视觉transformer的全局连通性。
- 为了缓解自注意机制在共同关注不同表示子空间信息时的高二次复杂度,我们采用高效的卷积运算来构建自注意机制
- 为了减轻Transformer模型对对抗性攻击的脆弱性,我们尝试学习更平滑的决策边界。为此,我们通过在小批量中排列特征均值和方差来增强图像在高级特征空间中的形状信息。
代码地址
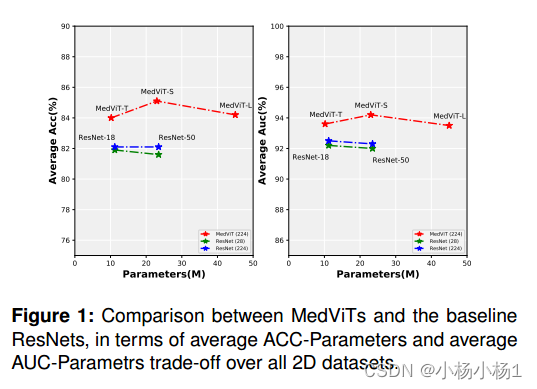
MedViTs与基线ResNets在所有2D数据集的平均acc参数和平均auc参数权衡方面的比较
本文方法
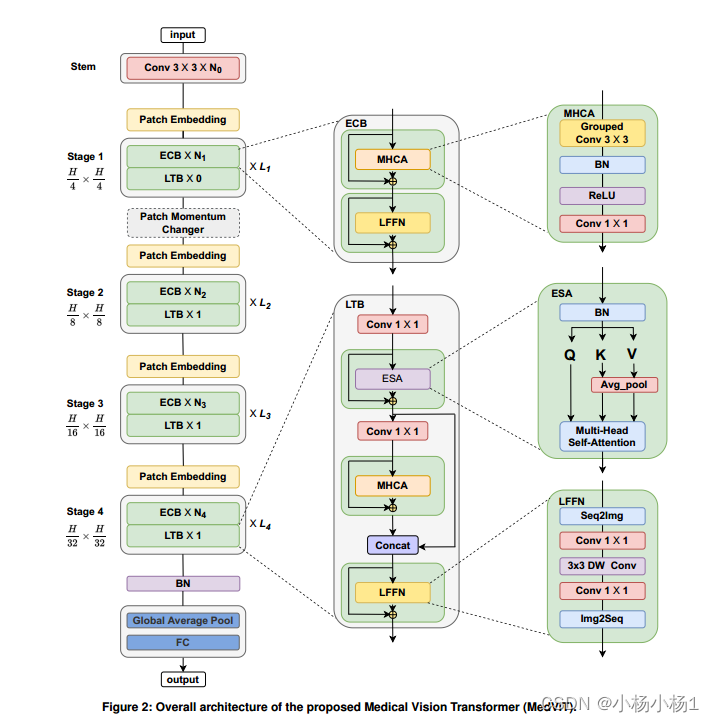
MedViT由一个补丁嵌入层、Transformer块和每一阶段的一系列叠加卷积组成,遵循传统的分层金字塔架构。
空间分辨率将以[4x, 2x, 2x, 2x]的比例以32x的比例逐渐降低,而通道尺寸将在每一阶段经过卷积块后增加一倍。
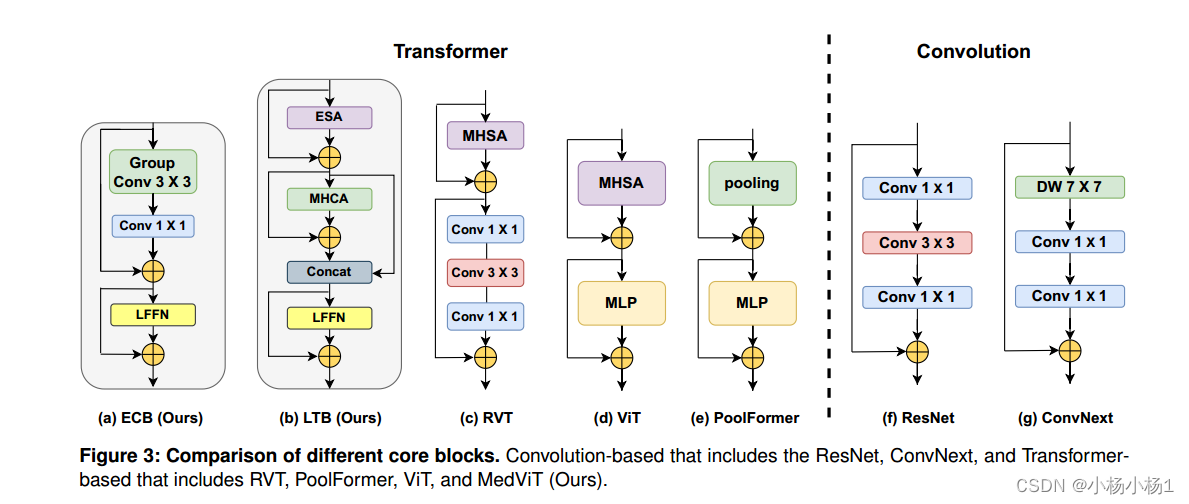
嵌入多尺度上下文的核心块,并分别开发健壮的LTB和ECB,以有效地捕获输入数据中的长期和短期依赖关系
