







本文发表于CVPR 2023
论文地址:CVPR 2023 Open Access Repository (thecvf.com)
Github官方代码地址: github.com

一、Intorduction
最近的文本到图像模型能够根据文本提示生成高质量的图像,可以覆盖广泛的物体、风格和场景。尽管这些模型具有多样的通用功能,但用户通常希望从他们自己的个人生活中综合特定的概念。例如,亲人,如家人,朋友,宠物,或个人物品和地方,如新沙发或最近参观的花园,都是有趣的概念。用户往往希望生成与个人生活紧密相关的内容,而这些通常不会出现在大规模训练数据中。
所以产生了对模型进行定制化的需求,当前个性化模型主要存在以下一些挑战:
-
遗忘问题: 微调模型时,存在着它可能会忘记或改变已有知识的风险。
-
过拟合问题: 由于训练样本的数量有限,模型可能会过拟合这些样本,并导致生成的内容缺乏多样性。
-
复合微调: 如何将多个新概念融入模型,以便可以自由组合它们,比如在图像中合成“月门”前的宠物狗。
本文提出了一种微调扩散模型的方法,自定义扩散的文本到图像的扩散模型。此方法在计算和存储效率上都进行了优化。为了克服上述挑战,我们确定了模型权重的一个小子集,即从文本到交叉注意层中潜在特征的键和值映射。微调这些就足以用新概念更新模型。为了防止模型遗忘,我们使用一小组具有相似字幕的真实的图像作为目标图像。我们还在微调过程中引入了增强,这导致了更快的收敛和更好的结果。为了注入多个概念,我们的方法支持同时训练两者,或者分别训练它们,然后合并。
二、Related Work
深度生成模型:
主流的生成模型包括GAN(生成对抗网络),VAE(变分自编码器),自回归模型,基于流量的模型和扩散模型。这些模型可以以不同类型的条件作为输入,如类别标签,图像或文本提示,以增强生成结果的可控性。
文本条件合成:
之前的研究仅局限于有限的类别。最近的模型在超大规模数据上训练,显示出了显著的泛化能力,但在对特定实例(如个人玩具或稀有类别)的生成上仍有限。
图像编辑和模型微调:
用户常常希望编辑特定的单个图像,而不是随机生成新图像。与预训练模型的表示编辑相关的挑战在于:如何通过逐图像或逐编辑优化来实现。
迁移学习:
预训练模型可以通过迁移学习适应新的数据分布,有研究专注于将模型从一个域调整到另一个域,但这常常导致原有概念的灾难性遗忘。
调整文本到图像模型的特点:
与类似的工作(如DreamBooth和Textual Inversion)相比,本研究关注在不遗忘既有概念的情况下微调模型以获取多个新概念。并且本研究只微调交叉注意层参数的一个子集,减少了微调所需时间。
我们提出了一种面对多个概念组合微调的挑战性场景的解决方案,实现了减少微调参数数量,从而加快微调过程,通过自动度量和人类偏好研究验证了所提方法的效果。
三、Method
给定一个预训练的文本到图像扩散模型,我们的目标是在模型中嵌入一个新的概念,只要给出四张图像和相应的文本描述。微调后的模型应该保留其先验知识,允许基于文本提示的新概念的新一代,这篇文章主要还是在Stable-Diffusion的基础上进行微调的,关于Stable-Diffusion这里就不过多介绍。
我们提出的模型微调方法,如下图所示,只更新模型交叉注意层中的一小部分权重。此外,我们使用一个正则化集的真实的图像,以防止过度拟合的目标概念的几个训练样本。

权重的变化率
作者通过分析目标数据集上的微调模型中每一层的参数变化,发现更新的参数主要来源于以下三类:
这些参数来自三种类型的层-(1)交叉注意(文本和图像之间),(2)自我注意(图像本身),以及(3)其余参数,包括扩散模型U-Net中的卷积块和归一化层。
正如我们所看到的,交叉注意层参数与其他参数相比具有相对较高的Δ。此外,交叉注意层仅占模型中总参数计数的5%。这表明它在微调过程中起着重要作用,我们在我们的方法中利用了这一点。

模型微调:
交叉注意块根据条件特征修改网络的潜在特征,即,在文本到图像扩散模型的情况下的文本特征。给定文本特征c和潜在图像特征f,Q=Wqf,K=Wkc,V=Wvc。
其中Wq、Wk和Wv分别将输入映射到查询、键和值特征,d是键和查询特征的输出维度。潜在特征然后用注意力块输出更新。微调的任务是更新从给定的文本到图像分布的映射,文本特征仅输入到交叉注意块中的Wk和Wv投影矩阵。因此,我们建议在微调过程中仅更新扩散模型的Wk和Wv参数。


