







 ResMLP是一种全由多层感知器构建的图像分类架构,它采用线性层和双层前馈网络实现通道间的交互。通过数据增强和选择性蒸馏训练策略,ResMLP在ImageNet上实现了良好的精度与复杂度平衡,同时在无监督设置中也表现出色。此外,它在机器翻译任务中也取得不俗的结果。
ResMLP是一种全由多层感知器构建的图像分类架构,它采用线性层和双层前馈网络实现通道间的交互。通过数据增强和选择性蒸馏训练策略,ResMLP在ImageNet上实现了良好的精度与复杂度平衡,同时在无监督设置中也表现出色。此外,它在机器翻译任务中也取得不俗的结果。
ResMLP: Feedforward networks for image classification with data-efficient training
摘要
我们提出了ResMLP,一个完全建立在多层感知器上的图像分类体系结构。它是一个简单的残差网络,
交替使用(i)一个线性层,其中图像补丁在通道之间独立且相同地相互作用,以及(ii)一个两层前馈网络,其中通道在每个补丁之间独立相互作用。当使用大量数据增强和选择性蒸馏的现代训练策略进行训练时,它在ImageNet上获得了令人惊讶的良好精度/复杂性权衡。我们还在自监督设置中训练ResMLP模型,以进一步从使用标记数据集中去除先验。最后,通过将我们的模型应用于机器翻译,我们取得了令人惊讶的好结果
本文方法
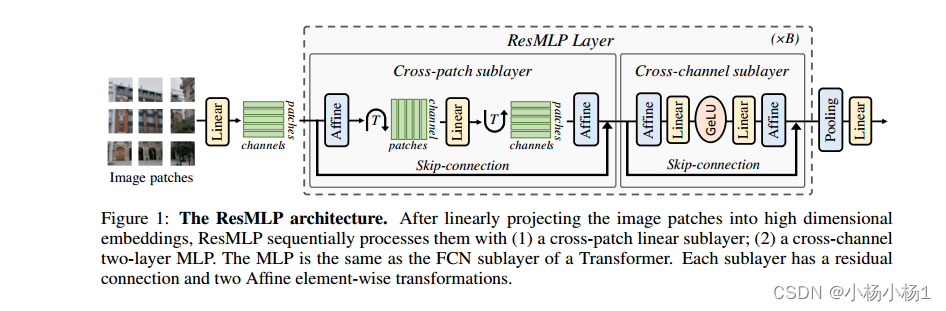
在将图像斑块线性投影到高维嵌入后,ResMLP依次使用(1)跨斑块线性子层对其进行处理;(2)跨通道双层MLP。MLP与Transformer的FCN子层相同。每个子层都有一个残余连接和两个仿射元素转换。
代码
Affine代码
class Aff(nn.Module):
def __init__(self, dim):
super().__init__()
self.alpha = nn.Parameter(torch.ones([1, 1, dim]))
self.beta = nn.Parameter(torch.zeros([1, 1, dim]))
def forward(self, x):
x = x * self.alpha + self.beta
return x
此操作仅按元素方向重新缩放和移动输入。与其他归一化操作相比,该操作有几个优点:首先,与层归一化相反,它在推理时间上没有成本,因为它可以被相邻的线性层吸收。
前向传播也和作者说的一样
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
整体过程
class MLPblock(nn.Module):
def __init__(self, dim, num_patch, mlp_dim, dropout = 0., init_values=1e-4):
super().__init__()
self.pre_affine = Aff(dim)
self.token_mix = nn.Sequential(
Rearrange('b n d -> b d n'),
nn.Linear(num_patch, num_patch),
Rearrange('b d n -> b n d'),
)
self.ff = nn.Sequential(
FeedForward(dim, mlp_dim, dropout),
)
self.post_affine = Aff(dim)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x):
x = self.pre_affine(x)
x = x + self.gamma_1 * self.token_mix(x)
x = self.post_affine(x)
x = x + self.gamma_2 * self.ff(x)
return x
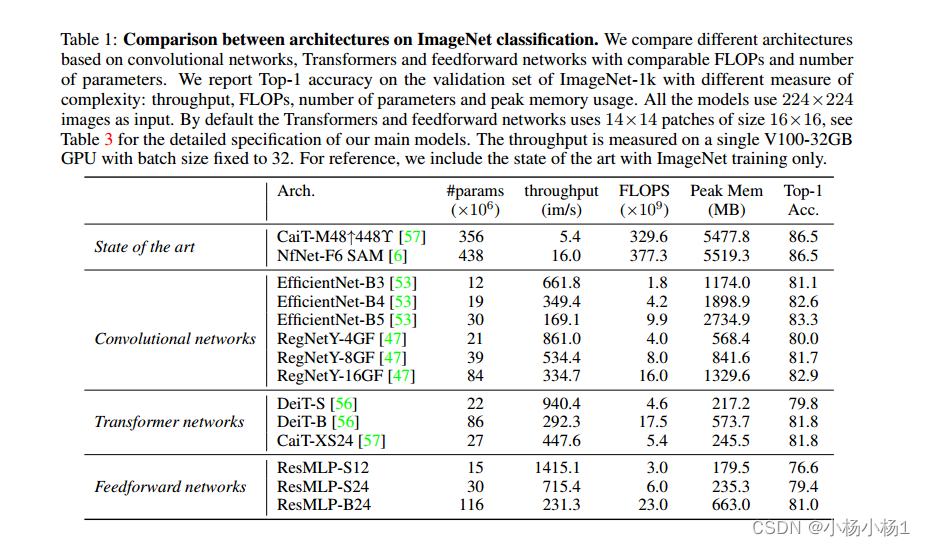
实验结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











