







一 实验要求
用集成方法对数据集进行分类
-
利用若干算法,针对同一样本数据训练模型,使用投票机制,少数服从多数,用多数算法给出的结果当作最终的决策依据,对Titanic数据集 进行分类,给出在测试集上的精确度;
-
除了投票法,其他的集成学习方法也可以。
-
实验来自kaggle入门赛 https://www.kaggle.com/c/titanic ,可以参考原网站 代码与预处理部分,但与公开代码不同的在于,集成学习所用的基学习 器需要自己实现而不能调用sklearn库。
-
数据集的分析是一个开放性问题,可以参考网站中的预处理方式。
-
所选算法包括但不限于课堂上学习的模型例如: 决策树 SVM KNN 神经网络
-
需要在网站上提交,不要求结果很高,但要求模型自己实现,如果有优化可以加分
二 实验思路
主要采用bagging集成学习方法,Bagging原理可见另一篇博客(16条消息) 集成学习(ensemble learning)_Sunburst7的博客-CSDN博客。子学习器采用贝叶斯决策论进行决策,对于训练集,我们进行5次有放回的随机抽样,得到5个训练子集,然后用这五个训练子集分别进行决策,得到5个分类结果,再进行投票决定最终的分类结果。
Titanic数据字典:
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class,社会地位 | A proxy for socio-economic status (SES),1 = 1st, 2 = 2nd, 3 = 3rd |
| Name | 乘客姓名 | |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation 出发港 | C = Cherbourg, Q = Queenstown, S = Southampton |
连接训练集与测试集,查看缺失值:
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
df = pd.concat([train, test], axis=0)
df = df.set_index('PassengerId')
print(df.info())
控制台输出:
Int64Index: 1309 entries, 1 to 1309
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null float64
1 Pclass 1309 non-null int64
2 Name 1309 non-null object
3 Sex 1309 non-null object
4 Age 1046 non-null float64
5 SibSp 1309 non-null int64
6 Parch 1309 non-null int64
7 Ticket 1309 non-null object
8 Fare 1308 non-null float64
9 Cabin 295 non-null object
10 Embarked 1307 non-null object
dtypes: float64(3), int64(3), object(5)
Cabin特征因为有太多的缺失值,所以决定舍弃它,本次不进行语义分析,因此乘客姓名Name,船票编号Ticket人人各不相同,也被舍弃。
-
总体分析
Age,Pclass,Sex对于Survived的影响:import seaborn as sns sns.set_theme(font_scale=1.5) sns.displot(data=df,hue='Sex', x='Age',row='Survived',col='Pclass') plt.show()
第一行的乘客是那些没有存活下来的乘客,似乎大部分是来自
Pclass=3的男性。幸存者大多是女性(第二行)。因此,Age和Pclass是生存的重要指标,年龄则不那么重要。 -
仔细分析
Age-Survivedsns.catplot(data=df,hue='Sex', x='Kind',row='Survived',col='Pclass', kind='count') plt.show()
Pclass=1或2所有孩子都活下来了,也许这对我们有所帮助,所以我们保留Age这个特征,似乎儿童作为一个整体(年龄<=15岁以上)比成年人生存得更好。因此可以粗略的将年龄分为成年人(Age>15)与未成年人(Age<=15) -
观察出发港
Embarkedsns.catplot(data=df,hue='Sex', x='Embarked',col='Survived',kind='count') plt.show()
从Southampton 出发的男性存活得较少(也许他们是在三等舱?),但大约75%的南安普顿女性存活了下来,对于从Cherbourg出发的人来说,关系就相反了。所以Embarked也很重要。
-
Fare表示船票价格:乘客要花更多的钱才能坐头等舱,但这对他们的生存并没有太大的帮助。去除该特征
因此留下的有意义的特征属性如下:
| Variable | Definition | Key |
|---|---|---|
| survival | Survival,预测标签 | 0 = No, 1 = Yes |
| pclass | Ticket class,社会地位 | A proxy for socio-economic status (SES),1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| embarked | Port of Embarkation 出发港 | C = Cherbourg, Q = Queenstown, S = Southampton |
三 实验代码
import math
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 按照众数填充缺失值
def fillMissingColumn(dataframe: pd.DataFrame):
# 检测出有缺失值的列,返回一个Series,有缺失值的列为True,无缺失值的列为False
missing_column = dataframe.isnull().any(axis=0) # 按列检测
for index, value in missing_column.items():
if value:
print(index + " needs to fill missing values")
# 利用众数填充有缺失值的行
dataframe[index].fillna(dataframe[index].mode()[0], inplace=True) # 一定要设置inplace=True 修改内存的值
# 贝叶斯分类器,输入一个向量,输出预测标签
def classifier(x, train: pd.DataFrame):
# 分别存活的情况与没有存活的情况 0-死亡 1-存活
type0 = train[train['Survived'] == 0]
type1 = train[train['Survived'] == 1]
# 计算行数
sum_type0 = type0.count().values[0]
sum_type1 = type1.count().values[0]
# 计算先验概率
prior_0 = sum_type0/(sum_type0+sum_type1)
prior_1 = sum_type1/(sum_type0+sum_type1)
# print(str(prior_0) + " " + str(prior_1))
# 初始化分类器值(加上lnp(w))
g0 = math.log(prior_0)
g1 = math.log(prior_1)
# print(str(g0) + " " + str(g1))
# 计算所有列的似然/类条件概率密度
for column in train.columns:
if column != 'Survived':# 去除预测标签的影响
# print(column)
# 计算拉普拉斯平滑后的似然
likelihood0 = (type0[type0[column] == x[column]].count().values[0] + 1) / (sum_type0 + train[column].nunique())
likelihood1 = (type1[type1[column] == x[column]].count().values[0] + 1) / (sum_type1 + train[column].nunique())
# 取对数
ln_likelihood0 = math.log(likelihood0)
ln_likelihood1 = math.log(likelihood1)
# print("type0: likelihood: " + str(likelihood0) + " ln:" + str(ln_likelihood0))
# print("type1: likelihood: " + str(likelihood1) + " ln:" + str(ln_likelihood1))
g0 += ln_likelihood0
g1 += ln_likelihood1
# print('------------------------------------------------------------------')
# print(str(g0) + " " + str(g1))
if g0>=g1:
# 预测为无法存活
return 0
else:
return 1
# Load_Data
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
# EDA 数据预处理
df = pd.concat([train, test], axis=0)
df = df.set_index('PassengerId')
df['Age'] = df['Age'].map(lambda x:'Adult' if x >15 else 'Child')
df['Embarked'] = df['Embarked'].fillna('S')
df = df.drop(['Name', 'Ticket', 'Cabin','Fare'], axis=1)
# 填充缺失值
fillMissingColumn(df)
print(df.info())
mapper = {
'Sex':{
'male':0,
'female':1
},
'Embarked':{
'C':0,
'Q':1,
'S':2,
}
}
# 特征数字化
df.replace(mapper,inplace=True)
print(df.head())
# 分割训练集与测试集
test = df.iloc[891:1309:1,:]
train = df.iloc[0:891:1,:]
SamplesArray = []
for i in range(5):
# 有放回的随机抽样 抽样占比63%
SamplesArray.append(train.sample(frac=1,replace=True,axis=0))
# 保存分类器的分类结果
isSurvived = []
for index,row in test.iterrows():
tmp = []
# 对于每一个测试集数据,放到5个子分类器中进行分类,保存子分类器分类结果
for i in range(5):
tmp.append(classifier(row,SamplesArray[i]))
isSurvived.append(tmp)
# 投票决定最终预测
vote = []
for item in isSurvived:
SurvivedCount = str(item).count('1')
if SurvivedCount > 2:
vote.append(1)
else:
vote.append(0)
test['forecast_by_vote'] = vote
# 输出预测结果
for index,row in test.iterrows():
if row['forecast_by_vote'] == 1:
print("PassengerId: " + str(index) + ", forecast: can Survive")
else:
print("PassengerId: " + str(index) + ", forecast: can't Survive")
# 写入CSV
print('write prediction to file:submission.csv')
test['PassengerId'] = test.index
test[['PassengerId','forecast_by_vote']].to_csv('submission.csv', index=False)
四 实验结果
运行控制台截图,控制台输出每个测试乘客的预测结果,同时将结果写入到submission.csv中:

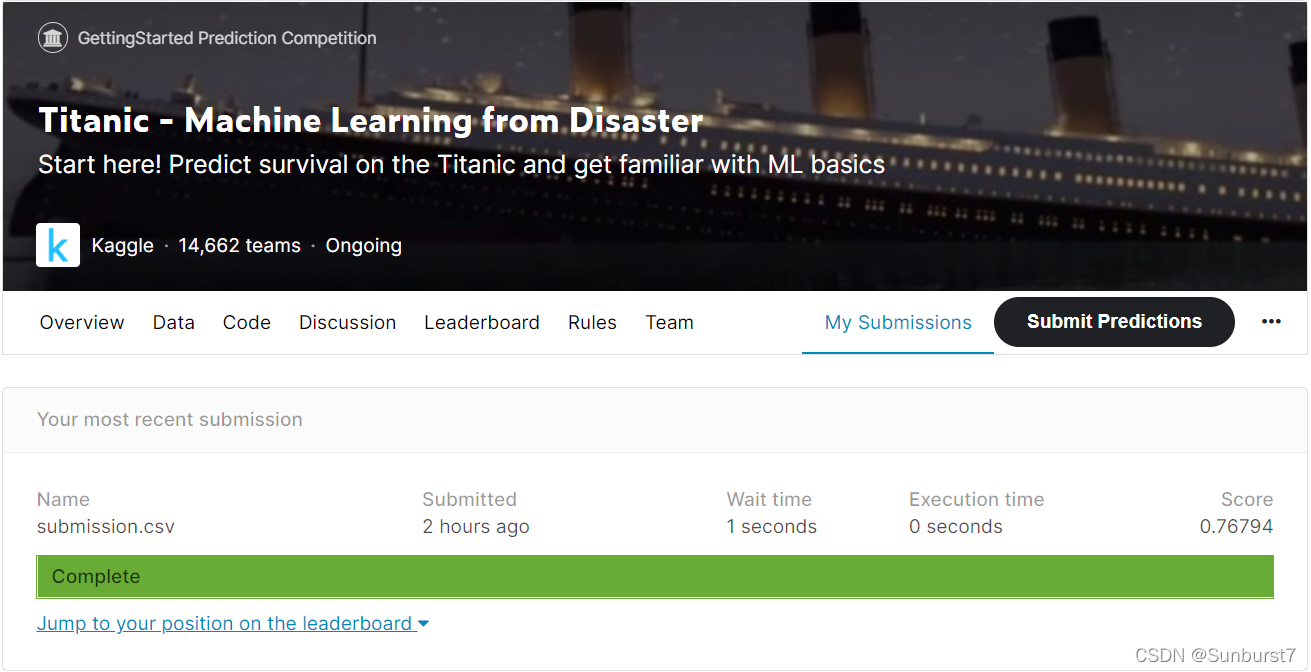
在Kaggle网站上提交,正确率为76%,嗯还有待提高:
参考
【1】https://www.kaggle.com/shlomiziskin/titanic-notebook

















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