多概念组合微调
其实实现多个概念组合微调的基本原理和单个没有太大区别。为了对多个概念进行微调,我们将每个概念的训练数据集组合起来,并使用我们的方法联合训练它们。为了表示目标概念,我们使用不同的修饰符标记V_i,用不同的罕见标记初始化,并使用每层的交叉注意键和值矩阵沿着对其进行优化。
四、Experiments
数据集: 我们在十个目标数据集上进行实验,这些数据集涵盖了各种类别和不同的训练样本。它由两个场景类别、两个宠物和六个对象组成。
评价指标:
(1)Image-alignment(图像对齐),即,使用CLIP图像特征空间中的相似性,生成的图像与目标概念的视觉相似。
(2)Text-alignment,使用CLIP特征空间中的文本-图像相似性,生成的图像与给定提示的文本对齐。
(3)KID ,用于从LAION-400 M检索的类似概念的500幅真实的图像的验证集,以测量目标概念上的过拟合(例如,在一个实施例中,V dog)和忘记现有的相关概念(例如,狗)。
(4)人类偏好研究。
与Dreambooth、Textual Inversion进行比较:
单一概念微调:

论文中提到:第一行:代表水彩画艺术风格的概念。我们的方法还可以在背景中生成山脉,DreamBooth和Textual Inversion忽略了这些山脉。第二行:改变背景场景。我们的方法和DreamBooth执行类似,比文本反转更好。第三行:添加另一个对象,例如,一张带目标桌子的橙子沙发我们的方法成功地添加了另一个对象。我们在我们的网站上展示更多的样品。
多概念微调:

论文中提到:第一行:我们的方法在遵循文本条件的同时与个人猫和椅子具有更高的视觉相似性。第二行:DreamBooth有时会忽略猫,而我们的方法会同时生成猫和木盆。第三行:我们的方法更好地保持了与目标图像的视觉相似性。第四排:目标桌子和椅子一起在花园里。
如此相比之下,相对于Dreambooth、Textual Inversion而言,论文所提出的方法是相对优异的。

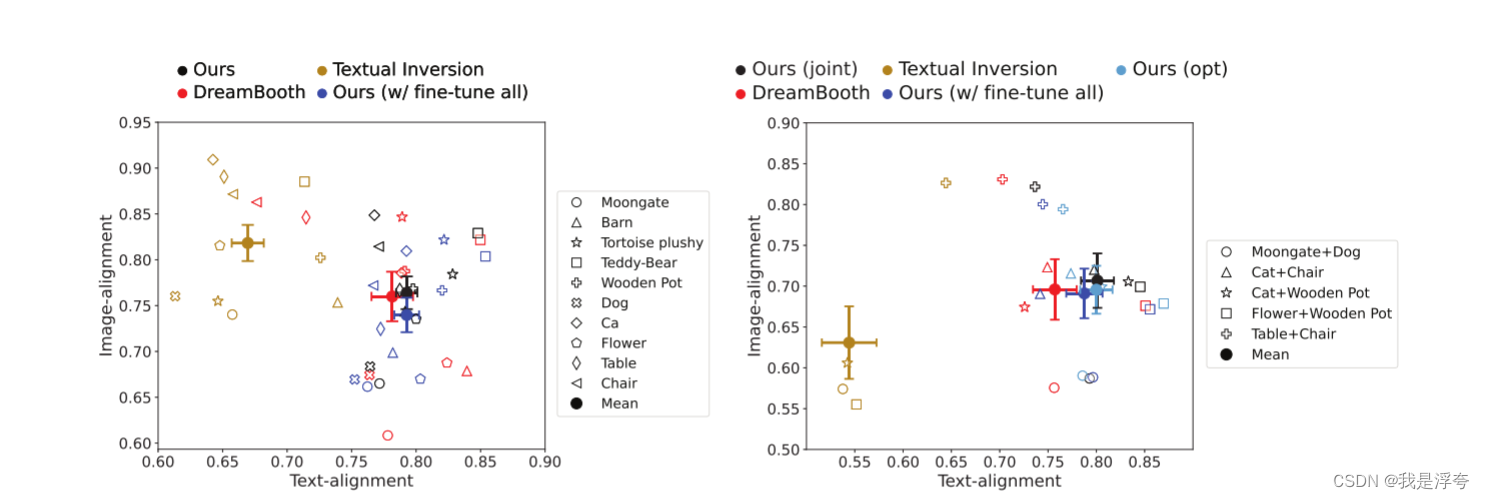
上图是基于文本和图像对齐所作的比较,左边的图是单个概念微调,右边则是多个概念的微调。与其他方法相比,论文所提的方法位于更沿着右上角(方差较小)。考虑到图像对齐与文本对齐之间的权衡,我们的方法与baselines相当或更好。
五、Discussion
这篇论文的主要创新点在于它仅仅通过改变交叉注意力层的一小部分参数(K、V)以实现个性化微调Stable-Diffuison。相对于Dreambooth微调整个模型的做法而言,无疑是大大减小了训练时间以及微调后的权重模型(3GB——75MB),并且实现了多个概念的个性化微调。
















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











