







目录
强化学习笔记,内容来自 刘建平老师的博客
Deep Deterministic Policy Gradient算法
随机策略 与 确定性策略
确定性策略(Deterministic Policy) 和 随机策略 是相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。
作为随机策略,在相同的策略,在同一个状态处,采用的动作是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的,即策略变成 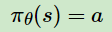
DPG 与 DDPG
从 DPG 到 DDPG 的过程,完全可以类比 DQN 到 DDQN 的过程。加入了经验回放(Experience Replay) 和 双网络,即当前网络和目标网络的概念。而由于现在本来就有Actor网络和Critic两个网络,那么双网络后就变成了4个网络,分别是:Actor当前网络,Actor目标网络,Critic当前网络,Critic目标网络。2个Actor网络的结构相同,2个Critic网络的结构相同。
深度确定性策略梯度算法DDPG概述
对比DDQN
DDQN的当前Q网络负责计算当前状态S的可执行动作Q值,然后使用ε-greedy策略选择动作A,执行动作A获得新状态S’、奖励 R,将样本放入经验池,对经验池中采样的下一状态S‘ 计算可执行动作,然后使用贪婪策略选择动作A’,供目标Q网络计算Q值,当目 标Q网络计算出目标Q值后计算Loss Function并梯度反向传播更新参数。目标Q网络负责结合当前Q网络按照Q值与动作解耦思想计 算经验池样本的目标Q值,并定期从当前Q网络更新参数。
DDPG中,Critic当前网络、Critic目标网络 和 DDQN的当前Q网络、目标Q网络的功能定位基本类似。但是DDPG有属于自己的 Actor策略网络,因此不需要ϵ−greedy策略而是用Actor当前网络选择动作A。而对经验池中采样的下一状态S′不需要用贪婪法而是由 Actor目标网络选择动作A‘。
DDPG网络功能:
1. Actor当前网络:负责策略网络参数θ的迭代更新,负责根据当前状态S选择当前动作A,用于和环境交互生成S′、R
2. Actor目标网络:负责根据经验池中采样的下一状态S′ 选择最优下一动作A′,网络参数θ′ 定期从θ复制
3. Critic当前网络:负责价值网络参数w的迭代更新,负责计算当前Q值Q(S, A, w)
4. Critic目标网络:负责计算目标Q值中的Q′(S′, A′, w′)部分,网络参数w′ 定期从w复制
网络软更新:
DDPG中,当前网络到目标网络的参数更新每次按比例更新,而不是完全复制:

其中,τ 是更新系数,一般取的比较小,比如0.1或者0.01这样的值。
引入噪声:
为了学习过程可以增加一些随机性,增加学习的覆盖,DDPG对选择出来的动作AA会增加一定的噪声N,即最终和环境交互的动作A的表达式是:
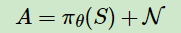
两个网络的损失函数:
1. Critic当前网络使用均方误差:
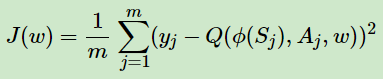
2. Actor当前网络使用的确定性策略损失函数:
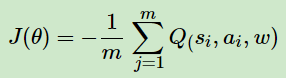
DDPG算法流程
输入:Actor当前/目标网络,Critic当前/目标网络,参数分别为θ,θ′,w,w′、衰减因子γ、软更新系数τ、批量梯度下降的样本数m、目标Q网 络参数更新频率C、最大迭代次数T、随机噪音函数N
输出:最优Actor当前网络参数θ、Critic当前网络参数w
1. 随机初始化θ、w、w′=w、θ′=θ,清空经验池 D
2. for i in [ 1, T ]:
a)初始化S为当前状态序列的第一个状态,拿到其特征向量Φ(S)
b)把状态S输入Actor当前网络得到输出动作 A = πθ(ϕ(S)) + N
c)执行动作A,由环境得到新状态S‘、奖励 R、终止标志 is_end
d)将 { ϕ(S)、A、R、ϕ(S′)、is_end } 这个五元组存入经验池 D
e)前进一步:S = S’
f)从经验池D中采样m个样本 { ϕ(Sj)、Aj、Rj、ϕ(S′j)、is_endj } ,j=1,2…m 用目标Critic网络结合公式计算当前目标Q值yj:
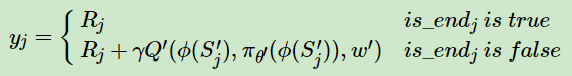
(注意:πθ′(ϕ(S′j))是通过Actor目标网络得到 )
g)用当前Critic网络计算Q估计值,求出均方误差函数,梯度反向传播更新Critic当前网络参数 w
h)使用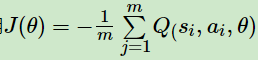 ,梯度反向传播更新Actor当前网络参数 θ
,梯度反向传播更新Actor当前网络参数 θ
i)if i % C == 0,则更新Critic目标网络和Actor目标网络参数:
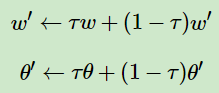
j)if S’是终止状态,break;else 跳回步骤 b
小结
DDPG参考了DDQN的算法思想,通过双网络和经验回放,加一些其他的优化,比较好的解决了Actor-Critic难收敛的问题。因此在实际产品中尤其是自动化相关的产品中用的比较多,是一个比较成熟的Actor-Critic算法。的比较多,是一个比较成熟的Actor-Critic算法。















 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