LTB还执行局部和全局特征的融合,从而增强建模能力。并对卷积块与变压器块的技术集成进行了研究。
最后,为了进一步提高性能和对抗鲁棒性,我们提出了一种新的Patch Momentum Changer (PMC)数据增强技术来训练我们的模型。
Locally Feed-Forward Network
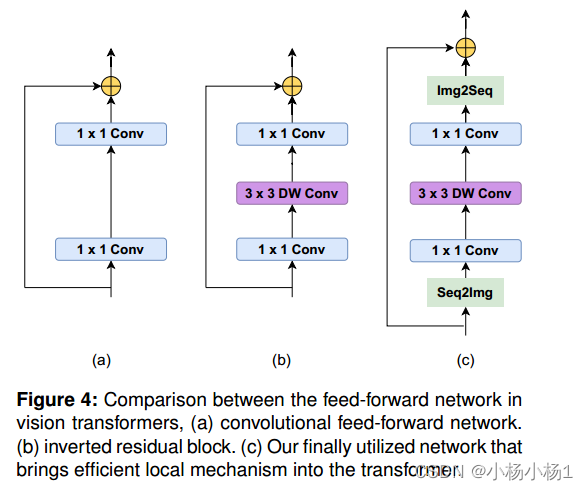
将图像特征映射转换回标记序列,然后将其转换为融合的标记,供下一个自关注层使用。
最好去看代码,模型比较简单
实验
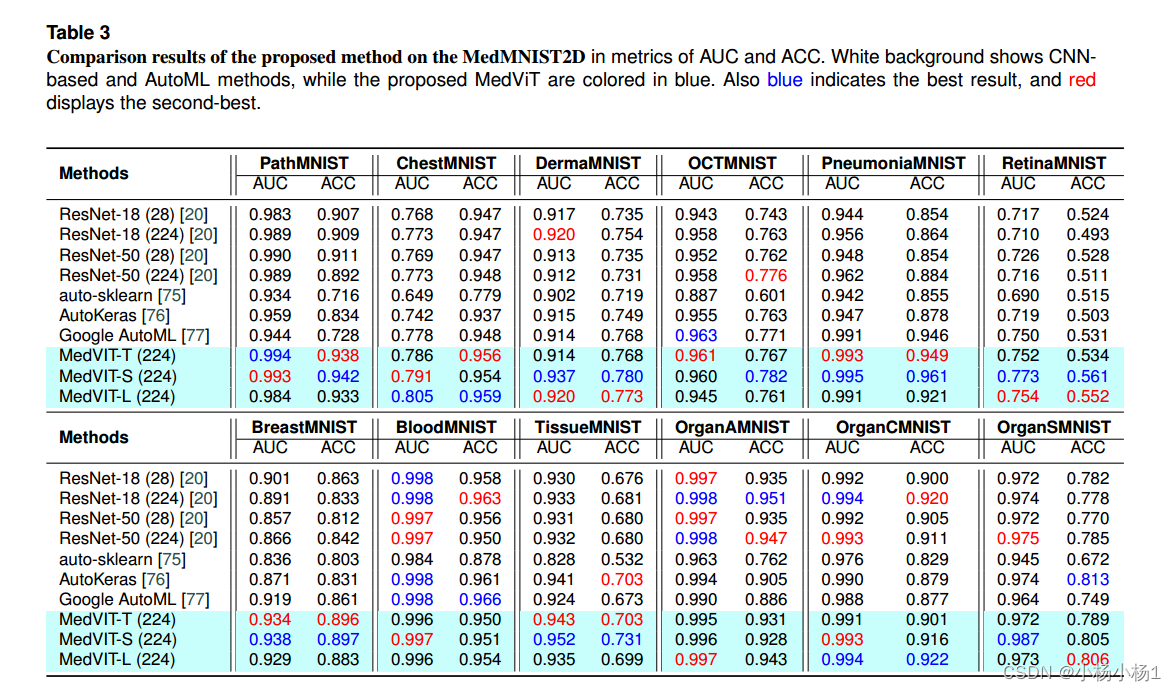
医学图像分类实验是在MedMNIST数据集上进行的,该数据集由12个标准化的数据集组成,这些数据集来自综合医学资源,涵盖了一系列医学图像代表的主要数据模式。为了做出公正客观的判断,我们遵循MedMNISTv2相同的训练设置,不做任何改变。
实验结果


















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











